线性模型是机器学习中最简单的,最基础的模型结果,常常被应用于分类、回归等学习任务中。
回归和分类区别:
- 回归:预测值是一个连续的实数;
- 分类:预测值是离散的类别数据。
1. 线性模型做回归任务中----线性回归方法,常见的损失函数是均方误差,其目标是最小化损失函数。以下是均方误差表达式:
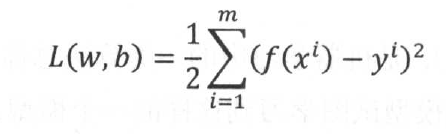
那么基于均方误差来求解模型的方法称为最小二乘法。
最小二乘法思想:寻找一个超平面,使得训练数据集中所有样本点到超平面的距离之和最小。
总结:
缺点与改进:线性回归是采用超平面来拟合所有的训练数据,但如果数据不呈线性分布关系时,线性模型得到的结果是欠拟合的(ps:欠拟合就时特征学习的不够)。如果解决欠拟合的问题,有两种方式:
第一种方法:挖掘更多的特征,比如不同的特征之间的组合,但这样做会使得模型更复杂,而且好的特征选取并不是一件简单的事;
第二种方法:通过修改线性回归,这时出现的方法是“局部加权线性回归(LWR)”,该方法使得我们在不添加新特征的前提下,获得近似的效果。该方法只需将损失函数修改为:

但是,LWR也有不足。最大的缺点是空间开销比较大,在线性回归模型中,当训练得到参数的最优解,就可以得到新数据的预测输出,但LWR除了保留参数得到最优解外,还要保留全部的训练数据,以求取每一个训练数据对应于新数据的权重值。
2. 线性模型来进行分类学习----Logistics回归:基本思想是在空间中构造一个合理的超平面,把空间区域划分为两个子控件,每一种类别都在平面的某一侧。
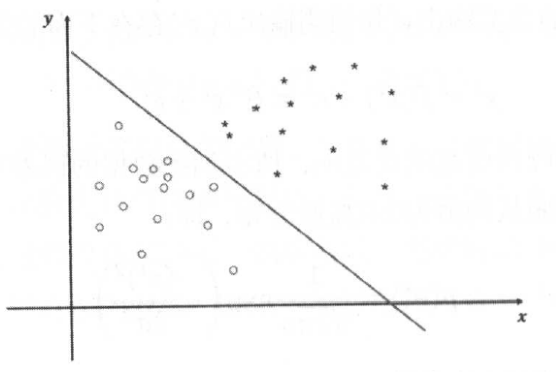
该算法一般采用的是Sigmoid函数:它可以将输入数据压缩到0到1的范围内,得到的结果不是二值输出,而是一个概率值,通过这个数值,可以查看输入数据分别属于0类或属于1类的概率。
特别地,以上两种线性模型,都是广义线性模型的特殊形式。