链接:https://www.zhihu.com/question/26408259/answer/123230350
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2017年06月05日更新,最近重写了一遍代码,Flappy Bird Q-learning。你可以在这里试着训练一下,加到最大帧数,在一两分钟内就可以达到10+的分数。
原答案:
最近看到了一个回答。答主用汇编语言写了一个flappy bird并在其之上加了一个Q-learning的算法让小鸟自己学习怎么飞。
程序员们有些什么好玩儿的程序分享? - 岳大禹的回答我觉得挺有趣的,就研究了一下。答主的汇编项目没有仔细看(因为不懂汇编语言),不过看了他提到的JavaScript项目(Flappy Bird hack using Reinforcement Learning),并且尝试自己照着实现了一下,效果还不错。
看到这道题题主希望用简单的例子介绍Q-learning,于是就想通过小鸟的例子,介绍一下Q-learning的过程。
问题分析
让小鸟学习怎么飞是一个强化学习(reinforcement learning)的过程,强化学习中有状态(state)、动作(action)、奖赏(reward)这三个要素。智能体(Agent,在这里就是指我们聪明的小鸟)需要根据当前状态来采取动作,获得相应的奖赏之后,再去改进这些动作,使得下次再到相同状态时,智能体能做出更优的动作。
状态的选择 在这个问题中,状态的提取方式可以有很多种:比如说取整个游戏画面做图像处理啊,或是根据小鸟的高度和管子的距离啊。在这里选用的是跟SarvagyaVaish项目相同的状态提取方式,即取小鸟到下一根下侧管子的水平距离和垂直距离差作为小鸟的状态:


(图片来自Flappy Bird RL by SarvagyaVaish)
记这个状态为,
为水平距离,
为垂直距离。
动作的选择 小鸟只有两种动作可选:1.向上飞一下,2.什么都不做。
奖赏的选择 这里采用的方式是:小鸟活着时,每一帧给予1的奖赏;若死亡,则给予-1000的奖赏;若成功经过一个水管,则给予50的奖赏。
关于Q
提到Q-learning,我们需要先了解Q的含义。
Q为动作效用函数(action-utility function),用于评价在特定状态下采取某个动作的优劣,可以将之理解为智能体(Agent,我们聪明的小鸟)的大脑。我们可以把Q当做是一张表。表中的每一行是一个状态,每一列(这个问题中共有两列)表示一个动作(飞与不飞)。
例如:
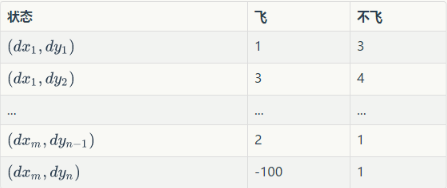
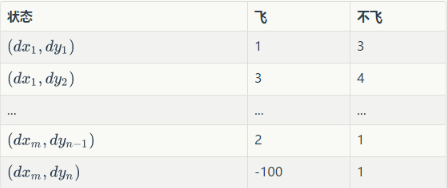
这张表一共 行,表示
个状态,每个状态所对应的动作都有一个效用值。训练之后的小鸟在某个位置处飞与不飞的决策就是通过这张表确定的。小鸟会先去根据当前所在位置查找到对应的行,然后再比较两列的值(飞与不飞)的大小,选择值较大的动作作为当前帧的动作。
训练
那么这个Q是怎么训练得来的呢,贴一段伪代码。
Initialize Q arbitrarily //随机初始化Q值
Repeat (for each episode): //每一次游戏,从小鸟出生到死亡是一个episode
Initialize S //小鸟刚开始飞,S为初始位置的状态
Repeat (for each step of episode):
根据当前Q和位置S,使用一种策略,得到动作A //这个策略可以是ε-greedy等
做了动作A,小鸟到达新的位置S',并获得奖励R //奖励可以是1,50或者-1000
Q(S,A) ← (1-α)*Q(S,A) + α*[R + γ*maxQ(S',a)] //在Q中更新S
S ← S'
until S is terminal //即到小鸟死亡为止
其中有两个值得注意的地方
1.“根据当前Q和位置S,使用一种策略,得到动作A,这个策略可以是ε-greedy等。”
这里便是题主所疑惑的问题,如何在探索与经验之间平衡?假如我们的小鸟在训练过程中,每次都采取当前状态效用值最大的动作,那会不会有更好的选择一直没有被探索到?小鸟一直会被桎梏在以往的经验之中。而假若小鸟在这里每次随机选取一个动作,会不会因为探索了太多无用的状态而导致收敛缓慢?
于是就有人提出了ε-greedy方法,即每个状态有ε的概率进行探索(即随机选取飞或不飞),而剩下的1-ε的概率则进行开发(选取当前状态下效用值较大的那个动作)。ε一般取值较小,0.01即可。当然除了ε-greedy方法还有一些效果更好的方法,不过可能复杂很多。
以此也可以看出,Q-learning并非每次迭代都沿当前Q值最高的路径前进。
2.
这个就是Q-learning的训练公式了。其中α为学习速率(learning rate),γ为折扣因子(discount factor)。根据公式可以看出,学习速率α越大,保留之前训练的效果就越少。折扣因子γ越大,所起到的作用就越大。但
指什么呢?
小鸟在对状态进行更新时,会考虑到眼前利益(R),和记忆中的利益()。
指的便是记忆中的利益。它是指小鸟记忆里下一个状态
的动作中效用值的最大值。如果小鸟之前在下一个状态
的某个动作上吃过甜头(选择了某个动作之后获得了50的奖赏),那么它就更希望提早地得知这个消息,以便下回在状态
可以通过选择正确的动作继续进入这个吃甜头的状态
。
可以看出,γ越大,小鸟就会越重视以往经验,越小,小鸟只重视眼前利益(R)。
根据上面的伪代码,就可以写出Q-learning的代码了。
成果


训练后的小鸟一直挂在那里可以飞到几千分~
链接:https://www.zhihu.com/question/26408259/answer/389938864
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
机器学习的三个框架监督学习 , 无监督学习, 强化学习, 唯强化学习最难理解 。 如果说监督学习是感知和预测(Perception & Prediction), 强化学习就是决策,它赋予机器以动机和计划的能力,同时你也可以它身上学习你改怎么决策!

 关键时刻,知道前面有老虎还是会被吃,你得会跑! 后者就是强化学习
关键时刻,知道前面有老虎还是会被吃,你得会跑! 后者就是强化学习
阿尔法元用到的框架是深度强化学习,在那里深度学习其实只是起到提取特征的作用,而背后的核心框架正是强化学习的一套基本功。
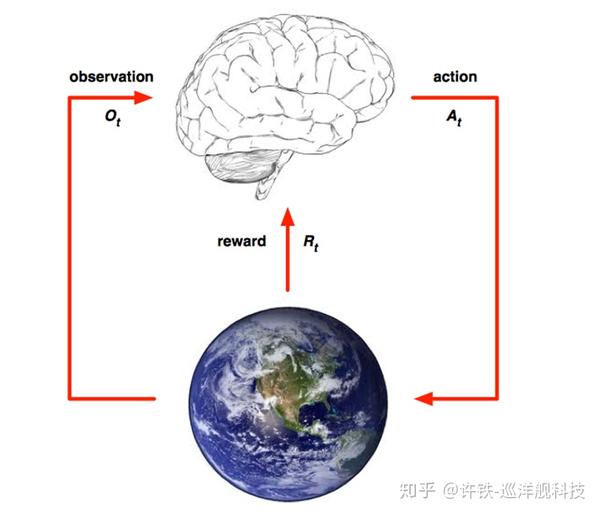
 任何强化学习都包含几个基本部分,状态, 行为, 和奖励
任何强化学习都包含几个基本部分,状态, 行为, 和奖励
铁哥在这里通过一个简单的例子给大家讲一下这个通向强人工智能最有可能的路径。
首先, 强化学习比监督学习难很多, 因为监督学习, 随时有一个老师在那里告诉你怎么是对,怎么是错,错了多少。 而强化学习, 只有游戏结束曲终人散的时候, 得到一个奖励, 或者惩罚, 然而, 你怎么都回想不清楚你究竟哪一步对, 哪一步错误, 可谓是急死老师傅。

 没有老师了这回!
没有老师了这回!
而且, 你更加直接的面对不确定性, 这种残酷的感觉,就是你需要预测的是n多步以后的时候, 那不确定性累加起来, 可以哭倒长城了。
不过, 这才是真实的人生, 走出的步子永远不知道上帝给你什么 ,而且, 不是不报,时候未到, 虽然你不知道什么时候到,只能哀叹一声, 苍天绕过谁啊。
这个问题, 术语叫做sparse, 也就是说可以用于当下决策的有关最终奖励的信号太弱太弱了。 如何解决这个问题? 有个词,叫“趋势” , 你需要从历史的经验里, 得到一个对未来趋势的判断,然后赋予此刻每个可能的行动一个值, 因为总有某个行动, 比其它的更容易导致良好的趋势, 哪怕优势只是一点点, 我们这样一步步走出, 总会得到一个帕累托最优吧 。 然后呢 ,假设你有无穷的生命, 你通过每一轮游戏的经历得到的信息不停迭代这个趋势。
这就是强化学习的最简单的方法 所谓Q 学习(Q- learning)方法。 它自然的包含了两个部分, 一个是通过经历不停的强化对某个状态行为下趋势的认知 ,另一个则是根据这个趋势,每步走出当下最优的选择(这不就是理性人决策吗!)。
我们再学究一点, 探究一下这个趋势的数学含义, 其实数学家的角度, 所谓的Q, 就是在当下选择之下未来收益的期望, 瞧,一句话把趋势是什么, 问题里的不确定性都囊括了。


我们再来从人类认知角度看这个问题, 人脑学习如何决策的原理其实是类似的, 你决策的依据, 也是未来的趋势。
一向自由洒脱的小明问了, 我哪有那么理性? 我平时的生活从没有思考过什么趋势,更不要说什么未来收益的期望, 我就是根据我的性情决策的。
只是小明没有意识到。 虽然人都生活在情绪而不是理性之中,但情绪亦是一种一种朴拙的生存理性,正是某种藏在你基因(祖先的经历)或者过往经历中的Q - value,使你你冥冥中觉得大势不妙而产生了恐惧,反之则是欣喜。 这里印证了当下的某种经历与你祖先的某一次窘境的一致性,比如你祖宗在水边看到的一条蛇, 引起了你对水杯中蛇影的恐惧。
你看到美女的兴奋是因为它预示了一种未来子孙满堂的丰盛(基因所致), 这来自于你赶地铁的焦虑是它预示了一系列的停薪考试挂科的衰微(经历所致)。 情绪,使你在一秒钟内能够决策。 那些缺少情绪而只有理性的人, 通常无法在日常生活中正常决策。 未来虽然是不确定的, 但是你的喜怒哀乐还是让你做出大致适合生存的选择。 甚至更神奇的,你有时候不必经历后果, 就可以通过你的情绪反应学习,比如某次开车太快差点被撞,这种恐惧和后怕可以让你学到开慢点,而不是等撞死了再说(TD learning)。
这个Q - learning 方法 , 就是赋予机器以“情绪” 智能, 来克服这个缺乏“ 监督信号”问题的。
你要给一个行为所能导致的所有未来趋势赋值,你就要面对一个问题, 即使此刻你做了一个决定, 你的行动导致的下一个状态你又需要决策,每个决策又导致不同的结果, 这样始终都是处于不确定的状态。
为了简化这个问题, Q - learning做了一个大刀阔斧的假设, 就是我现在做个决策, 后面的决定也都是按照某个最优的法则走的(选择当时的可选行动力最优的), 这样我忽略那些基于此刻行动导致的下个状态下那些不太好的选择 ,而是只考虑那时候最优选择的回报,这也就给出了一个很自洽的解。 也就是说, 此处行动导致的趋势, 就是未来可能回到的最大值,瞧, 一句话就把这个不确定难题搞定了, 我们基于此把趋势这个模糊的东西量化。
另外一个难点是什么呢? 下一步就得到的回报没有人会把它和未来十年的回报等同视之, 也就是说,你要以某种方式对不同时刻到来的奖励加权, 这有点像银行的贴现,未来那虚无缥缈的金银宝藏,还是好好乘个贴现因子,说不定乘出来还不如此刻的一个蛋糕。 这个原理被藏在一个叫bellaman equation的方程里。
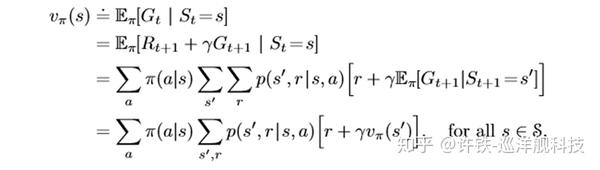
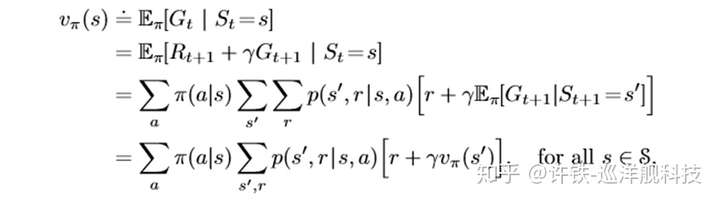 一个用迭代方法写出的数学表达, 不能再优美。
一个用迭代方法写出的数学表达, 不能再优美。
这两点放在一块,我们就可以完美的定义Q value,它就是在理性人(没步下做最优选择)假设下每一步的收益按贴现率加和来的未来收益总期望。这么绕口,其实我还没说下半句, 那就是在此刻某个行为下的期望,太累了,分开讲。 这整个定义,就是充满智慧的Q - value。
然后Q - learning呢? 刚说过了, 学习,是通过既往的经验, Q - learning的过程就是根据行为做出后得到的真实境遇(可以是奖励或是惩罚,也可以是新的位置的Q值)来更新这个期望的过程, that‘s all。 当Q 值被更新, 你的行为也就被更新了 ,因为我每一次的行为无非选择最大的Q值。
这里, 我们做一个更简单的例子, 把强化学习变成一个简单走迷宫的游戏, 在最经典的Q-learning下看看效果。 不要小看它简单, 小小的迷宫可以玩出深度学习的众多花样。
游戏的框架被称为“冰湖” : 北方之王(king of north)统治的国度里有一个巨大的冰湖,冰湖里隐藏着一些深不可测的冰洞, 冰湖的某个角落藏着关系帝国龙脉的宝藏, 一群流亡士兵要在黑夜里穿越冰湖找到保藏, 而且不要掉到洞里。 而且冰湖上时刻管着凌琳的风, 你跑路的风向以某个概率被风吹偏。。士兵要决策自己跑路的方向,最终更快更安全的拿到宝藏。
这个游戏的版本一是你手里有一个GPS, 士兵知道坐标,但没有记忆, 士兵手里有一个巨大的表格, 记下每个位置下不同方向的。Q值,士兵们一个接个去寻找, 通过Q叠代, 让后面的士兵更快更安全的走到地方。
此处我们得到一个典型的马尔科夫决策过程,每一步的状态(位置)都可以决定你的全部未来, 你唯一需要迭代的是那个往不同方向迈一步可能得到的后果。
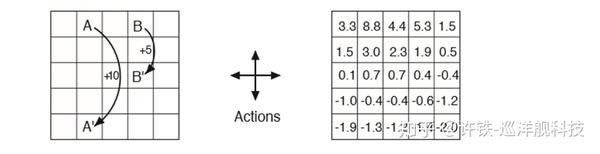
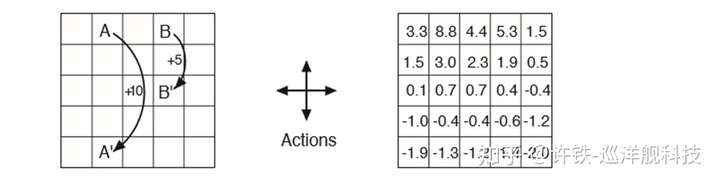 经过几轮迭代以后,我们的这个小小冰湖世界的所有位置都被填进了这个 神秘的Q-value
经过几轮迭代以后,我们的这个小小冰湖世界的所有位置都被填进了这个 神秘的Q-value
那么我说好,这个黑色的冰湖, 绝地大多说地方一个信号都没有, 你都收不到远方的奖励感知信号, 哪来的学习呢? 那么好了 , 我们这个Q - leanring的表格, 就是关键。 因为你第一步迭代的一定是离你和目标最近的那个点,这个点率先得到更高的Q值,当这个点被更新了,下一次走到它附近的agent就很可能会迭代它周边的这个Q值, 如此以往,Q值会被逐步的迭代出来,如同一个从不幸到幸福的梯度场, agent无论何时开始出发,都可以很快的循着这个梯度场(找到相邻位置里最幸福的那个位置)达到目标, 并且越来越聪明的躲开冰洞,无论它离目标和危险有多远, 无论这些士兵本身对冰湖并无概念,也对地理毫无了解, 他们的表现却让你觉得他们对远方的局势了如执掌。
这一点对于这样一个状态数量非常有限, 当下的行为仅需要考虑当下状态 ,而且奖励非常确定的时候能是可以求解的。 上述这个框架又被称为马尔科夫决策框架,“马尔科夫”无论出现在哪里,都是描述当下状态可以完全决定下一刻状态的某种时间“离散”的游戏(典型的如围棋,象棋)

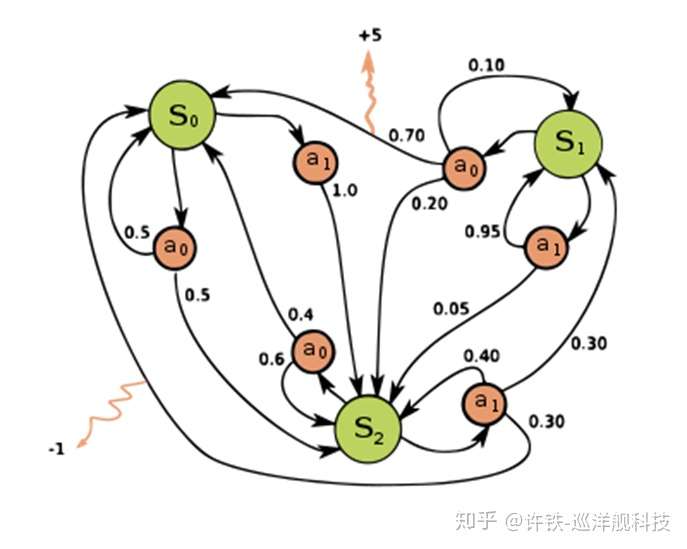
一旦上面说的任何一条被打破,游戏就没有那么简单了。 例如:
1, 当我的冰湖变得非常巨大, 可能达到的状态达到无穷多, 这时候你要计算一个通往“幸福”的梯度场变得没那么容易。 所以, 我用我深度学习的惯有招数, 我用一个带有先验信息的神经网络来假设这个梯度场的结构再学习! 此处可以有deep Q learning。
2, 既然状态多不好搞,能不能更直接一点, 不学习Q值, 而是直接学习行为? 于是我们有了policy learning。比如著名的policy-gradient , actor-critic这些deepmind的家常菜。
3, 士兵手里不再具有GPS定位信息, 而是只知道相邻位置的状态, 这时候他只能够像盲人摸象一样四处摸。 这时候你有一个非全局的马尔科夫决策过程。 因为你每一步的信息已经不足以让你做出智慧的决定。 那怎么办? 当下信息不足,我就用历史信息来补充, 来个循环神经网络给我, 再加一个能够自己生成定位的神经网络! 此处请看deepmind最新文章Vector-based navigation using grid-like representations in artificial agents。
由此我们从一个简单的自己对世界环境毫无知觉的agent,一步步迈向了自己心中具有世界模型, 可以通过自己的学习生成世界模型的agent, 认知诞生了, 知识诞生了,而一切都提高了我们强化学习创造的虚拟生命的学习效率和生存可能。


有了这些更新的方法, 我们就从最简单的游戏迈向了围棋, 迈向了星际争霸这些你真正爱玩的游戏, 最终迈向真实的生活。