Large-Scale Named Entity Disambiguation Based on Wikipedia Data
基于维基百科数据的大规模命名实体消岐
1.引言
1.1. 概念
实体(entity): 客观存在的事物;
表层形式(surface form): 实体的助记符号;
实体和表层形式是多对多的关系:一个表层形式可以和多个实体相关联,指代多个实体;一个实体可以有多个表层形式指代它
1.2. 实体标识的目标
把表层形式映射到实体,并标注实体的类型(人名、地名、组织名等)。当文档数量越来越多的时候,表层形式的语义歧义问题越来越突出。
如:Texas在维基百科中指代超过20个实体。在百度百科中,一个人名也对应多个人。
1.3. 前人的工作
实体标识的重要性:略。
前人的工作:简单举两个。
Bagga Baldwin(1998)解决跨文档的共指关系。
问题描述:不同文档的两个同名实体是否指代相同的事物
解决方案:统计各个文档中所有出现这个同名实体句子的词向量,然后计算向量的余弦值。
Ravin和Kazi用Nominator来解决夸文档的共指关系。Nominator是第一个成功解决实体识别和共指关系消解的系统。(没有看这个系统)
2. 系统介绍
2.1. 任务描述
给定一个实体的表层形式,给表层形式分配一个实体(用唯一名称或者id表示)。
这个任务类似于词义消解(word sense disambiguation, WSD),为文章中的多义词分配正确的意思。
2.2. 消岐方法
一句话总结:用一个庞大的实体列表和广泛的世界知识来做命名实体消岐。
分为2个子任务:
1)如何得到实体列表和世界知识;
2)如何运用这些数据
2.2.1. 需要在维基百科中得到的知识:
a) 已知的实体(entity)
b) 实体的类别(如果可用,人名、地名、组织名等)(entity class)
c) 实体已知的表层形式(surface form)
d) 上下文证据(contextual evidence)
e) 类别标记(category tag)
2.2.2. 如何得到上的说的5种数据
a) 英文维基百科页面可以分成4类
i) 实体页面(entity page)
罗列单个实体的描述信息(最多)
例子:http://en.wikipedia.org/wiki/Texas_(TV_series)
ii) 重定向页面(redirecting page)
一个实体有多种名称,或者某些页面已经废弃不用,来指向其他表示他们的页面
例子:http://en.wikipedia.org/wiki/Another_World_in_Texas
iii) 消岐页面(disambiguation page)
一个实体有多种名称,消岐页面列出名称可能表示的所有实体
例子:http://en.wikipedia.org/wiki/Texas_(disambiguation)
iv) 列表页面(list page)
聚集相同类型的实体
例子:http://en.wikipedia.org/wiki/List_of_band_name_etymologies
b) 抽取的内容:
i) 得到表层形式到实体的映射(surface form mapping to entity)
实体页面和重定向页面的title,和这些title去除同位语的形式
消岐页面:指向其他实体页面的超链接,是被指实体的表层形式
实体页面的正文中,指向其他实体页面的超链接是被指实体的表层形式。
http://en.wikipedia.org/wiki/Pam_Long
ii) 得到类别标记(category information)
列表页面的title是所有本页面的类别标记
实体页面中包含的类别标记
页面段落title
iii) 得到上下文(context)
实体页面
其他指向该实体页面的实体(互为上下文)
2.2.3.如何运用
a) 文档分析
把文档切分成句子;
判断句首单词是否是实体的一部分,如果不是首字母小写
把title中的非实体单词的大写字母化为小写
使用统计方法识别实体,判别实体边界
把一篇文章中的所有相同的表层形式分配一个类别(人名、地名、组织名、其他)
消除结构歧义(连接性歧义、所有格歧义、介词前置歧义)。
把短的表层形式转化为长的表层形。
b) 消岐组件
消岐处理使用向量空间模型。把分析文档得到的向量表示和实体页面的向量表示做比较。
令C={c1,…,cM}为维基页面中已知的上下文集合,T={t1,…,tN}是已知的类别标签的集合。一个实体可以用一个向量δe={0,1}M+N表示,δe由两部分组成δe|c∈{0,1}M,δe|t∈{0,1}N。
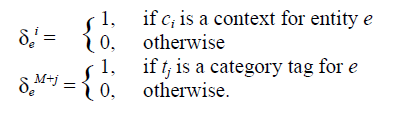
令ε(s)代表具有表层形式s的实体集合。D为文档,S(D)={s1,…,sn}是在文档D中标识的表层形式集合。我们建立文档的上下文向量d={d1,…,dm}∈NM,其中di是上下文ci出现的次数。建立扩增向量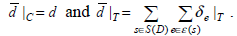
。
目标是为表层形式分配实体。si|->ei,i=1,…,n。使实体的上下文和文档的上下文具有一致性,并且对文档中每对分配的实体的类别标记具有一致性。下面是公式:
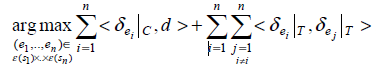
注意:为一个表层形式分配的实体取决于其他被分配的所有实体,这样来说是一个复杂度很高、很困难的优化任务。另一个方案是考虑文档中所有表层形式的所有可能实体的类别标记。公式如下

上面公式可以重写为
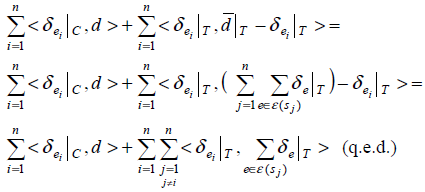
与开始的公式相等。
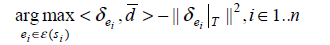
因此,消岐分为两个步骤:
(1) 建立扩增文档向量
(2) 最大化上面公式
注意的是:并不对笛卡尔积做归一化处理(也就是不是计算余弦值)