DataFrame由record序列组成,record的类型是Row类型。
columns代表者计算表达式可以在独立的record上运行。
Schema定义了各列的名称和数据类型。
分区定义了DataFrame和DataSet在集群上的物理分配。
Schemas
可以让数据源定义Schema(又叫做读时模式)或者自己明确定义模式。
警告:读时模式可能会导致精度问题,在用Spark做ETL时,最好自己指定模式。
Schema是由StructField组成的StructType。StructField由名称、数据类型、一个Boolean类型标记该列是否可以缺失或包含null的标记、用户可选指定列相关的元数据(在ML中用到)组成
。
如果数据中的类型与Schema不匹配,spark 会报错。
- 打印DataFrame的Schema
df.printSchema()
root
|-- DEST_COUNTRY_NAME: string (nullable = true)
|-- ORIGIN_COUNTRY_NAME: string (nullable = true)
|-- count: long (nullable = true)
- 查看DataFrame的Schema
df.schema
StructType(StructField(DEST_COUNTRY_NAME,StringType,true), StructField(ORIGIN_COUNTRY_NAME,StringType,true), StructField(count,LongType,true))
- 定义Schema
val myManualSchema = StructType(
Array(
StructField("DEST_COUNTRY_NAME", StringType, true),
StructField("ORIGIN_COUNTRY_NAME", StringType, true),
StructField("count", LongType, false, Metadata.fromJson("{"hello":"world"}"))
))
- 加载数据时指定Schema
val df1 = spark.read.format("json").schema(myManualSchema).load(dataPath)
Columns and Expressions
对于Spark而言,column代表每个record经过表达式计算后的值。column不能脱离row、DataFrame而独立存在。不能在没有DataFrame的情况下操作column,必须通过DataFrame的转换操作来修改column内容。
Columns
构建、引用列用column或col。
import org.apache.spark.sql.functions.{col, column}
col("someColumnName")
column("someColumnName")
Columns are not resolved until we compare the column names with those we are maintaining in the catalog. Column and table resolution happens in the analyzer phase。
Explicit column references
$"someColumnName"
The $ allows us to designate a string as a special string that should refer to an expression. The tick mark (') is a special thing called a symbol; this is a Scala-specific construct of referring to some identifier. They both perform the same thing and are shorthand ways of referring to columns by name.
明确引用列
明确引用某一DataFrame的列,只需使用DataFrame的col方法,可以让Spark在分析阶段不解析列,减轻Spark负担。
df.col
Expressions
表达式是一系列的在DataFrame上record一个或多个值执行的转换。
最简单的表达式可以通过expr函数创建,这简单引用列。expr("xxx")等同与col("xxx")
Columns as expressions
Columns provide a subset of expression functionality. If you use col() and want to perform transformations on that column, you must perform those on that column reference.
the expr function can actually parse transformations and column references from a string and can subsequently be passed into further transformations. Let’s look at some examples.
expr("someCol - 5") is the same transformation as performing col("someCol") - 5, or even expr("someCol") - 5.That’s because Spark compiles these to a logical tree specifying the order of operations. This might be a bit confusing at first, but remember a couple of key points:
Columns are just expressions.
Columns and transformations of those columns compile to the same logical plan as parsed expressions.
示例:
(((col("someCol") + 5) * 200) - 6) < col("otherCol")
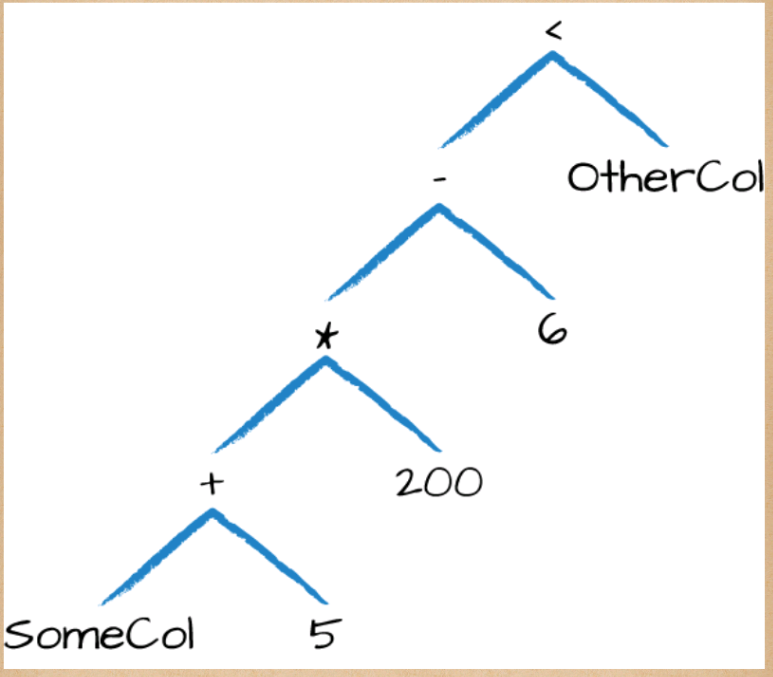
等效于
import org.apache.spark.sql.functions.expr
expr("(((someCol + 5) * 200) - 6) < otherCol")
This is an extremely important point to reinforce. Notice how the previous expression is actually valid SQL code, as well, just like you might put in a SELECT statement? That’s because this SQL expression and the previous DataFrame code compile to the same underlying logical tree prior to execution. This means that you can write your expressions as DataFrame code or as SQL expressions and get the exact same performance characteristics.
Accessing a DataFrame’s columns
DataFrame.columns 访问所有列
Records and Rows
DataFrame中的row是一个record。Spark用row类型的对象表达record。Spark用列表达式来操作row。Row对象内部表示为字节数组。字节数组没有借口暴露给用户,用户只能使用列表达式来操作它。
DataFrame.first() 返回第一行
Creating Rows
用户可以实例化一个Row对象创建Row。Row没有Schema,DataFrame才有。如果DataFrame想添加Row,必须保证Row的值顺序相同。
import org.apache.spark.sql.Row
val row = Row("Hello", null, 1, false)
访问Row中的值:指明值的位置,并强制转换值的类型
row(0).asInstanceOf[String]
row(2).asInstanceOf[Int]
或者返回JVM中对应的类型
row.getString(0)
row.getInt(2)
DataFrame Transformations
- 可以添加、移除row、column
- 可以在行转换为列、列转换为hang
- 可以根据列值改变行序
Creating DataFrames
可以通过加载数据方式来创建DataFrame,
也可以通过创建Row,指定Schema来创建DataFrame。
val rowSchema = StructType(
Array(
StructField("Some", StringType, true),
StructField("col", StringType, true),
StructField("name", LongType, false)
)
)
val rows = Seq(Row("Hello", null, 1L))
val rdd = spark.sparkContext.parallelize(rows)
val dataFrame = spark.createDataFrame(rdd, rowSchema)
在Scala中,可以利用隐式转换来在Seq上使用toDF函数来创建,这种方法在null值上不能运行,所以不推荐在生产环境中使用。
rows.toDF("col1", "col2", "col3")
?:
rows.toDF("col1", "col2", "col3")报错
Name: Compile Error
Message: <console>:32: error: value toDF is not a member of Seq[org.apache.spark.sql.Row]
rows.toDF("col1", "col2", "col3")
^
StackTrace:
- 包org.apache.spark.sql.functions中有许多函数可以使用
- select 函数 与列和表达式 一起使用
- show() 打印
- select示例
df.select("DEST_COUNTRY_NAME").show(2)- 选择多列
df.select("DEST_COUNTRY_NAME", "ORIGIN_COUNTRY_NAME").show(2) - 使用不同的引用方式引用列
import org.apache.spark.sql.functions.{expr, col, column}
df.select(
df.col("DEST_COUNTRY_NAME"),
col("DEST_COUNTRY_NAME"),
$"DEST_COUNTRY_NAME",
'DEST_COUNTRY_NAME,
expr("DEST_COUNTRY_NAME"),
column("DEST_COUNTRY_NAME")
).show(2)
一个常见的错误:混淆了column和column名称的字符串
expr很灵活,既可以引用列也可以操作列的字符串
- alias()
!:DataFrame也用alias方法。详见https://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.Dataset中alias
df.select(expr("DEST_COUNTRY_NAME AS desitination").alias("DEST_COUNTRY_NAME")).show(2)
df.select(expr("DEST_COUNTRY_NAME AS desitination")).alias("DEST_COUNTRY_NAME").show(2)
df.select(expr("DEST_COUNTRY_NAME")).alias("DEST_COUNTRY_NAME").show(2)
df.alias("DEST_COUNTRY_NAME").show(2)
df.select('DEST_COUNTRY_NAME.alias("d")).show(2)
+-----------------+
|DEST_COUNTRY_NAME|
+-----------------+
| United States|
| United States|
+-----------------+
only showing top 2 rows
+-------------+
| desitination|
+-------------+
|United States|
|United States|
+-------------+
only showing top 2 rows
+-----------------+
|DEST_COUNTRY_NAME|
+-----------------+
| United States|
| United States|
+-----------------+
only showing top 2 rows
+-----------------+-------------------+-----+
|DEST_COUNTRY_NAME|ORIGIN_COUNTRY_NAME|count|
+-----------------+-------------------+-----+
| United States| Romania| 15|
| United States| Croatia| 1|
+-----------------+-------------------+-----+
only showing top 2 rows
+-------------+
| d|
+-------------+
|United States|
|United States|
+-------------+
only showing top 2 rows
- selectExpr 与表达式字符串一起使用, 甚至可以和任何非聚合SQL语句一起使用,只用列能够解析。
We can treat selectExpr as a simple way to build up complex expressions that create new DataFrames. In fact, we can add any valid non-aggregating SQL statement, and as long as the columns resolve, it will be valid!
示例:
df.selectExpr("*", "(DEST_COUNTRY_NAME = ORIGIN_COUNTRY_NAME) AS withinCountry").show(2)
With select expression, we can also specify aggregations over the entire DataFrame by taking advantage of the functions that we have.
用selectExpr,我们可以指定聚合方式来聚合整个DataFrame.
df.selectExpr("avg(count)", "count(distinct(DEST_COUNTRY_NAME))").show(2)
Converting to Spark Types (Literals)
import org.apache.spark.sql.functions.lit
df.select(expr("*"), lit(1).as("One")).show(2)
Adding Columns
DataFrame.withColumn() 其有两个参数:列名、表达式在给定行上计算出来的值
df.withColumn("One", lit(1)).show(2)
withColumn可以用来重命名列名, !会产生重复列。
df.withColumn("dist", expr("DEST_COUNTRY_NAME")).show(2)
Renaming Columns
DataFrame.withColumnRenamed()
Reserved Characters and Keywords
用`号来转义保留的字符
val dfLongName = df.withColumn("The Long ColumnName", expr("DEST_COUNTRY_NAME"))
dfLongName.selectExpr("`The Long ColumnName`", "`The Long ColumnName` as `new col`").show(2)
We can refer to columns with reserved characters (and not escape them) if we’re doing an explicit string-to-column reference, which is interpreted as a literal instead of an expression. We only need to escape expressions that use reserved characters or keywords.
只有涉及表达式时才需要转义,当只引用含有保留字符的列时不需要转义。
dfLongName.select(col("The Long ColumnName")).show(2)
Case Sensitivity
Spark大小写不敏感
df.select("dest_country_name").show(2)
可以设为大小写敏感
-- in SQL
set spark.sql.caseSensitive true
Removing Columns
DataFrame.drop()可以删除一列或多列。
Changing a Column’s Type (cast)
column.cast()
df.withColumn("count", col("count").cast("long")).show(2)
Filtering Rows
where() 与filter()
df.filter(col("count") < 2).show(2)
df.where("count < 2").show(2)
不要多个过滤器在同一个filter或where中,Spark会同时执行过滤器而无视过滤器的顺序。This means that if you want to specify multiple AND filters, just chain them sequentially and let Spark handle the rest.
Getting Unique Rows
行去重
DataFrame.distinct()
Random Samples
DataFrame.sample(withReplacement, fraction, seed)
df.sample(false, 0.1, 0).count()
Random Splits
DataFrame.randomSplit(),第一个参数为权重数组,第二个可选参数为Rondom种子
val dataFrames = df.randomSplit(Array(0.25, 0.75), 0)
dataFrames(0).count()
dataFrames(1).count()
Concatenating and Appending Rows (Union)
DataFrame不可变,不能添加行到DataFrame中。
必须合并原来的DataFrame到新的DataFrame中。两个DataFrame的Schema必须相同。
注意:合并操作基于数据存放的位置,不是模式,合并的顺序不会是一个DataFrame中Row在另一个DataFrame所用Row的前面
val appendRow = Seq(Row("new Country", "other Country", 5L),
Row("new Country2", "other Country", 1L))
val appendRdd = spark.sparkContext.parallelize(appendRow)
val appendDF = spark.createDataFrame(appendRdd, df.schema)
df.union(appendDF).where("count = 1").where($"DEST_COUNTRY_NAME" =!= "United States").show()
In Scala, you must use the =!= operator so that you don’t just compare the unevaluated column expression to a string but instead to the evaluated one.
Sorting Rows
sort()、orderBy()接受多列与表达式。
默认为升序
排序使用asc()、desc()、asc_nulls_first, desc_nulls_first, asc_nulls_last, or desc_nulls_last
为了优化性能,常需要在执行其他转换前在各分区内排序。用DataFrame.sortWithinPartitions来做。
Limit
limit()
Repartition and Coalesce
重新分区会引发全部数据shuffle,无论是否有必要。意味者只有未来分区数大于目前分区数或者你根据列来查找特定分区。
df.rdd.getNumPartitions
val dfRep = df.repartition(3)
dfRep.rdd.getNumPartitions
可以根据列来分区
df.repartition(col("DEST_COUNTRY_NAME")).rdd.getNumPartitions
根据列分区并指定分区数
df.repartition(5, col("DEST_COUNTRY_NAME")).rdd.getNumPartitions
合并分区不会引发全部数据shuffle。
df.repartition(5, col("DEST_COUNTRY_NAME")).coalesce(2).rdd.getNumPartitions
Collecting Rows to the Driver
- collect()获取全部数据到Driver
- take() 获取first N行数据
- show() 获取并打印
- toLocalIterator 获取分区的遍历器,这个方法允许你一个个分区遍历全部数据。
注意:获取数据到Driver是非常昂贵的操作。