发展一个有效算法的具体(一般)过程:

union-find用来解决dynamic connectivity,下面主要讲quick find和quick union及其应用和改进。
基本操作:find/connected queries和union commands

动态连接性问题的场景:
1.1 建立模型(Model the problem):
关于object:0-N-1

关于连接的等价性:

关于连接块:
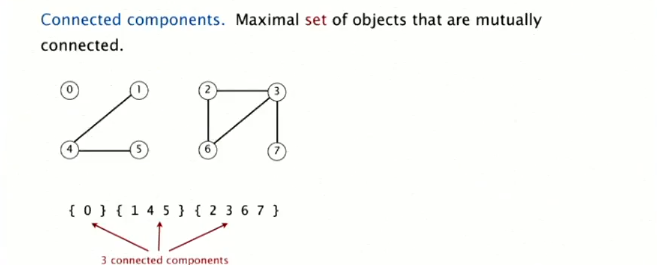
关于基本操作find query和union command:
比如union操作:
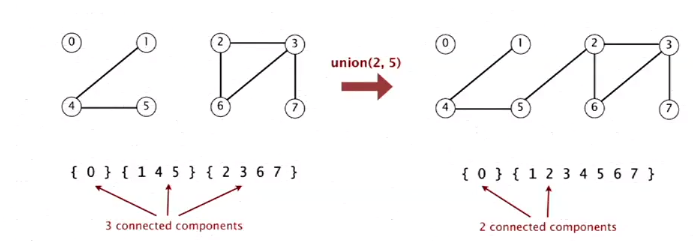
目标:

练习:

答案:C。最后剩下的连接块有{0,5,6}{3,4}{1,2,7,8,9}。
1.2 算法及其改进(Algorithm and improvement):
1.2.1 Quick Find
实现过程:
1 public class QuickFindUF 2 { 3 private int[] id; 4 5 public QuickFindUF(int N) 6 { 7 id = new int[N]; 8 for (int i = 0; i < N; i++) 9 id[i] = i; 10 } 11 12 public boolean connected(int p, int q) 13 { return id[p] == id[q]; } 14 15 public void union(int p, int q) 16 { 17 int pid = id[p]; 18 int qid = id[q]; 19 for (int i = 0; i < id.length; i++) 20 //这里有个约定: 21 //p和q联合的时候,所有和p是一个连接块(connected conponents)的点的id都要设置为与id[q]相等 22 if (id[i] == pid) id[i] = qid; 23 } 24 }
各个函数的时间复杂度: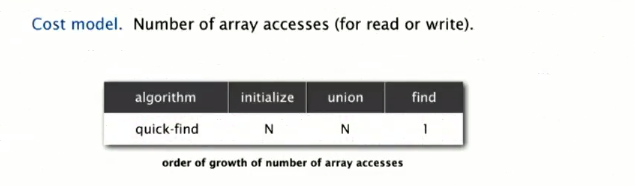
弊端:

对N个实体做N次的union操作,时间复杂度是O(N2)。换言之,Quick find太慢,不适合大量的数据。
练习:
答案:C。最差情况就是除了id[q],其他元素都要改变。
1.2.2 Quick Union
说明:

实现过程:
1 public class QuickUnionUF 2 { 3 private int[] id;//id[i],节点i的父节点 4 5 public QuickFindUF(int N) 6 { 7 id = new int[N]; 8 //划分为N棵子树,每个子树的根节点就是本身 9 for (int i = 0; i < N; i++) 10 id[i] = i; 11 } 12 13 private int root(int i)//找打i所在子树的根节点 14 { 15 //如果id[i] == i,说明i是某一棵子树的根节点 16 while (i != id[i]) i = id[i]; 17 return i; 18 } 19 20 public boolean connected(int p, int q) 21 { 22 return root(p) == root(q); 23 } 24 25 public void union(int p, int q)//将p所在子树的根节点的父节点设为q所在子树的根节点 26 { 27 int i = root(p); 28 int j = root(q); 29 id[i] = j; 30 } 31 }
各个操作的时间复杂度:注意quick union的union和find是最差情况(例如,形成的子树很高)的时间复杂度。

弊端:
练习:

答案:D。3的根节点是6:3->5->2->6。7的根节点是6:7->1->9->5->2->6。
练习:
答案:C
1.2.3 Weighted quick union
Improvement 1:weighting。为每个树保留track记录树的规模;union的时候将规模小的树的根节点添加为规模大的树的根节点的子节点。主要针对Quick union中容易出现树很高的情况。
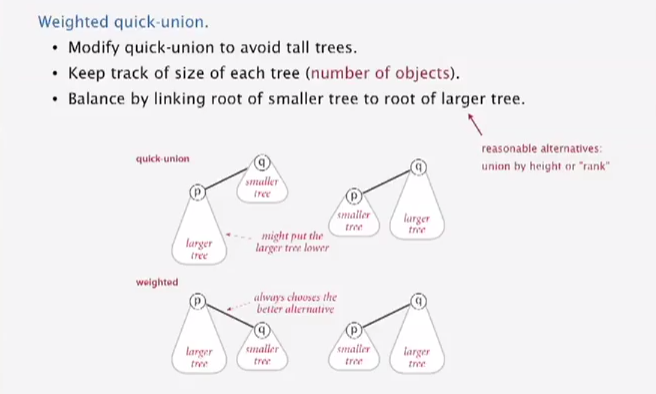
实现过程:
1 public class WeightedQuickUnionUF { 2 private int[] id,sz; 3 4 public WeightedQuickUnionUF(int N) 5 { 6 id = new int[N]; 7 sz = new int[N];//记录以i为根节点的树的节点个数 8 for (int i = 0; i < N; i++) 9 { 10 sz[i] = 1; 11 id[i] = i; 12 } 13 } 14 15 private int root(int i)//和quick union相同 16 { 17 while (i != id[i]) i = id[i]; 18 return i; 19 } 20 21 public boolean connected(int p, int q)//和quick union相同 22 { 23 return root(p) == root(q); 24 } 25 26 public void union(int p, int q) 27 { 28 int i = root(p); 29 int j = root(q); 30 if (i == j) return; 31 if (sz[i] < sz[j]){id[i] = j; sz[j] += sz[i];} 32 else {id[j] = i; sz[i] += sz[j];} 33 } 34 }
各个函数的时间复杂度:注意到weighted quick union中的union和connected操作的时间复杂度都是log2N。

命题:按照Weighted quick union实现的树的任意一个节点的深度不会超过log2N。
证明:关注任意节点x。
1. 只有当包含x的子树T1作为lower tree被合并的时候,x的深度才有可能增加1。
2. 另一棵树T2,其中sz[T2]>=sz[T1]。
每合并1次,树的规模*2,并且最后的树的规模==N,所以x最多只能增加log2N次,意味着节点x最后的深度不会超过log2N。
Weighted quick union和Quick union的比较实例:
Weighted quick union实现结果更加均衡,叶节点到根的距离最大为4,每个节点到根节点的距离的平均要远远小于Quick union的结果。

1.2.4 Weighted quick union with path compressioin
Improvement 2:path compression。就是路径压缩。

实现过程有2种方式:主要区别是root函数的实现。
1. 找到当前点x的根节点后,将x与根节点相连路径上的所有节点的父节点设为根节点。
2. 在寻找当前点x的根节点的过程中,直接将x的父节点设置为x的父节点的父节点。

下面只展示union函数的实现:
方式1:
1 private int root(int i) 2 { 3 if (id[i] == i) return i;//只有指向根节点才返回 4 return id[i] = root(id[i]); 5 }
方式2:
1 private int root(int i) 2 { 3 while (i != id[i]) 4 { 5 id[i] = id[id[i]];//指向父节点的父节点 6 i = id[i]; 7 } 8 return i; 9 }
对N个点使用Weighted quick union with path compressioin中的union find操作m次的时间复杂度:

关于lg*的解释:http://stackoverflow.com/questions/2387656/what-is-olog-n/2387669
log* (n)- "log Star n" as known as "Iterated logarithm"
In simple word you can assume log* (n)= log(log(log(.....(log* (n))))
已经证明,union find问题的时间复杂度不可能到O(N)。
练习:


答案:

总结:
