主要内容:
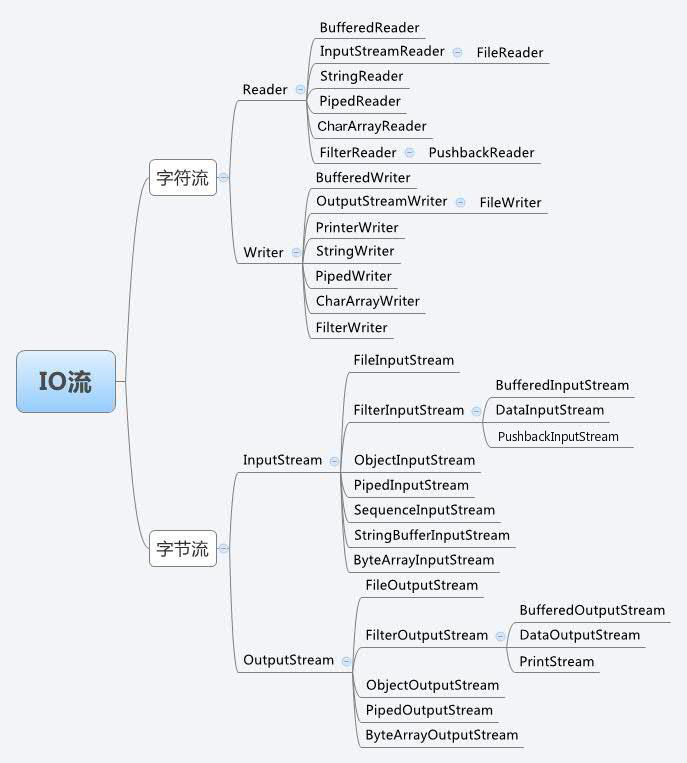
一.输入流基类:InputStream 和 OutputStream(字节流)、 Reader 和 Writer(字符流)
二.文件字节流:FileInputStream和FileOutputStream
三.转换流(字节流-->字符流):InputStreamReader 和 OutputStreamWriter、FileReader 和 FileWriter
四.缓冲流:BufferedInputStream、BufferedOutputStream 和 BufferedReader、BufferedWriter
(以下内容等待更新……)
五.数据流:DataInputStream 和 DataOutputStream
六.标准输入输出流: System.in 和 System.out
七.对象流:ObjectInputStream和OjbectOutputSteam
一.输入流基类:InputStream 和 OutputStream(字节流)、 Reader 和 Writer(字符流)
在Java中,所有的I/O类都来源于这四个抽象类,其中InputStream 和 OutputStream为字节流输入输出(二进制I/O),Reader和Writer为字符流输入输出(文本I/O)。

二.文件字节流:FileInputStream和FileOutputStream
可知,文件中的内容由最基本的字节组成。如果我们要获取里面的内容,首先就要以字节的形式去获取:

三.转换流(字节流-->字符流):InputStreamReader 和 OutputStreamWriter、FileReader 和 FileWriter
首先要明白两个概念,编码与编码格式:
1.Unicode是一种“编码”,所谓编码就是一个编号(数字)到字符的一种映射关系,就仅仅是一种一对一的映射而已,可以理解成一个很大的对应表格。
2.GBK、UTF-8是一种“编码格式”,是用来序列化或存储1中提到的那个“编号(数字)”的一种“格式”;GBK和UTF-8都是用来序列化或存储Unicode编码的数据的,但是分别是2种不同的格式。
3.在内存中,即在Java虚拟机上,字符是有“编码”而没有“编码格式”的,其“编码”为Unicode。相反,在磁盘,即文件上,字符是没有“编码”但有“编码格式”的,为“UTF-8”或“GBK”等。
(以上内容来自:java中的编码和编码格式问题)
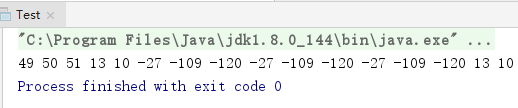
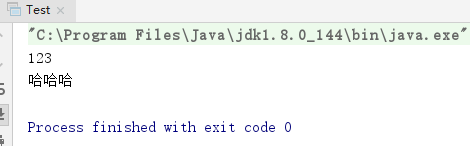
所以,磁盘中的内容是经过了“UTF-8”或“GBK”的编码的,为了从磁盘中读取这些内容:
1)先利用FileInputStream读出字节流,
2)然后再根据编码格式利用InputStreamReader进行解码,最后得到Unicode。
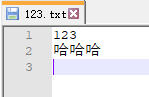
这样Java就能够识别是哪个字符了(123.txt的编码格式是utf-8)。

对于FileReader 和 FileWriter,他们是InputStreamReader 和 OutputStreamWriter的封装,根据系统默认字符集进行解码,但这不一定文件的编码相匹配,具有一定的盲目性。
四.缓冲流:BufferedInputStream、BufferedOutputStream 和 BufferedReader、BufferedWriter
在频繁的读写文件时,缓冲流能提高效率:
