
一、列表、元组操作
列表是我们以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储、修改等操作。
定义列表
names=['lv','shi','hai','ll']
结果:通过下标访问列表中的元素,下标从0开始计数
print(names[1])

切片:取多个元素
names=['lv','shi','hai','ll']
print(names[1:3]) #取下标1至下标3之间的数字,包括1但不包括3
print(names[-1]) #取最后一个值
print(names[-2:]) #取最后两个值
print(names[:3])#取前三个值
步长切片:
names=['1lv','#shi','Hai',['hh','kk'],'ll','fadfa']
print(names[0:-1:2])#隔两个取值
print(names[::2]) #0和-1都可以省略

追加:
names=['lv','shi','hai','ll']
names.append('ls')

插入:
names=['lv','shi','hai','ll']
names.insert(2,'li') #数字代表下标,不能批量插入

修改:
names=['lv','shi','hai','ll']
names[2]='liu' #把li改为liu,
print(names)

删除:
方法一:
names=['lv','shi','hai','ll']
names.remove('lv')#删除lv
print(names)
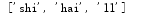
方法二:
names=['lv','shi','hai','ll']
del names[0] #删除lv,方法二
print(names)
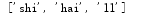
方法三:
names=['lv','shi','hai','ll']
names.pop() #默认不输入下标,删除最后一个值,输入下标后跟del用法一样
print(names)
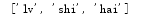
获取下标:
names=['lv','shi','hai','ll']
print(names)
print(names.index('shi'))

names=['lv','shi','hai','ll']
print(names)
print(names[names.index('shi')])
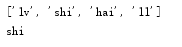
统计:
names=['lv','shi','hai','ll']print(names.count('lv'))
print(names)
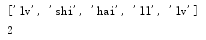
反转:
names=['lv','shi','hai','ll']
print(names)
names.reverse()
print(names)
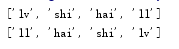
排序:
names=['lv','shi','hai','ll']
print(names)
names.sort()
print(names)
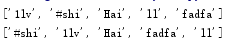
扩展:
names=['lv','shi','hai','ll']
print(names)
names2=[1,2,3,4]
names.extend(names2)
print(names,names2)

拷贝:
names=['1lv','#shi','Hai','ll','fadfa']
names2=names.copy()
print(names)
print(names2)
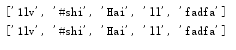
浅copy:
names=['1lv','#shi','Hai',['hh','kk'],'ll','fadfa']
names2=names.copy()
names[2]='海'
names[3][0]='HH'
print(names)
print(names2)
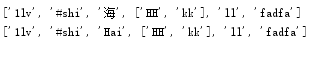
import copy
names=['1lv','#shi','Hai',['hh','kk'],'ll','fadfa']
names2=copy.copy(names)#浅复制
names[2]='海'
names[3][0]='HH'#浅复制
print(names)
print(names2)
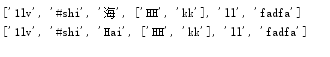
深copy:
import copy
names=['1lv','#shi','Hai',['hh','kk'],'ll','fadfa']
names2=copy.deepcopy(names)#深copy
names[2]='海'
names[3][0]='HH'
print(names)
print(names2)
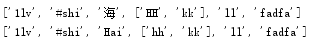
列表循环:
names=['1lv','#shi','Hai',['hh','kk'],'ll','fadfa']
for i in names:
print(i)

元组
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表
语法
|
1
|
names = ("alex","jack","eric") |
它只有2个方法,一个是count,一个是index,完毕。
names = ('lv','shi')
print(names.count('lv'))
names = ('lv','shi')
print(names.index('lv'))
程序练习
程序:购物车程序
需求:
- 启动程序后,让用户输入工资,然后打印商品列表
- 允许用户根据商品编号购买商品
- 用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒
- 可随时退出,退出时,打印已购买商品和余额
源代码如下:

product_list = [('Iphone',5800),('Mac pro',9800),('Bike',800),('Watch',1000),('Book',58)]
shopping_list = []
salary = input("Input your salary:")
if salary.isdigit(): #判断工资是否为数字 isdigtit判断是否为数字
salary = int(salary)
while True:
# for item in product_list:
# print(product_list.index(item),item) #通过获取下标的方式来获取商品编号
for index,item in enumerate(product_list): #通过获取下标的方式来获取商品编号 enumerate表示取出列表的下标
print(index,item)
user_choice = input("请选择要买的物品:")
if user_choice.isdigit():
user_choice = int(user_choice)
if user_choice < len(product_list) and user_choice >=0: #len 表示判断列表长度
p_item = product_list[user_choice] #获取产品
if p_item[1] <= salary: #买得起 p_item[1]表示商品价格
shopping_list.append(p_item) #添加到购物车
salary -= p_item[1] #扣钱
print("增加 %s 到购物车,您的余额是:�33[31;1m%s�33[0m"%(p_item,salary) ) #�33[31;1m%s�33[0m 将%s变色
else:
print("�33[41;1m您的余额只剩[%s]啦,还买个毛线啊!�33[0m"% salary)
else:
print("�33[31;1m商品不存在!!!�33[0m")
elif user_choice == 'q':
print('-------shopping list-------')
for p in shopping_list:
print(p)
print("您的余额为:�33[21;1m%s�33[0m"%salary)
exit()
else:
print("�33[31;1m错误!!!�33[0m")
else:
print("�33[31;1m请输入正确的工资!�33[0m")
字符串操作
name = "my name is shihai"
print(name.capitalize()) #首字母大写
print(name.count("i")) #统计
print(name.center(50,"_"))# 把name放中间,并打印50个字符
print(name.endswith("ai"))#判断字符串以什么结尾
print(name.expandtabs(tabsize=30))#转成空格 跟name里的 结合使用
print(name.find("hai"))#查找hai并返回下标
name = "my name is {name} and i am {year} old"
print(name.format(name='lv',year=25))#格式化
print(name.format_map({'name':'lv','year':12})) #format_map 里边是字典
print('ab23'.isalnum())#包含a到z 和所有的阿拉伯数字
print('addA'.isalpha())#纯英文字母
print('122'.isdecimal())#十进制
print('1A'.isdigit())#整数
print('1 中文'.isidentifier())#判断是不是一个合法的标识符(变量名)
print('33.3'.isnumeric())#判断是不是数字
print('33A'.isspace())#是不是空格
print('33A'.istitle())#是不是标题
print('33A'.isprintable())#是不是打印 tty文件 drive文件不能打印
print('33A'.isupper())#是不是大写
print(','.join(['1','2','3','4']))
print(name.ljust(50,'*'))#长度为50,不足的用*补全
print(name.rjust(50,'_'))#同上
print('Aaadfs'.lower())#大写变小写
print('Aaadfs'.upper())#小写变大写
print(' Aaadfs'.lstrip())#从左边去掉空格或回车
print('Aaadfs '.rstrip())#从右边去掉空格或回车
print(' Aaadf '.strip())#去掉空格或回车
p = str.maketrans("abcdefli",'1234#$56')#将前边的字符串与后边的字符串一一对应 可以用来生成随机密码
print("alex li".translate(p))#结果为15#x 56
print('lvshh'.replace('h','H',1))#替换,如果有多个就在后边加上相对应的数字
print('lv shi hai'.rfind('i'))#从左往右找,找到最右边的字符的下标
print('1+2+3+4'.split('+'))#把字符串按括号内的字符分割成一个列表
print('1+2 +3+4'.splitlines())#按换行来分割成列表
print('Lv shi Hai'.swapcase())#把大写转换成小写,小写转换成大写
print('Lv shi Hai'.title())#每个开头的字母大写
print('Lv shi Hai'.zfill(50))#指定宽度,不够的用0填充
字典的使用
字典一种key - value (键-值)的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。
语法:
info = {
'stu1101': "ll",
'stu1102': "xiaoming",
'stu1103': "wangli",
}
print(info)
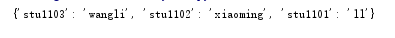
字典的特性:
dict是无序的,字典是不需要下标的;
key必须是唯一的,so 天生去重;
实例:
info = {
'stu1101': "ll",
'stu1102': "xiaoming",
'stu1103': "wangli",
}
b = {
'stu1101': "lv",
1:3,
2:5
}
info.update(b)#将两个字典合并,中间有交叉的key就合并覆盖,没有交叉就创建
print(info)
c = dict.fromkeys([6,7,8],[1,{"name":"lv"},444])#初始化新的字典
print(c)
c[7][1]['name'] = "li"
print(c)
print(info.items())#把字典转换成列表
print(info["stu1101"])
info["stu1101"]="丽丽"#修改数据
info["stu1104"]="丽丽"#增加数据
# del 删除
del info["stu1104"]
# info.pop 标准删除
info.pop("stu1104")
info.popitem()#随机删
print(info.get("stu1104"))#查找,有就输出,没有就打印出none
print(info.get("stu1103"))
print("stu1101" in info)#info.has_key("1103") python2中的用法
#多级字典嵌套及操作
av_catalog = {
"欧美":{
"www.youporn.com": ["很多免费的,世界最大的","质量一般"],
"www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"],
"letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"],
"x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"]
},
"日韩":{
"tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]
},
"大陆":{
"1024":["全部免费,真好,好人一生平安","服务器在国外,慢"]
}
}
av_catalog["大陆"]["1024"][1] += ",可以用爬虫爬下来"
av_catalog.setdefault("大陆",{"www.baidu.com":[1,2]})#先在字典里取值,如果能取到就返回,不能取到就创建新的
print(av_catalog)
#ouput
['全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']
#字典的循环
info = {
'stu1101': "ll",
'stu1102': "xiaoming",
'stu1103': "wangli",
}
for i in info: #最基本的循环,比下边的循环方式要高效
print(i,info[i])
for k,v in info.items():
print(k,v)
三级菜单:
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">