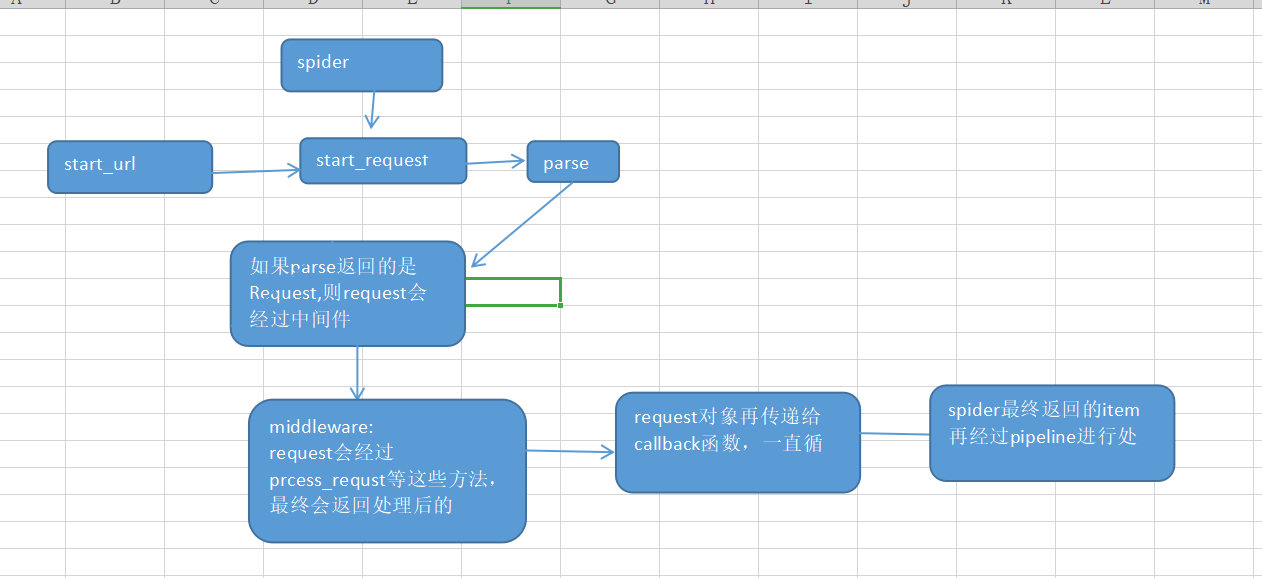
## 一、scrapy框架的每个模块的用途
1、spiders:
自定义爬虫
定义允许爬取的范围
定义开始爬取的url
parse:一定要重写
start_request:一般不需要重写,可以通过重写start_request进行模拟登陆
2、items
1)定义爬取的items域,是一个类字典的一个对象
如果在爬虫中定义了其他其他的键,即超过item的爬取范围,那么就会报错
2)其实可以通过在spider中定义一个空的字典来存储爬取的信息
3、middlewares:
主要是对请求request进行处理:process_request
如:添加随机user-agent,添加代理ip
注意:要在setting里面打开middlewares,否则无法调用其中的函数
4、pipeline:
主要功能是对Items进行存储
如:可存储在磁盘或者数据库
5、settings:
主要是定义一些全局变量或者公共变量,
可以在其他模块中获取所需要的settings变量
各个模块间参数的传递如下: