今天在部署实验室项目时,发现项目在后台运行一个晚上后内存增长了近3g。考虑到目前的数据量较小,真正部署到线上时系统很可能因为OOM而被kill掉,因此进行了长达一天的debug与问题解决。
python 内存泄露
python的垃圾回收采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略。
在分析内存泄露之前需要先了什么情况会导致内存泄露.具体内容可以参照如下几篇博客:
- 记一次面试问题——Python 垃圾回收机制
- Python垃圾回收机制详解 - Xjng - 博客园
- Python垃圾回收机制--完美讲解!_Python_LuckyQueen0928的博客-CSDN博客
检测内存泄露
接下来检测下程序中是否出现了内存泄露,pympler工具可以很容易看到内存的使用情况,用法如下
import objgraph
import schedule
from pympler import tracker, muppy, summary
tr = tracker.SummaryTracker()
def dosomething():
print "memory total"
all_objects = muppy.get_objects()
sum1 = summary.summarize(all_objects)
summary.print_(sum1)
print "memory difference"
tr.print_diff()
# ........ 爬取任务
pass
schedule.every(1).minutes.do(dosomething)
对我的程序进行分析,可以看到如下的输出结果,可以看到程序存在缓慢的内存泄露

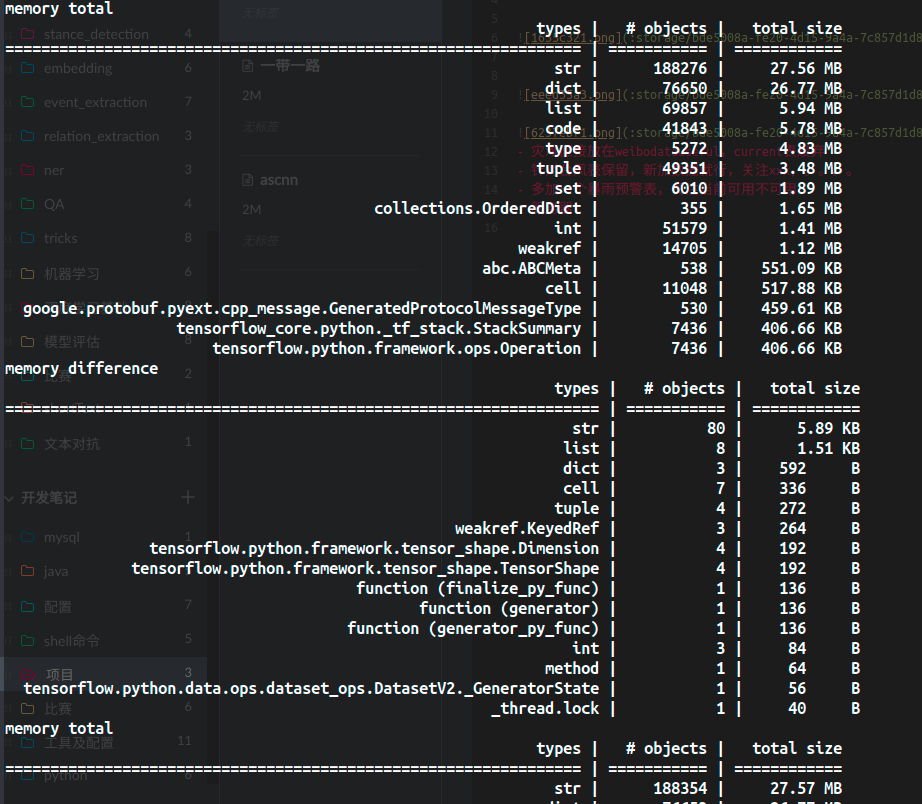
定位内存泄露位置
接下来要分析是那些对象导致内存泄露的.
相关的工具如下:
- gc: python 内置模块, 函数少功能基本, 使用简单.
- objgraph: 可以绘制对象引用图, 对于对象种类较少, 结构比较简单的程序适用.
- guppy: 可以用来打印出各种对象各占用多少空间, 如果python进程中有没有释放的对象, 造成内存占用升高, 通过guppy可以查看出来. 但仅支持python2.
- pympler: 可以统计内存里边各种类型的使用, 获取对象的大小.
下边是两个比较好用的工具,比上述的工具更为方便:
- pyrasite
pyrasite 是1个可以直接连上一个正在运行的python程序, 打开一个类似ipython的交互终端来运行命令来检查程序状态.
注: pyrasite使用之前需要在root用户下运行命令echo 0 > /proc/sys/kernel/yama/ptrace_scope后才能正常使用
pyrasite里边有一个工具叫pyrasite-memory-viewer, 功能和guppy差不多, 不过可以对内存使用统计和对象之间的引用关系进行快照保存, 很易用也很强大.运行命令为pyrasite-memory-viewer <pid> - tracemalloc
可以直接看到哪个(哪些)对象占用了最大的空间, 这些对象是谁, 调用栈是啥样的, python3直接内置, python2如果安装的话需要编译
最终我定位到问题出现在我调用的hanlp2.0,这个库用于项目中地名识别,巧的是我在hanlp2的issue里发现了相似的问题pipeline添加自定义function后, 循环使用内存溢出,luoy2用了tracemalloc 定位到tokenizer和tagger在pipline方式后循环调用出现了内存泄露的现象。如下是何博士在issue中给出的解释:
现在任务管理器中Python的内存已经涨到5个G了
fasttext可能本身就要占用几个G。是增长量达到5个G吗?
如果是的话是不是就是tf2的bug, 因为据汇报tf1.15 - 没有上述问题。
可能有关系,有人说 I'm also still facing the same issue with TensorFlow 2.1.0.,也有人说 Still facing this problem in tf-nightly-gpu 2.2.0.dev20200307不过我没有在hanlp.com的服务器上观察到内存泄露的情况。跟python代码不同,我用的是tensorflow_serving提供服务,从上线到现在没有重启过。
已确定是TensorFlow的问题,正在等TF社区回复。
尝试解决
在本地测试了如下的代码,并未生效,
del recognizer
del pipline
print(gc.garbage)
gc.collect()
gc.garbage 返回为[], 奇怪的是我虽然尝试过不使用pipline的方式, 此时使用sys.getrefcount(recognizer),返回的recognizer的引用计数为2,但gc.garbage返回仍为[]。这里关于gc回收的接口参照如下的文档
由于急着部署项目,只能先考虑备选方案。这里测试对pyhanlp,pytlp,lac进行了测试,感觉百度的lac命名实体识别功能较强。因此将项目中的地名识别模型做了替换。如下是对lac进行的泄露测试,可以看到内存泄露问题解决了。 另外惊喜的是,lac的基础模型不仅效果而且处理速度极快。

参考