写在前面的话
啥是索引?以一本书为例,如果想要找到某一指定章节的某一小节,书薄还好,如果书厚,可能就会找的头皮发麻。于是便出现了目录,让用户更容易查找到自己所需要的东西。索引就类似一张表的目录。其存在的意义就是优化查询速度,所以在学习的时候,只要一直记住这个类比,就相对更容易理解一些。
关于索引
在索引中,常见的算法有:B 树,Hash,R 树,Full text,GIS 等。只需要记两三个即可。
其中最重要的就是 B 树索引,可再度分为:B- 树,B+ 树(在 > < like 等查找中性能更优),B* 树
目前最多的就是 B+ 树,其结构可类比为树的:根(Root),枝(Internal),叶(Leaf)
树状结构如图(图片来自互联网):

在功能上面,索引可分为:辅助索引和聚集索引
辅助索引创建 B 树过程:
当用户执行创建索引操作:alter table t1 add index idx(id);
1. 提取索引列(id 列)的值,进行排序。
2. 向叶子节点申请数据页(16K),然后将排序后的值存储到叶子节点的数据页中,并和真实数据进行关联。
3. 向枝节点和根节点申请数据页,将下层中单页最小值存储进去,如此类推。
聚集索引创建 B 树过程:
聚集索引创建的前提是列为主键或者唯一键,一般为主键,如 ID 字段。
一旦表中有主键列,那么在数据写入的时候就会按照主键的顺序写到磁盘的数据页中。
聚集索引叶节点直接就是真实数据页,减少了 B 树层级。
两者的区别:
聚集索引只能一个,要求非空唯一,一般是主键。辅助索引可以配置多个。
聚集索引叶子节点直接就是真实数据页,辅助索引则是抽离出来排序后的数据。
辅助索引分类:
1. 普通的单列索引。
2. 联合索引(多列索引),用多个列建立一个索引,如:select * from t1 where a=xx and b=xx and c=xx; 这种查询。
3. 唯一索引(unique index):索引列的值都是唯一。
索引树高度影响因素:
1. 数据行数影响,解决办法:分库分表,分布式
2. 索引列值过长,解决办法:前缀索引
3. 数据类型:变长字符串使用了 char,解决办法:变长使用 varchar
管理索引
查看表的索引情况:
show index from city; -- 或者 desc city;
结果:
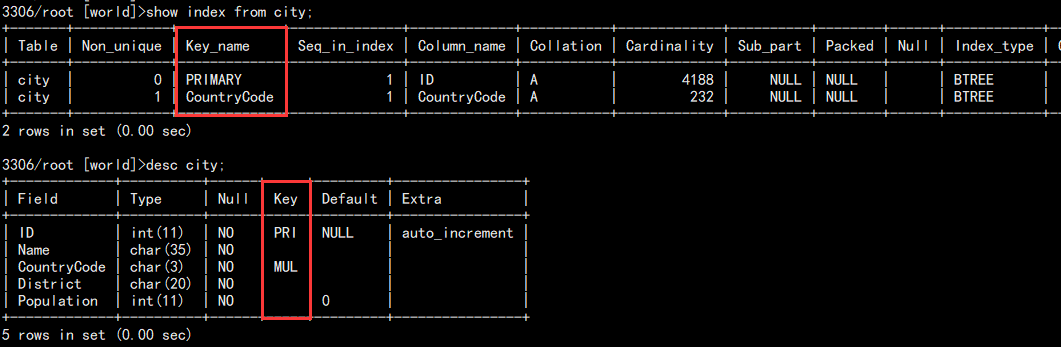
其中:PRI 是主键索引(聚集索引),UNI 是唯一索引(辅助索引),MUL 是辅助索引。
1. 创建普通索引:
alter table city add index idx_name(name);
此时查看创建情况:

注意:同一列可以创建多个索引,但是没意义。同一个表中索引名字必须唯一。
2. 删除索引:
-- 创建一个测试索引 alter table city add index idx_name1(name); -- 删除测试索引 alter table city drop index idx_name1;
3. 创建多列联合索引:
alter table city add index idx_d_p(District,Population);
此时查看:

注意:索引列的顺序可能会影响 SQL 最终是否会走该索引。
4. 创建前缀索引:
alter table city add index idx_di(District(5));
注意:前缀索引必须是字符串,不能是数字:
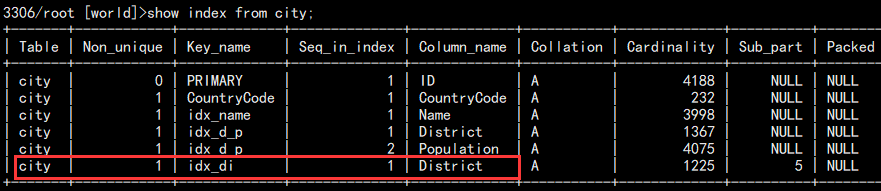
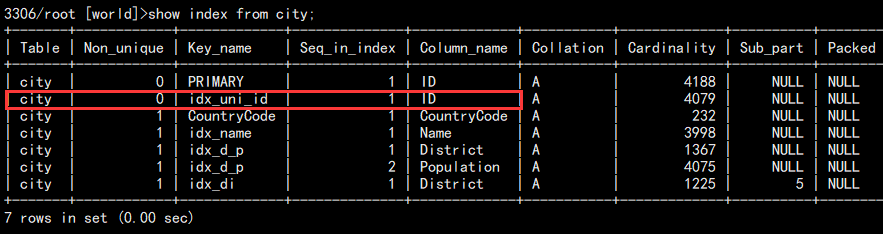
5. 创建唯一索引:
alter table city add unique index idx_uni_id(id);
查看:
查看某列的重复情况以参考是否适合做索引列:
select name,count(id) from city group by name having count(id)>1 order by count(id) desc;
查看重复次数:

压力测试:
mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='库名' --query="select * from 库名.表名 where 字段名='值'" engine=innodb --number-of-queries=2000 -uroot -p -verbose
100 个并发查询,一共查询 2000 次,没索引 100 万数据测试耗时 700s。加索引后为 0.1 秒,性能提升恐怖。
关于执行计划
执行计划的作用在于帮助分析 SQL 是否走索引以及是否走正确的的索引,进而优化业务逻辑。
以 world 库为例,先删除之前 city 表创建的索引:
查看表索引:

看看数据库优化器最终选择的执行计划:
desc select * from city where Name="Shanghai";
只需在执行的 SQL 前加 desc:

其中重要字段的含义:
possible_keys:可能会用到的索引
key:真正使用到的索引
type:索引类型
Extra:额外信息
type 字段详解:(性能逐级提升)
1. ALL:全表扫描,不走索引
a. 查询没有索引的 name 字段:
select * from city where Name="Shanghai";
b. 查询语句中辅助索引使用到:<>,not in,like '%xxx'
desc select * from city where countrycode <> "CHN"; desc select * from city where countrycode not in ("CHN","USA"); desc select * from city where countrycode like "%CH%";
如图:

但在聚集索引字段使用则会走索引,如:
desc select * from city where id <> 100;
如图:

2. INDEX:全索引扫描
a. 查询需要获取整个索引树时:
desc select countrycode from city;
如图:

b. 联合索引中,任何一个非最左列作为查询条件:
假如索引 idx_a_b_c(a,b,c) 其实相当于建立了索引:a,ab,abc。此时 a 就是最左列,此时:
select * from t1 where b=xxx;
3. RANGE:索引范围扫描
辅助索引:<,>,>=,<=,like,in,or
主键:<>,not in
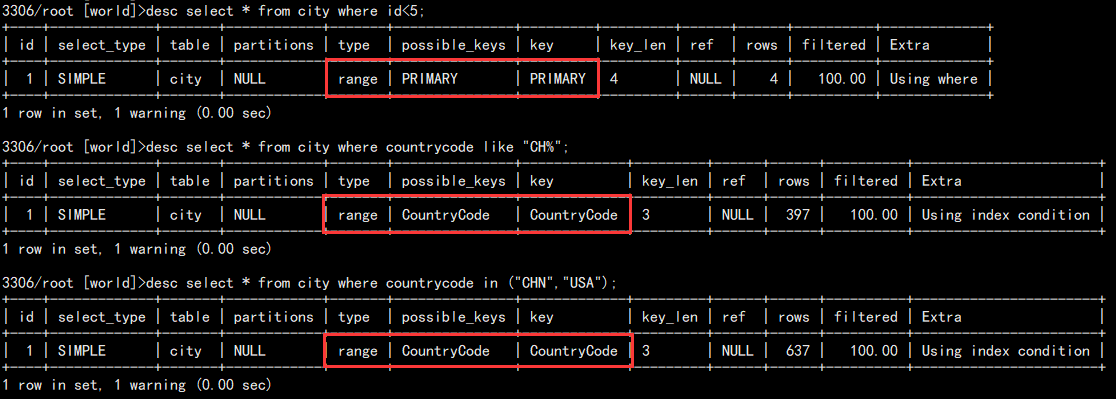
注意:前两种能享受到 B+ 树的优势,第三种 in 方法不会,为了优化可以写成:
desc select * from city where countrycode="CHN" union all select * from city where countrycode="USA";
结果:

4. ref:非唯一性索引,等值查询
desc select * from city where countrycode="CHN";
结果:

5. eq_ref:多表连接时,连接条件使用唯一索引
desc select a.name,b.name from city as a join country as b on a.countrycode=b.code where a.population<100;
结果:

6. const:唯一索引等值查询
desc select * from city where id=10;
结果:

Extra 字段说明:
desc select * from city where countrycode="CHN" order by population;
在使用排序的时候会发现,在 extra 字段出现:filesort (文件排序)

说明在使用 order by 的时是没有走索引的,之前说过,辅助索引会将索引列的值抽离出来进行排序。
但 where 条件用了索引,由此得出:在多个条件的时候,优化器只会选择其中一个索引。
解决办法:将多个条件中字段创建联合索引:
alter table city add index idx_c_p(countrycode,population); desc select * from city where countrycode="CHN" order by population;
再度查看:

同理在 group by,distinct 中也一样。
联合索引中的特殊情况:
1. select * from t1 where a=xxx and b=xxx; 这种情况下,创建索引:
alter table t1 add index idx_a_b(a,b); 和 alter table t1 add index idx_b_a(b,a); 效果一样。
where 会自动调整顺序使其满足索引需求,但创建时应将唯一值更多放在前面。
2. 如果 where 中出现不等值查询:select * from t1 where k1 > 100 and k2="aaa";
创建索引应该:alter table t1 add index idx_2_1(k2,k1);
并将语句 k2="aaa" 放前面,否则 > 在前会卡住索引,导致后面条件不走索引。
3. 如果语句中存在多个子句,则需要按照执行顺序建立索引。
线上数据库卡顿解决思路:
1. show processlist; 或者 show full processlist; 查看问题 SQL,如果暂时无法解决,可先 kill 掉。
2. 使用 desc 或者 explain 分析 SQL 走索引的情况,如果没走索引,通过分析后建立索引。
特定的时间段慢的解决思路:
可以通过后面的 slowlog 找到慢 SQL,分析语句走索引情况和耗时情况,进行修改。
建立索引的原则
1. 建表时一定要有主键,一般采用无关列。
2. 尽量选择唯一性索引,如果非要使用重复值较多的,可将表逻辑拆分,也可将此列和其他列做联合索引。
3. 为经常需要 where / order by / group by / join on 等操作的字段建立索引。
4. 索引字段很长,尽量采用前缀索引。
5. 索引不是越多越好,索引越多,越占空间,修改表越慢,可使用 percona-toolkit 的 pt-duplicate-key-checker 进行索引清理。
6. 大表加索引需避开业务高峰期。
7. 尽量避免在经常更新的列上面加索引。
不走索引的情况
1. 没有查询条件或者条件未建立索引。
2. 查询结果集是原表中大部分数据,数据超过 25%,优化器会觉得没必要走索引。可使用 limit 或存 redis 解决。
3. 索引失效,导致数据不真实。如果表经常修改,容易导致索引失效,需要删除重建解决。
4. 查询条件使用函数在索引列上面,或则对索引列进行 + - * / 计算等,如:select * from t1 where id-1=9;
5. 隐式转换导致索引失效,如号码一般是 varchar 保存全数字,通过 select * from t1 where phone=120; 或 where phone='120'; 结果一致,但前者不走索引。
6. <>,not in 是不走索引的,> < in 这些也有可能不走,后者尽量使用 union all 优化。
7. like 中 % 在前面不走索引,如 like "%HN"。
小结
本章节索引和执行计划简直是 MySQL 优化中重中之重,当然在数据库小的时候还不明显,当数据量大起来以后,质的飞跃。