1 /** 2 * 单词计数 3 */ 4 public class LocalTridentCount { 5 6 public static class MyBatchSpout implements IBatchSpout { 7 8 Fields fields; 9 HashMap<Long, List<List<Object>>> batches = new HashMap<Long, List<List<Object>>>(); 10 11 public MyBatchSpout(Fields fields) { 12 this.fields = fields; 13 } 14 @Override 15 public void open(Map conf, TopologyContext context) { 16 } 17 18 @Override 19 public void emitBatch(long batchId, TridentCollector collector) { 20 List<List<Object>> batch = this.batches.get(batchId); 21 if(batch == null){ 22 batch = new ArrayList<List<Object>>(); 23 Collection<File> listFiles = FileUtils.listFiles(new File("d:\stormtest"), new String[]{"txt"}, true); 24 for (File file : listFiles) { 25 List<String> readLines; 26 try { 27 readLines = FileUtils.readLines(file); 28 for (String line : readLines) { 29 batch.add(new Values(line)); 30 } 31 FileUtils.moveFile(file, new File(file.getAbsolutePath()+System.currentTimeMillis())); 32 } catch (IOException e) { 33 e.printStackTrace(); 34 } 35 36 } 37 if(batch.size()>0){ 38 this.batches.put(batchId, batch); 39 } 40 } 41 for(List<Object> list : batch){ 42 collector.emit(list); 43 } 44 } 45 46 @Override 47 public void ack(long batchId) { 48 this.batches.remove(batchId); 49 } 50 51 @Override 52 public void close() { 53 } 54 55 @Override 56 public Map getComponentConfiguration() { 57 Config conf = new Config(); 58 conf.setMaxTaskParallelism(1); 59 return conf; 60 } 61 62 @Override 63 public Fields getOutputFields() { 64 return fields; 65 } 66 67 } 68 69 /** 70 * 对一行行的数据进行切割成一个个单词 71 */ 72 public static class MySplit extends BaseFunction{ 73 74 @Override 75 public void execute(TridentTuple tuple, TridentCollector collector) { 76 String line = tuple.getStringByField("lines"); 77 String[] words = line.split(" "); 78 for (String word : words) { 79 collector.emit(new Values(word)); 80 } 81 } 82 83 } 84 85 public static class MyWordAgge extends BaseAggregator<Map<String, Integer>>{ 86 87 @Override 88 public Map<String, Integer> init(Object batchId, 89 TridentCollector collector) { 90 return new HashMap<String, Integer>(); 91 } 92 93 @Override 94 public void aggregate(Map<String, Integer> val, TridentTuple tuple, 95 TridentCollector collector) { 96 String key = tuple.getString(0); 97 /*Integer integer = val.get(key); 98 if(integer==null){ 99 integer=0; 100 } 101 integer++; 102 val.put(key, integer);*/ 103 val.put(key, MapUtils.getInteger(val, key, 0)+1); 104 } 105 106 @Override 107 public void complete(Map<String, Integer> val, 108 TridentCollector collector) { 109 collector.emit(new Values(val)); 110 } 111 112 } 113 114 /** 115 * 汇总局部的map,并且打印结果 116 * 117 */ 118 public static class MyCountPrint extends BaseFunction{ 119 120 HashMap<String, Integer> hashMap = new HashMap<String, Integer>(); 121 @Override 122 public void execute(TridentTuple tuple, TridentCollector collector) { 123 Map<String, Integer> map = (Map<String, Integer>)tuple.get(0); 124 for (Entry<String, Integer> entry : map.entrySet()) { 125 String key = entry.getKey(); 126 Integer value = entry.getValue(); 127 Integer integer = hashMap.get(key); 128 if(integer==null){ 129 integer=0; 130 } 131 hashMap.put(key, integer+value); 132 } 133 134 Utils.sleep(1000); 135 System.out.println("=================================="); 136 for (Entry<String, Integer> entry : hashMap.entrySet()) { 137 System.out.println(entry); 138 } 139 } 140 141 } 142 143 144 public static void main(String[] args) { 145 //大体流程:首先设置一个数据源MyBatchSpout,会监控指定目录下文件的变化,当发现有新文件的时候把文件中的数据取出来, 146 //然后封装到一个batch中发射出来.就会对tuple中的数据进行处理,把每个tuple中的数据都取出来,然后切割..切割成一个个的单词. 147 //单词发射出来之后,会对单词进行分组,会对一批假设有10个tuple,会对这10个tuple分完词之后的单词进行分组, 相同的单词分一块 148 //分完之后聚合 把相同的单词使用同一个聚合器聚合 然后出结果 每个单词出现多少次... 149 //进行汇总 先每一批数据局部汇总 最后全局汇总.... 150 //这个代码也不是很简单...挺多....就是使用批处理的方式. 151 152 TridentTopology tridentTopology = new TridentTopology(); 153 154 tridentTopology.newStream("spoutid", new MyBatchSpout(new Fields("lines"))) 155 .each(new Fields("lines"), new MySplit(), new Fields("word")) 156 .groupBy(new Fields("word"))//用到了分组 对一批tuple中的单词进行分组.. 157 .aggregate(new Fields("word"), new MyWordAgge(), new Fields("wwwww"))//用到了聚合 158 .each(new Fields("wwwww"), new MyCountPrint(), new Fields("")); 159 160 LocalCluster localCluster = new LocalCluster(); 161 String simpleName = TridentMeger.class.getSimpleName(); 162 localCluster.submitTopology(simpleName, new Config(), tridentTopology.build()); 163 } 164 }
指定路径下文件中的内容:
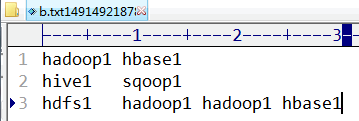
程序运行结果:
