ES默认分词为英文分词(使用空格来进行分词)不符合中文分词要求。例如
GET _analyze
{
"text":"我不喜欢你"
}
会得到如下分词结果


{ "tokens" : [ { "token" : "我", "start_offset" : 0, "end_offset" : 1, "type" : "<IDEOGRAPHIC>", "position" : 0 }, { "token" : "不", "start_offset" : 1, "end_offset" : 2, "type" : "<IDEOGRAPHIC>", "position" : 1 }, { "token" : "喜", "start_offset" : 2, "end_offset" : 3, "type" : "<IDEOGRAPHIC>", "position" : 2 }, { "token" : "欢", "start_offset" : 3, "end_offset" : 4, "type" : "<IDEOGRAPHIC>", "position" : 3 }, { "token" : "你", "start_offset" : 4, "end_offset" : 5, "type" : "<IDEOGRAPHIC>", "position" : 4 } ] }
在实际开发中需要安装分词器(IK),安装分词器
解压elasticsearch-analysis-ik-7.6.1
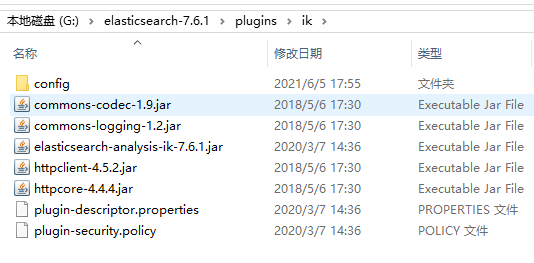
在ES目录里的plugins目录里创建ik文件夹
拷贝elasticsearch-analysis-ik-7.6.1文件里的所有内容到ik文件夹中。如图
重启ES和kibana
如果ES加载过程中如下

说明插件配置成功
再在kibana中执行如下解析
GET _analyze
{
"text":"我不喜欢你",
"analyzer": "ik_max_word"
}
输出结果
{ "tokens" : [ { "token" : "我", "start_offset" : 0, "end_offset" : 1, "type" : "CN_CHAR", "position" : 0 }, { "token" : "不喜欢", "start_offset" : 1, "end_offset" : 4, "type" : "CN_WORD", "position" : 1 }, { "token" : "喜欢", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 2 }, { "token" : "你", "start_offset" : 4, "end_offset" : 5, "type" : "CN_CHAR", "position" : 3 } ] }
自定义分词
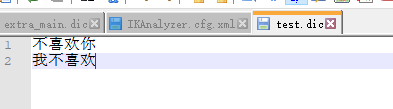
在ikconfig文件中创建test.dic文件输入如下内容
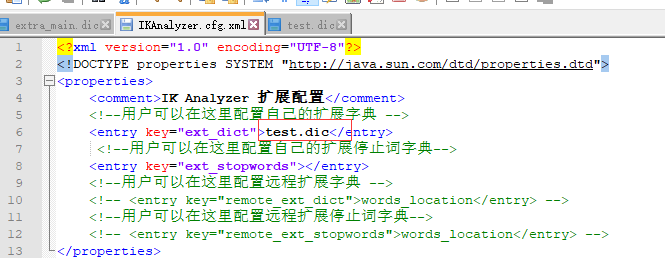
修改IKAnalyzer.cfg.xml配置文件
重启ES和kibana
执行如下语句
GET _analyze
{
"text":"我不喜欢你",
"analyzer": "ik_max_word"
}
发现分词结果会多出刚才添加的分词内容。如下
