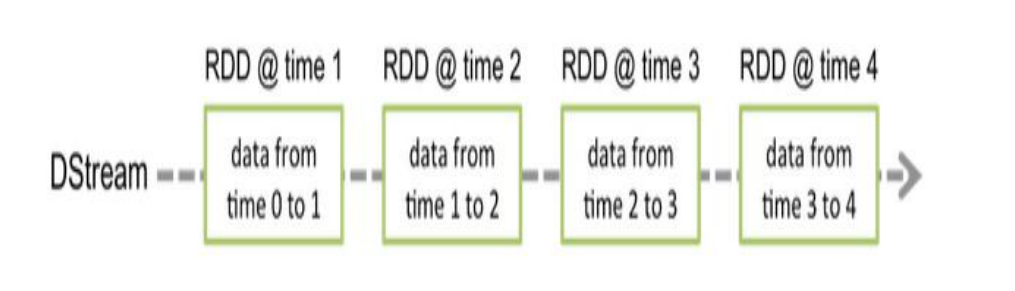
Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。
◆ 支持从多种数据源获取数据,包括Kafka、Flume、Twitter、ZeroMQ、Kinesis
以及TCP sockets,从数据源获取数据之后,可以使用诸如map、reduce、join
和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文
件系统,数据库等。
在流数据分成一批一批后,通过一个先进先出的队列,然后 Spark Engine从该
队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行处理,这
是一个典型的生产者消费者模型,对应的就有生产者消费者模型的问题,即如
何协调生产速率和消费速率。 Kafka协调速率
◆ 离散流(discretized stream)或DStream
◆ 批数据(batch data)
◆ 时间片或批处理时间间隔( batch interval)
◆ 窗口长度(window length)
◆ 滑动时间间隔
◆ Input DStream
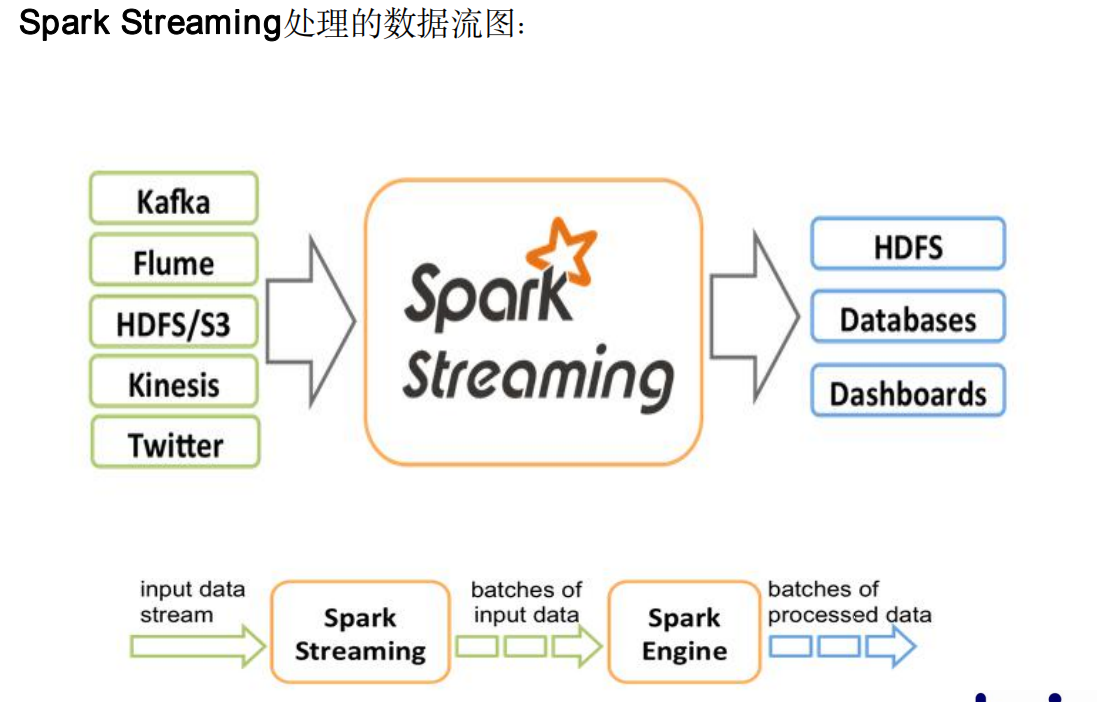
DStream(Discretized Stream)离散流
◆ 和Spark基于RDD的概念很相似,Spark Streaming使用离散流
(discretized stream)作为抽象表示,叫做DStream。
◆ DStream是随时间推移而收到的数据的序列。在内部,每个时间区间收
到的数据都作为RDD存在,而DStream是有这些RDD所组成的序列