Saiku查询缓慢问题追踪(三十三)
emmmmm..... 好久没有再处理saiku相关问题了,这两天用户突然提了一个mantis bug,说有个报表查询慢,导出更慢,且导出的时候甚至可能会报错~(无法导出相关数据) 。惊了,我在想 saiku用了这么久都还挺正常的呀,且其它报表都没有问题,怎么这个报表就不行呢.....
定位问题:
页面上点击查询那个有问题的报表,执行查询的时候没有问题,就是时间长,但是执行导出的时候就导不出数据....
>> 1. 一开始我是查看后台日志的,发现等了很久 日志并没有任何错误信息,过了很长时间后 页面竟然报错了...
>> 2. 然后就在前端debug,给出的结果是 Time-out ! 接口超时啦~
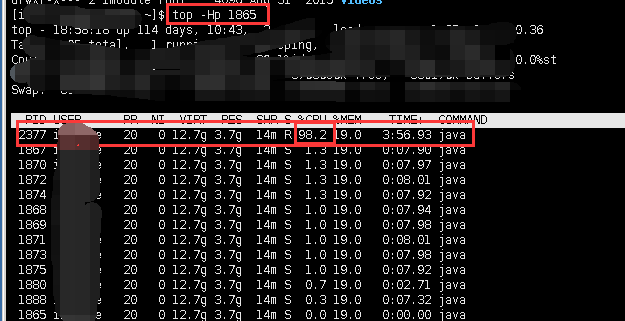
1.top命令 看看那个进程CPU使用率最高
top #得到PID 1865是CPU使用率过高的进程

2. 找到saiku的进程id
ps -ef|grep saiku #得到进程id为 1865 ,咦,巧了 刚好就是你! Saiku

3.进去看看是那个线程有问题,一直让CPU飙升,持续在100以上!!!
top -Hp 1865 #这里的1865就是我们saiku的进程id,从下图可以看出我们的是id为 2377 的那个线程在搞事情!!
4.jstack一下看看。(先把 2377 换成16进制 0x949 ,这便对应了jstack命令里面堆栈信息的nid,也就是线程id)
jstack 1865 >jstack_dump.log #将堆栈信息打印到当前目录的jstack_dump.log文件中,然后拿到本地看看
5.在 jstack_dump.log文件中全局搜索 nid=0x949 的线程堆栈信息
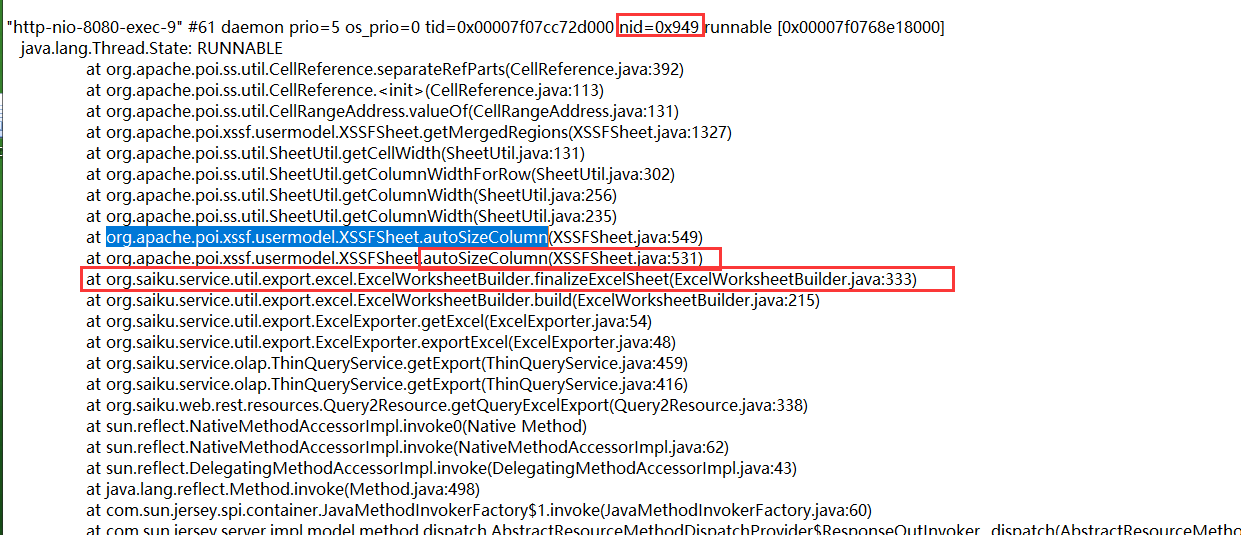
6.从以上堆栈可以明确定位问题代码啦
这是在数据导出Excel的时候有问题啦(org.saiku.service.util.export.excel.ExcelWorksheetBuilder)
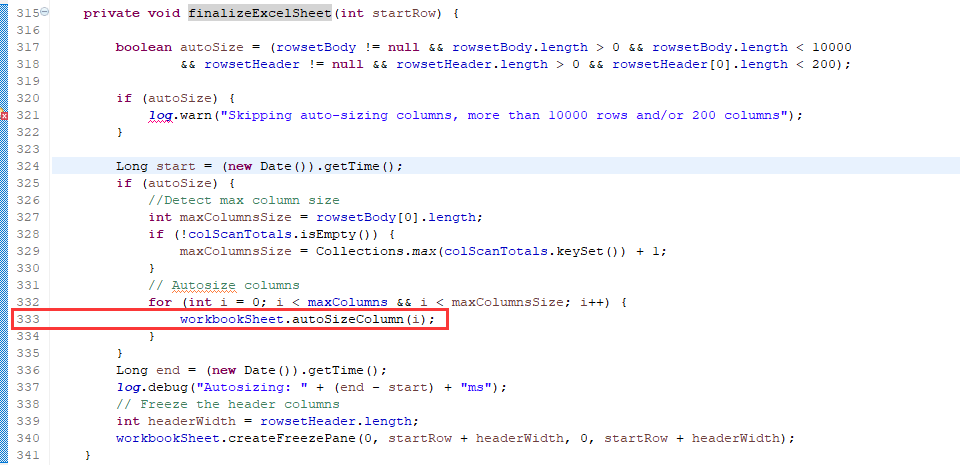
这里是调用 Sheet的 autoSizeColumn 方法,就是自适应列宽,卡在这里我就好奇了,为啥其它报表1w+的数据导出都没有问题,为什么这个报表3000+的数据就在这里卡住了呢
后来发现,是因为这个报表的格式有太多的自动合并了数据列了,导致在autoSizeColumn这一步的时候卡死了,其它报表是单独的行,规规矩矩的行数据信息,所以就没有这个问题。
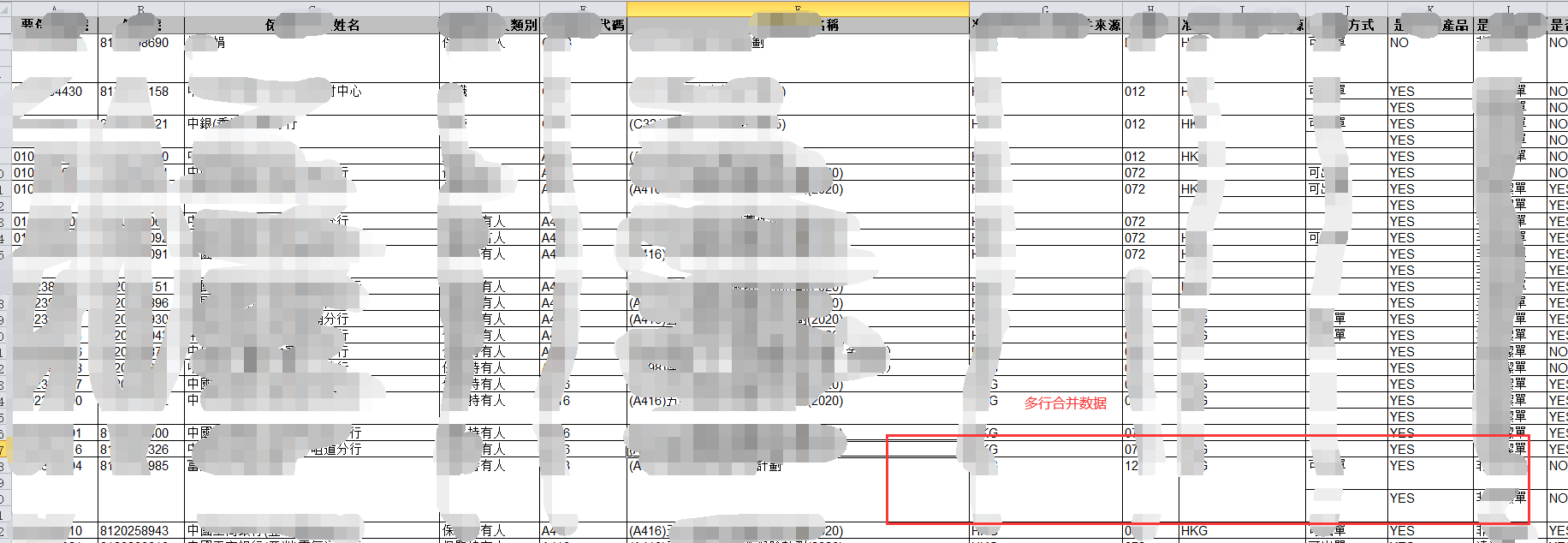
解决方案:
将最细的那列数据挪到报表的开头(直接在saiku里面拖拽到维度的第一个就可以了啦),这样子结果报表就不会自动合并了
再去查询或者导出就很快了,比之前快了7~8倍(查询),导出就更快了哈哈哈哈
其实最初的时候我在想是不是查询太慢了,就先查了数据库,发现这张表上竟然没有加索引,正常来说我们的报表数据都会按照日期查询,所以都会在日期字段上加索引的,然后我就先加了个索引,发现问题还是存在,就出现了如上步骤啦~(索引还是加了,查询也快了不少)