- 二叉树遍历--先序遍历中左右,中序遍历左中右,后续遍历左右中
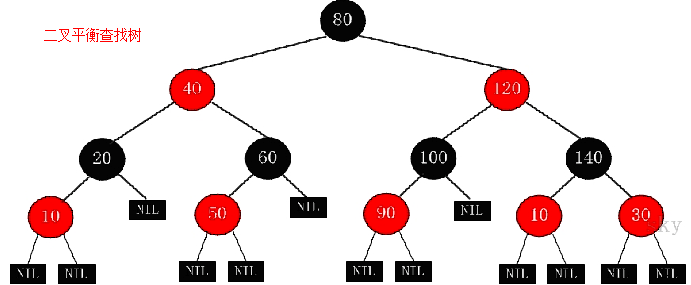
- 平衡二叉树(又称AVL树,有别于AVL算法):每个节点的左右子树高度最多差1的二叉排序树;目的是减少二叉查找树层次,提高查找速度;实现此理念方法有红黑树、替罪羊树、伸展树、AVL、Treap等
红黑树是相对接近平衡的二叉树,应用比较广泛,主要用它来存储有序的数据,由于时间复杂度O(logN),效率非常之高;例Java集合中的TreeSet和Tree Map,C++中的set和map,以及linux虚拟内存的管理,都有此实现。

- B(B-Tree=B-=B)、B+、B*
文件系统和数据库系统中常用的B/B+ 树,他通过对每个节点存储个数的扩展,使得对连续的数据能够进行较快的定位和访问,能够有效减少查找时间,提高存储的空间局部性从而减少IO操作。他广泛用于文件系统及数据库中,如:
Windows:HPFS 文件系统
Mac:HFS,HFS+ 文件系统
Linux:ResiserFS,XFS,Ext3FS,JFS 文件系统
数据库:ORACLE,MYSQL,SQLSERVER 等中
数据库:ORACLE,MYSQL,SQLSERVER 等中
B树相对于平衡二叉树的不同是,每个节点包含的关键字增多了,特别是在B树应用到数据库中的时候,数据库充分利用了磁盘块的原理(磁盘数据存储是采用块的形式存储的,每个块的大小为4K,每次IO进行数据读取时,同一个磁盘块的数据可以一次性读取出来)把节点大小限制和充分使用在磁盘快大小范围;把树的节点关键字增多后树的层级比原来的二叉树少了,减少数据查找的次数和复杂度;
b树(balance tree)和b+树应用在数据库索引,可以认为是m叉的多路平衡查找树,但是从理论上讲,二叉树查找速度和比较次数都是最小的,为什么不用二叉树呢?
因为我们要考虑磁盘IO的影响,它相对于内存来说是很慢的。数据库索引是存储在磁盘上的,当数据量大时,就不能把整个索引全部加载到内存了,只能逐一加载每一个磁盘页(对应索引树的节点)。所以我们要减少IO次数,对于树来说,IO次数就是树的高度,而“矮胖”就是b树的特征之一,它的每个节点最多包含m个孩子,m称为b树的阶,m的大小取决于磁盘页的大小
有关b树的一些特性,注意与后面的b+树区分:
- 关键字集合分布在整颗树中;
- 任何一个关键字出现且只出现在一个结点中;
- 搜索有可能在非叶子结点结束;
- 其搜索性能等价于在关键字全集内做一次二分查找;
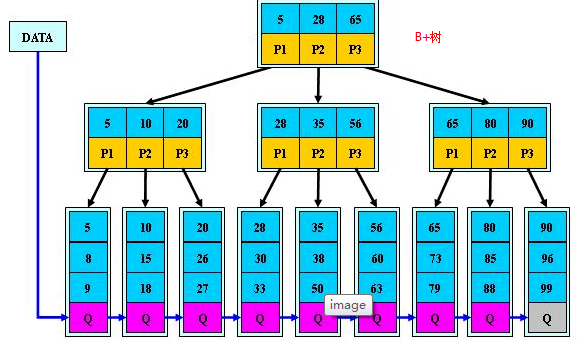
b+树,是b树的一种变体,查询性能更好。m阶的b+树的特征:
- 有n棵子树的非叶子结点中含有n个关键字(b树是n-1个),这些关键字不保存数据,只用来索引,所有数据都保存在叶子节点(b树是每个关键字都保存数据)。
- 所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
- 所有的非叶子结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
- 通常在b+树上有两个头指针,一个指向根结点,一个指向关键字最小的叶子结点。
- 同一个数字会在不同节点中重复出现,根节点的最大元素就是b+树的最大元素。
b+树相比于b树的查询优势:
- b+树的中间节点不保存数据,所以磁盘页能容纳更多节点元素,更“矮胖”;
- b+树查询必须查找到叶子节点,b树只要匹配到即可不用管元素位置,因此b+树查找更稳定(并不慢);
- 对于范围查找来说,b+树只需遍历叶子节点链表即可,b树却需要重复地中序遍历
1,第一次磁盘IO,把9所在节点读到内存,把目标数5和9比较,小,找小于9对应的节点;
2,第二次磁盘IO,还是读节点到内存,在内存中把5依次和2、6比较,定位到2、6中间区域对应的节点;
3,第三次磁盘IO就不上图了,跟第二步一样,然后就找到了目标5。
可以看到,b树在查询时的比较次数并不比二叉树少,尤其是节点中的数非常多时,但是内存的比较速度非常快,耗时可以忽略,所以只要树的高度低,IO少,就可以提高查询性能,这是b树的优势之一。
B+
B+树是B树的一个升级版,相对于B树来说B+树更充分的利用了节点的空间,让查询速度更加稳定,其速度完全接近于二分法查找。为什么说B+树查找的效率要比B树更高、更稳定;我们先看看两者的区别
(1)B+跟B树不同B+树的非叶子节点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子节点所能保存的关键字大大增加;
(2)B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样;
(3)B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
(4)非叶子节点的子节点数=关键字数(来源百度百科)(根据各种资料 这里有两种算法的实现方式,另一种为非叶节点的关键字数=子节点数-1(来源维基百科),虽然他们数据排列结构不一样,但其原理还是一样的Mysql 的B+树是用第一种方式实现)
1、B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;
2、B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
3、B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
4、B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。
B树:由于是多叉结构,对于元素数量非常多的情况下,树的深度不会像二叉树结构那么大,可以保证查询效率。多用做文件系统的索引。
正因为文件系统和数据库一般都是存在电脑硬盘上的,如果数据量太大的话不一定能一次性加载到内存中。(一棵树不能一次性加载完怎么查找?)但是B树可以多叉存储。也正因为B树的这一个优点,可以在文件查找的时候每次只加载一个节点的内容存入内存来查找。而红黑树在内存中查找非常块,但是如果在数据库和文件系统中,显然B树更优。
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中。多用于数据库中的索引---因为在数据库中select常常不只是查询一条记录,常常要查询多条记录,若是多条的话,B树需要做中序遍历,可能要跨层访问,而B+树由于所有数据都在叶子结点上,不用跨层,同时由于有链表结构,只需要找到首尾,通过链表就能把所有数据取出来。
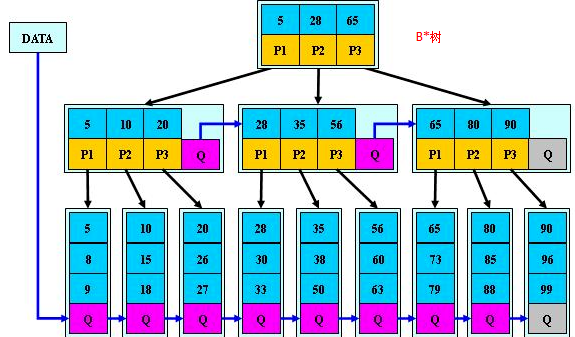
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;


https://www.zhihu.com/question/30527705
https://zhuanlan.zhihu.com/p/27700617
https://mp.weixin.qq.com/s/jRZMMONW3QP43dsDKIV9VQ
http://blog.jobbole.com/79311/