总结整理一下最近看过的GPU 渲染架构:
GPU 的异构性:
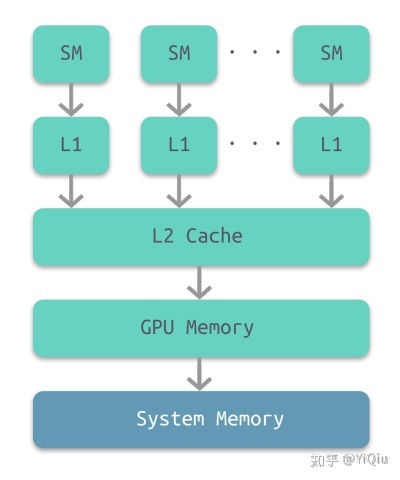
1.寄存器、L1 缓存、L2 缓存、GPU 显存、系统内存
渲染时GPU 和CPU协调工作,具体的工作协调方式 如下:
GPU架构总的来说可以分为两种,一种是分离式,一种是耦合式:

1.对于分离式GPU架构:
CPU 和GPU 有独立的缓存 和内存,通过PCI-e 总线传输 共享数据,缺点是受带宽和延迟的限制,数据传输时性能瓶颈,在PC 和移动端都是这种架构。
2.耦合式GPU 架构:
CPU 和GPU 共享缓存 和内存 AMD 的 APU 采用的就是这种结构,目前主要使用在游戏主机中,如 PS4。
存储管理方面:
分离式 有独立的缓存和内存 ,通过共享虚拟地址空间,有必要时会进行内容拷贝
耦合式 共享缓存和内存,由MMU 进行 内存管理

虚拟内存

共享内存
IMR 和TBR
先说明一下 PC 上时有显存而mobile 是没有显存的。
下面先给出 IMR 工作流程:
IMR的全称是Immediate Mode Rendering,我们通常说PC端GPU渲染用的就是下面这种架构

几何数据 、纹理数据、depth buffer、framebuffer 数据都是存在显存中;
depth buffer 、 framebuffer 从缓存中读取和写入, 几何数据 和纹理数据从显存中读取,这种数据读取方式 为了提高读取写入速度 因此增加了 寄存器 L1 和L2 缓存;来提高数据访问速度‘
TBR 如何提高数据访问速度 提高带宽呢?
下面给出 TBR 工作流程:
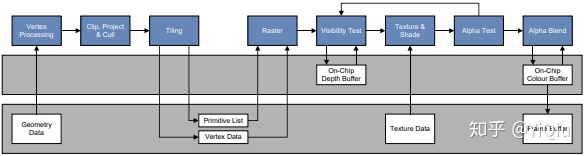
最下面一层灰色是系统内存,因为分离式GPU架构的Mobile 上没有显存的,所以通过虚拟地址空间共享系统内存;中间是相当于L1 和L2 高速缓存区,和IMR 不同的是 渲染时候 ,IMR 的color/depth buffer 是在显存中告诉缓存区完成,而TBR 是在内存中 告诉缓冲区完成;再说一下 TBR 的方式 整个光栅化和像素处理会被分为一个个Tile进行处理,通常为16×16大小的Tile。
TBR在本质上就是DeferredRendering ,为什么这样说呢?
几何阶段 Geometry Processor部分,产生的结果(Frame Data)暂时写回到系统物理内存,等到非得刷新整个FrameBuffer的时候,比如说在代码里显示的执行GLFlush,GLFinish,Bind和Unbind FrameBuffer这类操作的时候,总之就是我告诉GPU现在我就需要用到FrameBuffer上数据的时候,GPU才知道拖不了了,就会将这批绘制做光栅化,做tile-based-rendering
可以说是TBR 牺牲了执行效率 换了 降低带宽,解决带宽功耗;而PC 上IMR 并没有做TBR 这样处理 是因为执行效率高
TBDR:
TBDR是再TBR 的基础上的一次改进,又增加了Deferred, 其实只有PowerVR的GPU是使用TBDR架构的。
首先贴一些TBDR和TBR的对比图:
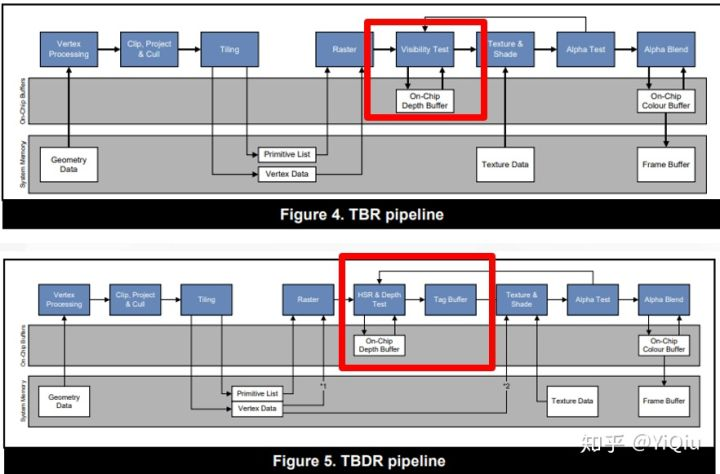
对比TBR 增加的部分 是 叫做HSR & Depth Test ,由于TBR 只解决了IMR 带宽功耗问题,对应OverDraw 问题没有解决,因而TBDR 新增的部分是处理了 OverDraw 问题;
先说一下处理overDraw 问题,通常的做法 是EarlyZ:
EarlyZ是怎么来解决Overdraw的呢,EarlyZ其实就是当不透明的图元从光栅化阶段开始逐像素进行处理时,首先进行Depth Read & Test,通过后直接写入深度,后续再执行该像素上的着色。
概括就是,绘制前先做深度检测,减少不必要的绘制。
而HSR 是 在硬件层面上做的处理 减少OverDraw 。
TBR 和TBDR 都是延迟渲染架构:
TBR:VS - Defer - RS - PS
TBDR:VS - Defer - RS - Defer - PS
再说一下HSR 减少overDraw 的原理 这里HSR,不需要在软件层面对物体进行排序,HSR在硬件上实现了零Overdraw的优化。原理也超简单,当一个像素通过了EarlyZ准备执行PS进行绘制前,先不画,只记录标记这个像素归哪个图元来画。等到这个Tile上所有的图元都处理完了,最后再真正的开始绘制每个图元中被标记上能绘制的像素点。这样每个像素上实际只执行了最后通过EarlyZ的那个PS,而且由于TBR的机制,Tile块中所有图元的相关信息都在片上,可以极小代价去获得。最终零Overdraw,毫无浪费,起飞。
最后说一下HSR是怎么处理AlphaTest和AlphaBlend的。HSR在设计原理上高到飞起,但前提是假定了前面的物体会挡住后面的物体,因此对于AlphaTest和AlphaBlend物体都是没有作用的(但他俩仍然可以被EarlyZ拦住)。不仅没作用,反而会被其中断Defer流程,导致渲染性能降低。(这里要加黑强调一下,所谓导致渲染性能降低只是与不透明物体相比较降低了,而不是说PowerVR在处理AlphaTest/Blend时比别的GPU慢)
如果在HSR处理不透明物体的过程中突然来了一个AlphaTest的图元,那么为了保证渲染结果正确,HSR就必须要终止当前的Defer,先把已标记好的像素都绘制出来,再进行后面的绘制。这显然严重影响了渲染的效率,也是为什么官方文档特意提到尽量避免AlphaTest的原因。相对应的AlphaBlend同样也要中断HSR的Defer,强制开始绘制,但是比AlphaTest好那么一点点的是他不影响后续图元并行地继续开始进行HSR处理。
最后总结下,在PowerVR上渲染,因为有HSR的存在我们只需要把所有不透明物体放到一起扔给GPU画就行了;在其他移动GPU上,同样也是要把所有不透明物体放到一起,但是还要先做个排序再交给GPU。
说一下alphaTest 究竟有多耗:
- 只要Shader中包含discard指令的都会被GPU认为是AlphaTest图元(GPU对于AlphaTest绘制流程的判定是基于图元而不是像素)
- 无论是PowerVR还是Mali/Adreno芯片,AlphaTest图元的绘制都会影响整体渲染性能。
- 随着芯片的发展AlphaTest图元对于渲染性能的影响主要在于Overdraw增加而非降低硬件设计流程效率,其优化思路与AlphaBlend一样,就是少画!
- 严格按照Opaque - AlphaTest - AlphaBlend的顺序进行渲染可以最大化减小AlphaTest对于渲染性能的影响。
- 将Opaque, AlphaTest与AlphaBlend打乱顺序渲染会极大的降低渲染性能,任何情况下都不应该这么做。
- 不要尝试使用AlphaTest替代AlphaBlend,这并不会产生太多优化。
- 不要尝试使用AlphaTest替代Opaque,这会产生负优化
- 不要尝试使用AlphaBlend替代AlphaTest,这会造成错误的渲染结果。
- 在保证正确渲染顺序情况下,AlphaTest与AlphaBlend开销相似,不存在任何替代优化关系
- 增加少量顶点以减少AlphaTest图元的绘制面积是可以提升一些渲染性能的。
- 首先统一绘制AlphaTest图元的DepthPrepass,再以ZTest Equal和不含discard指令的Shader统一绘制AlphaTest图元,大多数情况下是可以显著提升总体渲染性能的