主要内容:
一.模型简介
二.Cost Function
三.梯度下降
四.线性回归之梯度下降法
五.线性回归之最小二乘法
六.Feature Scaling
一.模型简介:
线性回归主要用于预测:因变量与自变量存在线性关系的问题。例如coursera中介绍的买房问题:房子的价格由房子的大小以及房间的数量所决定,而这就大致可以用线性回归来预测房价。假设房价为y = Θ0 + Θ1*x1 + Θ2*x2,其中x1、x2分别代表着房子大小和房间数,Θ0和Θ1为房子大小和房间数,Θ0为常数项。当我们的数据集足够大时,就可以较为精确地求出Θ0、Θ1、Θ2这三个参数,于是线性回归方程:y = Θ0 + Θ1*x1 + Θ2*x2 就确定了,当给出x1、x2即房子大小和房间数时,我们就可以大致预测出y,即房子的价格了。
一些约定:

注:m从1开始;n从0开始,但x0默认为1。
线性回归方程:
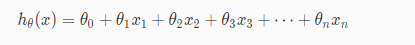
写成向量的形式:
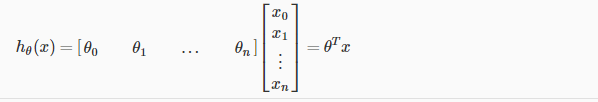
二.Cost Function
1.为了判断当前的参数Θ所确定的hθ(x)是否能很好地拟合数据集,我们引入了代价函数的概念,其大概的含义就是预测值与实际值相差了多少,不同的模型可能对应着不同的代价函数,而现行回归的代价函数为:
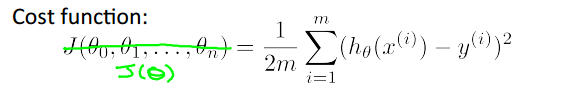
2.注:前面乘上1/2是为了在求导的时候把2给抵消掉,x^2求导为2x。为什么可直接成1/2?答:等会要求出在J(Θ)最小(梯度下降方法求到的是局部最小)的情况下,Θ的值,根据一般经验可知,在一个多项式的前面乘上一个正整数,其求得最值时的自变量不会改变,所以仍可求出Θ。)
3.这个代价函数被称为:Squared error function 或者 Mean squared error。
三.梯度下降
1.可知代价函数用于检验检测线性回归方程对数据的拟合程度,代价函数的值越小,表明线性回归方程更好地拟合数据集。所以我们要做的就是:选择合适的线性回归方程(即确定参数Θ),使得其代价函数最小。对此有两种方法:梯度下降和最小二乘法,这里先介绍梯度下降方法。
2.梯度:即多元函数在某一点上方向导数的最值,通俗点说就是在这一点上变化最大、最陡峭的那一个方向。
3.梯度的求法:J(Θ)对Θ1求偏导得,得出的是在Θ1的轴上变化率最大的那一个方向,J(Θ)对Θ2求偏导,得出的是在Θ2的轴上变化率最大的那一个方向……,于是各个偏导数所组成的向量,即指明了该点变化最大的方向,即梯度。
4.根据第3点,我们最初可以随便设置参数Θ,Θ代表着当前所在的位置。然后我们求出在这个位置上的梯度,然后沿着梯度往下走,直到某一步每条轴上的变化小于一个无穷小,即代价函数的值基本不再减小,则可以认为我们已经找到了合适的参数Θ,从而确定了线性回归方程。
5.可用下山的例子进行形象化:
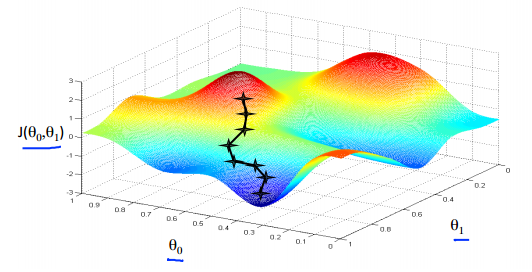
6.梯度下降的算法:

四.线性回归之梯度下降法
1.将梯度下降用于线性回归模型上:
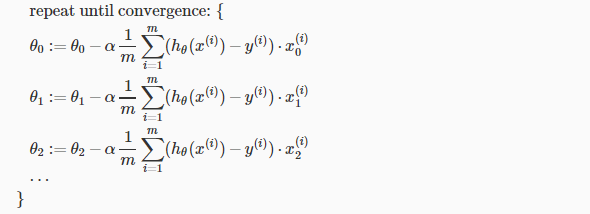 (注:α成为学习率)
(注:α成为学习率)
2.将其向量化:Θ = Θ - (α/m) * X' * (X*Θ - y):
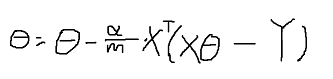
3.一般地,数据集X为m*(n+1)的矩阵形式,即一行为一个数据,每一个数据又有n+1个特征xi,其中第0个特征固定为1。而参数矩阵Θ为(n+1)*1的列矩阵,从Θ0到Θ1。证明:

4.问:为什么线性回归模型的cost function要用 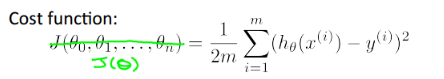 而不是其他的呢?
而不是其他的呢?
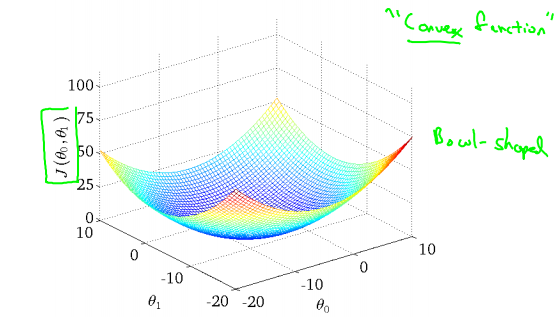
答:因为这个cost function,即J(Θ)是关于Θ的二次方程,而二次方程的图像为“碗状”的,即只有一个极值点且为最值点,对应于线性回归的cost function则有最小值点。所以,可以通过梯度下降法求出最小值点。如图:
5.为了研究J'(Θ)对梯度下降的影响,我们假设Θ0 = 0,即只有Θ1,那么图像如下:
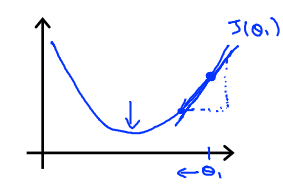
可知,J'(Θ)即为曲线在Θ上的斜率,斜率再乘上一个学习率α,则是在Θ轴上实际的移动距离。当逐渐靠近最低点时,J'(Θ)即斜率越来越小,所以移动的距离也原来越小。即越靠近最低点,走的步伐“越细”。
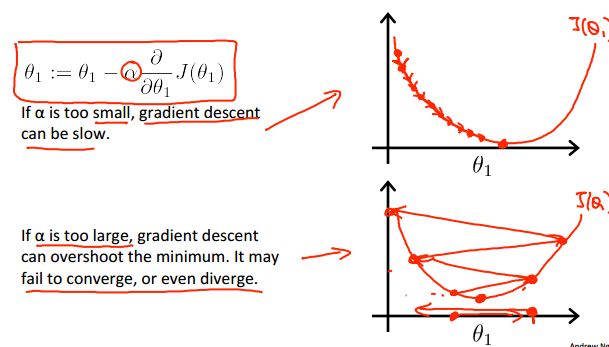
6.研究学习率α对梯度下降的影响:
1)当α太小时,走的步伐很小,迭代次数多,速度很慢。
2)当α太大时,走的步伐很大,容易一步小心就走过头,导致不能收敛。
五.最小二乘法
1.对最小二乘法的本质不太了解,只知道大概怎么求。就是利用在导数为0的情况下可求得最值。
2.公式: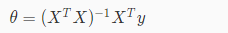
六.Feature Scaling
1.再来回看梯度下降:
假如自变量xi的范围为[0, 1.0],自变量xj的范围为[1, 10000],可知这两个自变量的范围不在同一个数量级上。根据梯度下降的递推公式可知,当自变量的范围越大,对应的参数的变化越大,导致两个参数的变化不同步。
还有一个问题:

(摘自维基百科)
为了解决这个问题,需要对自变量做一些调整:
1) 方法一:构造x' = x-min(x)/(max(x)-min(x)),即取值控制在[0,1]之中。
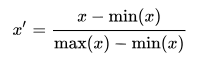
2)方法二:平均值规范化(Mean normalisation):
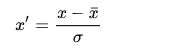
可以看得出这是一种标准化正态分布的做法,它能使得各个特征的均值为0,取值在[-1, 1]范围内。
为什么范围是[-1, 1]?因为标准差为1,即x与均值的差值在1范围内,而均值为0,所以x的范围为[-1, 1]。
2.上面两个对特征进行调整的过程叫做特征归一化,这样做有两个好处:
1)使得每个特征都处于同一个量级,从而使得每个特征对结果的影响处于同等地位。
2)加快梯度下降的收敛过程。