主要内容:
一.Evaluating a hypothesis
二.Model selection and training/validation/test sets
三.Bias and variance
四.Learning curves
五.Precision and recall
六.High Bias 和 high variance 的应对策略
一.Evaluating a hypothesis
如何评价模型的好坏?直接绘图以此判断曲线与数据集的拟合程度似乎是一个不错的办法,但是当特征的数量较大时却不能实现,因为我们最多只能看到三维的图像;而且,怎么判断是否为过拟合或者欠拟合,也不能单凭肉眼去观察,而需要一个科学的方法就判断。如下:
1.将数据集分成两部分,第一部分约占70%,称为训练集;第二部分约占30%,称为测试集。注意:两部分的选取需要是随机的,不能带有偏见。
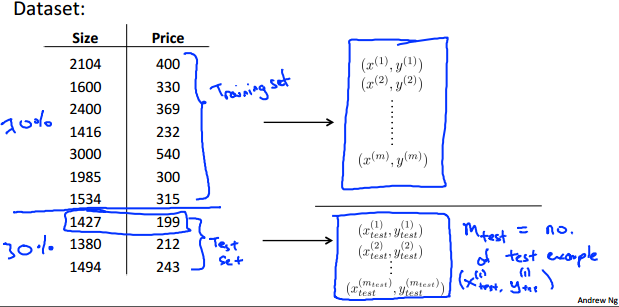
2.训练集,顾名思义就是用于训练参数;同理,测试集就是用于测试已得参数(确切的说是模型)工作的好坏,而评估的工具依然是代价函数,与训练集的代价函数不同的是:此代价函数不需要加上正则项,为什么呢?其实想想正则项的作用就可以很好理解了,正则项的作用就是在训练参数时降低参数的规模,即正则项的作用体现在求参数的过程,既然参数都求出来了,就不需要再加上正则项画蛇添足了。
例子:

二.Model selection and training/validation/test sets
面对一个数据集,我们又多种备选模型,如特征的数量(或指数次数)不同,或者正则项λ的取值不同,形成了不同的模型。那么该如何从中选择一个最合适的模型呢?如下:
1.我们将数据集分成三部分。第一部分约占60%,称为数据集;第二部分约占20%,称为检验集;第三部分约占20%,称为测试集。
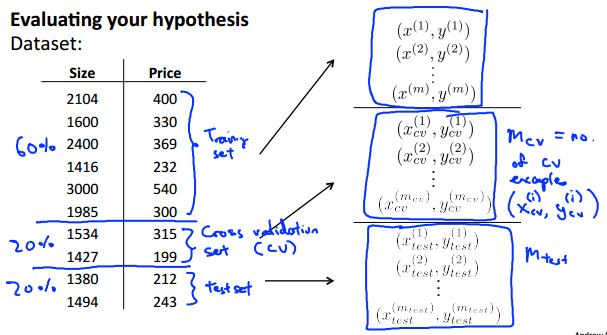
2.训练集用于训练参数;检验集用于评估已得模型的好坏,也是根据这个选择最终模型的;测试集用于测试已选模型工作的好坏。
3.首先利用训练集训练出各个模型的参数;然后再利用检验集评估每个模型工作的好坏程度,并从中挑选出表现最好的模型;最后利用测试集测试已选模型工作的好坏。
4.注意:检验集和测试集的评估和测试工具都是代价函数,并且不需要正则项,原因上文已解释。如线性回归:
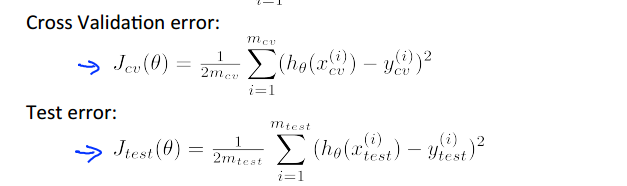
三.Bias and variance、
1.bias对应于欠拟合,variance对应于过拟合。
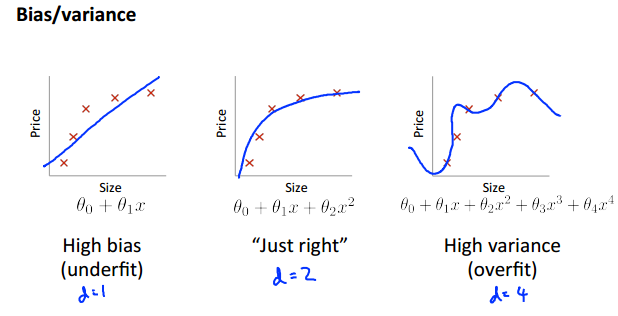
2.当特征的次数从小逐渐变大时,bias和variance所对应的J(train)和J(cv)的情况如下:
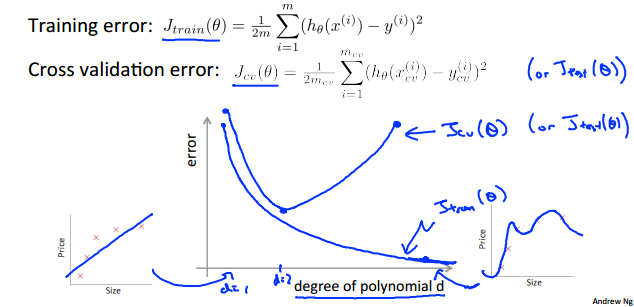

对此的解释是:
1) 对于bias,其所对应的情况是欠拟合。所谓欠拟合,也就是曲线不能很好地拟合训练集,其是由特征过于简单导致的(伸缩性不强,不能“神龙摆尾”)。那么它训练集的代价值就当然大,既然连训练集都不能很好拟合,那更不用说测试集的代价值了。所以对于bias,J(train)和J(cv)较大,且两者较为接近。
2)对于variance,其所对应的情况是过拟合。所谓过拟合,就是曲线好地拟合训练集,所以其J(train)较小,但这样曲意逢迎地讨好数据集,就导致了模型不能很好地运用于训练之外的数据,所以对应的J(cv)就比较大。
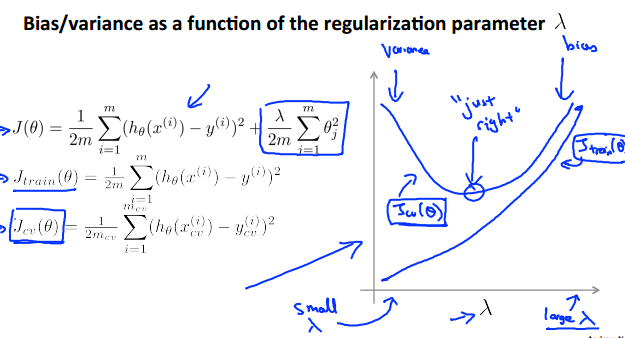
3.当讨论完特征的次数对bias和variance的影响之后,再讨论正则项系数λ对其影响:
对于线性回归,我们熟知:当λ越小时,曲线的伸缩性越好,对数据的拟合程度越好,容易出现过拟合;反之容易出现欠拟合。如下:
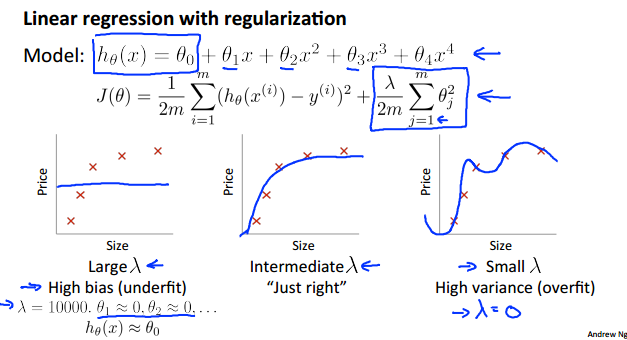
那么, 正则项系数λ的影响如下:
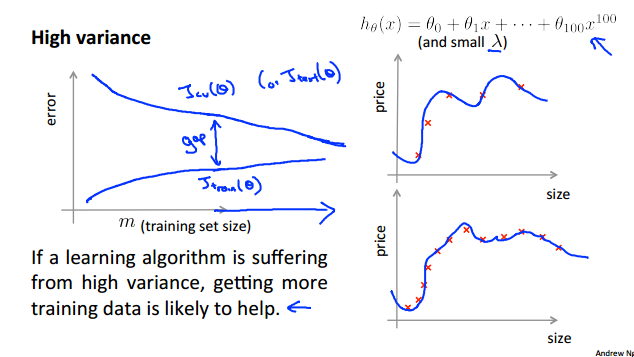
四.Learning curves
学习曲线用于检测模型是否存在bias或者variance的问题。其原理是:逐渐增加训练集的规模,观察J(train)和J(cv)的变化情况。
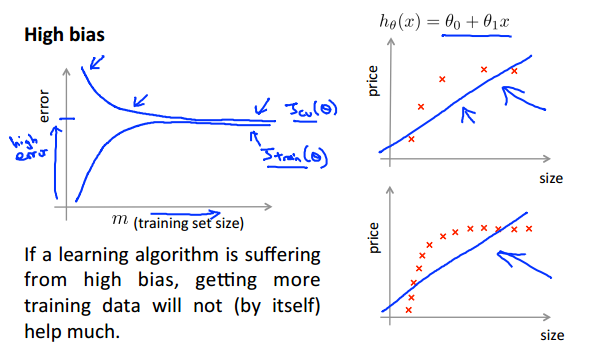
1.如果呈以下的图形,则表明存在high bias的问题,因为在欠拟合是由模型过于简单所造成的,当增加训练数据时,由于模型的伸缩性有限,所以代价也不会发生太大变化,且处于较高水平。这就从侧面表明:对于欠拟合问题,单凭增加训练数据规模,其影响是十分有限的。
2.下图则存在high variance问题。这表明:对于过拟合问题,增加训练集的规模,可以较好地解决问题。因为过拟合是由于模型过于复杂,即模型的伸缩性很强,可以“神龙摆尾”。当数据集的规模较小时,由于限制较小,曲线的许多部位可以随便放,导致其对训练集之外的数据的准确度不高;但当数据集较大时,限制就变多了,曲线的很多部位就被固定了,所以其实用性就更强。
五.Precision 、recall 、 F1 score、ROC曲线和AUC值
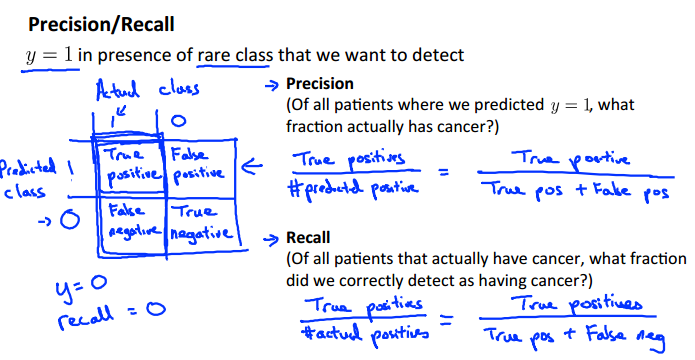
1.对于预测结果,我们设置两个指标:precision(准确率)和recall(回召率)
其中:
TP: 预测为真且实际为真 FP: 预测为真但实际为假
FN: 预测为假但实际为真 TN: 预测为假且实际为假
(
precision:所有预测为1中,真实为1的比率
recall:所有真实为1中,预测为1的比率
)
1)对于precision:我们总是希望预测的准确率高一点,可以通过提高阈值(threshold)实现。但阈值越高,就越容易造成本来是真的被判为时假(当它的预测结果低于阈值时发生),即容易造成漏网之鱼。
2)对于recall:我们希望尽量减少漏网之鱼,于是可以通过降低阈值(threshold)实现。但阈值越低,就越容易造成本来是假的被判为真(当它的预测结果高于阈值时发生),即容易造成误伤。
3)总和上述两点,,我们需要在precision(提取准确率)和recall(提高判真基数)之间做出权衡,这里引入F1 Score:
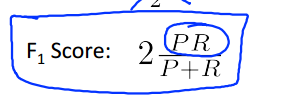
取F1 Score最大的模型即可。
2.除了利用F1 score判断模型的好坏,我们还可以利用ROC曲线及AUC值。首先映入两个概念:
1)真阳率 = TP/(TP+FN),即“实际为真且预测为真/(实际为真)”。可知真阳率只与实际为真的数据点有关。
2)假阳率 = FP/(FP+TN),即“实际为假但预测为真/(实际为假)”。可知假阳率只与实际为假的数据点有关。
而ROC曲线就是:逐步调整模型的阈值,以假阳率为X轴,以真阳率为Y轴的连续曲线,如下:
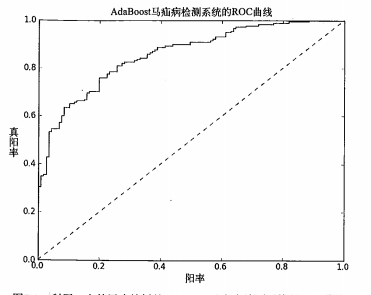
结论:
1)模型需要尽可能提高真阳率、降低假阳率。其中,当真阳率为1,假阳率为0的时候,模型是完美的。这时对应了点(0,1.0)。
2)图中对角线为随机预测的效果,而左上角区域为优于随机预测的效果,右下角为劣于随机预测的效果(此时将测试结果反过来就能得到优于随机测试的预测效果)。
3)ROC曲线越往左上角靠近,则模型的预测效果越好。为了衡量模型的好坏,我们就引入了AUC值:ROC曲线下的面积。显然AUC值越大,模型的预测效果越好。那么该如下计算AUC值呢?
(以下画ROC曲线及计算AUC值的方法摘选自:AUC计算方法总结)
假设已经得出一系列样本被划分为正类的概率,然后按照大小排序,下图是一个示例,图中共有20个测试样本,“Class”一栏表示每个测试样本真正的标签(p表示正样本,n表示负样本),“Score”表示每个测试样本属于正样本的概率。
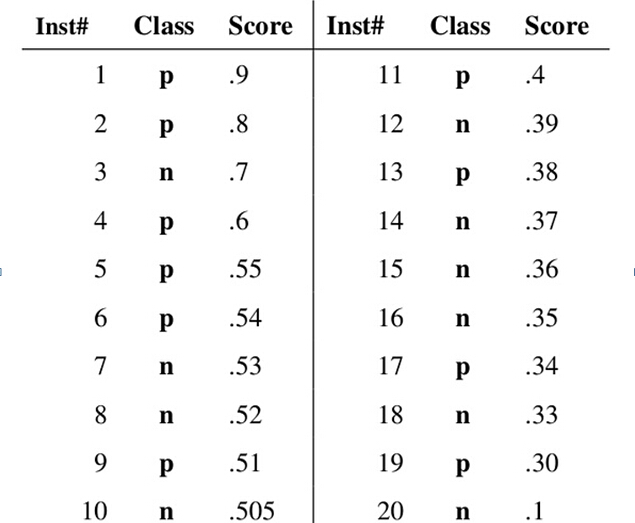
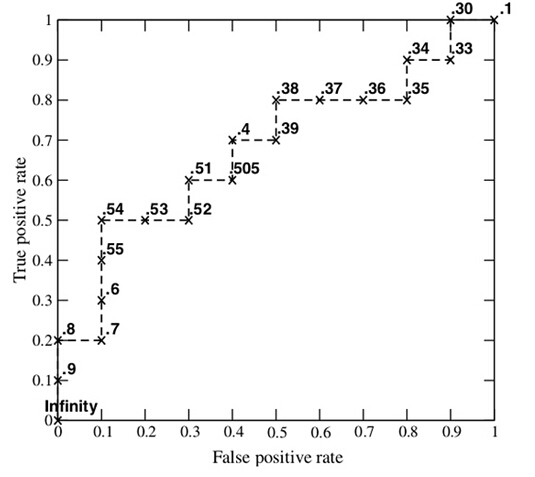
接下来,初始化所有数据点都预测为真(即阈值无限低),对应点(1.0, 1.0)。我们从低到高,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于图中的第4个样本,其“Score”值为0.6,那么样本1,2,3都被认为是正样本,因为它们的“Score”值都大于0.6,而其他样本则都认为是负样本。每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。这样一来,我们一共得到了20组FPR和TPR的值,将它们画在ROC曲线的结果如下图:
Python代码如下:
'''画出ROC曲线并计算AUC值''' def plotROC(predStrengths, classLabels): #predStrengths为通过模型计算出数据预测为真的概率,classLabels为数据实际的标签 import matplotlib.pyplot as plt cur = (1.0,1.0) #cursor #一开始将所有数据点预测为真(即阈值无限低),对应的点为(1.0, 1.0) ySum = 0.0 #variable to calculate AUC #累加所有AUC小矩形的高度,由于计算AUC值 numPosClas = sum(array(classLabels)==1.0) #标签为正的个数 yStep = 1/float(numPosClas); # 在y方向,即真阳率方向ROC曲线只会往下走numPosClas步,因而每一步为1/float(numPosClas) xStep = 1/float(len(classLabels)-numPosClas) # 在x方向,即假阳率方向ROC曲线只会往左走float(len(classLabels)-numPosClas)步 sortedIndicies = predStrengths.argsort()#get sorted index, it's reverse # 对预测为真的概率升序排序 fig = plt.figure() fig.clf() ax = plt.subplot(111) '''枚举每一个数据(预测概率从低到高),将其作为阈值。大于阈值的预测为真,小于等于阈值的预测为假,因此被枚举的被预测为假。''' for index in sortedIndicies.tolist()[0]: if classLabels[index] == 1.0: #本身为真,预测为假。则真阳率变小,假阳率不变。 delX = 0; delY = yStep; else: delX = xStep; delY = 0; #本身为假,预测为假。则假阳率变小,假真阳率不变。 ySum += cur[1] ax.plot([cur[0],cur[0]-delX],[cur[1],cur[1]-delY], c='b') #draw line from cur to (cur[0]-delX,cur[1]-delY) cur = (cur[0]-delX,cur[1]-delY) #更新当前点 ax.plot([0,1],[0,1],'b--') plt.xlabel('False positive rate'); plt.ylabel('True positive rate') plt.title('ROC curve for AdaBoost horse colic detection system') ax.axis([0,1,0,1]) # 画出随机预测的虚线 plt.show() print "the Area Under the Curve is: ",ySum*xStep #AUC的值为ySum*xStep
六.High Bias 和 high variance 的应对策略
