传送门:
# 官方网站 及 下载地址 https://www.mongodb.com/download-center/enterprise/releases
# 之前简单学习的笔记
http://www.cnblogs.com/CyLee/p/5886009.html
# window 下推荐使用 scoop 来安装 mongoDB
scoop install mongodb
快速入门使用:
1、手动新建db文件夹,路径c:datadb
2、进入mongodb/bin目录,或者将其加入到 Path 环境变量中,使用如下命令启动服务:
mongod --dbpath=c:datadb
3、在 bin 目录下找到 mongo.exe 打开,即可开始 mongo 旅程
4、测试代码
# 显示所有数据库的名字 show dbs
配置进阶:
默认window下安装的Mongodb环境是没有配置文件的。我们可以自定义,将上述的dbpath、Port等信息统一管理。这是强烈推荐的做法
在任意一个地方新建 mongodb.conf 文件。放入如下信息:
# 数据库路径 dbpath=C:datadb # 启用日志文件,默认启用 journal=true # 日志输出文件路径 logpath=C:datalog # 错误日志采用追加模式,配置这个选项后mongodb的日志会追加到现有的日志文件,而不是从新创建一个新文件 logappend=true # 这个选项可以过滤掉一些无用的日志信息,若需要调试使用请设置为false quiet=true # 端口号 默认为27017 port=27017
启动方式:mongod --config ./mongodb.conf
一些概念补充、深坑记录、碎片化知识点:
1、Mongodb 中集合的概念非常重要,可以理解为关系型数据库中表的概念。这样理解是有利于我们学习的。
在传统的SQL数据库中,需要做的第一件事是创建一个真正的数据库;
不过,在MongoDB中并不需要这么做,因为它将在第一次存储数据时自动创建数据库和集合
1、创建数据库 library
use library
在MongoDB shell 中输入 db 即可查看当前正在使用的数据库
2、插入数据
/** * @desc - 必须遵守的规则 * $字符不能是键名的第一个字符。 如$tag * 圆点"."不能出现在键名中。 如ta.gs * 尽量不要用_id作为键 * 空字符串不能作为键名 * 不要使用保留字符串作为集合名,如system, null 等敏感词汇 */
# 先创建临时变量 document = ({ "Type": "Book", "Title": "Mongodb从入门到入院", "ISBN":"978-1-4302-5821-6", "Publisher": "Aperss", "Author":["Houws","Eelco","Membrey","Tim"] })
# 然后再插入 db.media.insert( document )
# 也可以直接插入 db.media.insert({ "Type": "CD", "Title": "Nevermind", "Tracklist": [ { "Track": "1", "Title": "Smells Like Teen Spirit", "Length": "5: 02" }, { "Track": "2", "Title": "In Bloom", "Length": "4:15" } ] }) # 多插入几条测试数据 db.media.insert({"Type":"CD", "Artist":"Nirvana", "Title":"Nevermind"})
3、查询数据
# 查看当前数据库的所有集合
show collections
# 全查 media.find()
# 查看数量
db.users.find().size() # 按条件查 db.media.find({"Artist": "Nirvana"}) # 按条件查指定字段,结果将按升序显示。升序排序将基于文档的插入顺序 db.media.find({"Artist": "Nirvana"}, {Title: 1})
# 使用点号查询,对于复杂的文档结构很常用
db.media.find({"Tracklist.Title":"In Bloom"})
# 数组查询并不需要补全。只需要其中一个即可
db.media.find({"Author":"Eelco"})
# sort()进行排序
db.media.find().sort({Title: 1})
# limit(10) 查询前10个
db.media.find().limit(10)
# 跳过前20个
db.media.find().skip(20)
# 使用findOne()来搜索单一数据,他的使用方式和find()一致
db.media.findOne({Type:"Book"})
固定集合、自然顺序和$natural
1、创建固定集合
固定集合和标准集合对比:
-大小固定,一旦集合超出设置的大小,最老的数据(栈头)将被删除,最新的数据将会加入到末端(栈尾)。保证了数据的顺序。
- 需要手动创建
- 集合的大小不能改变,除非删除重建
- 不仅可以设置大小,还可以设置文档的数量,文档数量的执行判断限制权限,要比判断大小高。
# 创建一个名为 audit 的固定集合,它的大小不能超过 20480 大小
db.createCollection("audit", {capped:true, size:20480})
# 创建一个名为 audit100 的固定集合, 文档数量不得超过 100 并且 它的大小不能超过 20480 大小
db.createCollection("audit100", {capped: true, size:20480, max:100})
# 固定集合倒序查询必须使用$natural
db.audit.find().sort({$natural: -1}).limit(10)
# 查看集合
db.audit100.validate(true)
聚合命令
1、使用 count 返回文档数量
db.media.count()
db.media.find({Type:"Book"}).count()
2、使用 distinct() 函数返回唯一值
db.media.distinct("Title")
3、使用 group(key, initial, reduce) 将结果分组
函数group()目前在分片环境中无法正常工作。 因此,在这种环境中应该使用mapreduce()
另外,在group()函数输出的结果中包含的健不能超过10000个,否则会抛出异常。这样的情况也可以通过apreduce()来处理
group()函数将接受3个参数:key、initial 和 reduce.
- key: 指定希望使用哪个键对结果进行分组。例如,希望通过Title 对结果进行分组。
- initial: 允许为每个已分组的结果提供基数(元素开始统计的起始基数)。
- reduce: 接受两个参数:正在遍历的当前文档 和 聚集计数对象。
4、大小比较
$gt:大于 $gte:大于等于 $lt:小于 $lte:小于等于
# 大于
db.media.find({Released: {$gt: 2000} })
# 范围
db.media.find({Released: {$gte: 1990, $lt: 2010}})
5、$ne 除了指定条件以外的所有文档,下例中找出所有作者不是Eelco的图书
db.media.find({Type:"Book", Author: {$ne: "Eelco"}})
6、数组匹配 $in, 如果需要完全匹配,则使用$all
db.media.find({Released: {$in: [1999, 2008, 2009]}})
还有$nin , 既查找不存在数组中的值,这里不演示了
7、多个表达式 $or
# 任意一个表达式满足
db.media.find({$or: [{Title: "Toy Story 3"}, {"ISBN": "987-1-4302-3051-9"}]})
# 必须先通过第一个表达式
db.media.find({Type:"DVD", $or: [{Title: "Toy Story 3"}, {ISBN: "987-1-4302-3051-9"}]})
8、使用$slice获取文档
操作符$slice结合了$limit() 和 $skip() 的功能。
# 取出前3个 db.media.find({Title: "Matrix, the"}, {Cast: {$slice: 3}}) # 取出最后3个 db.media.find({Title: "Matrix, the"}, {Cast: {$slice: -3}}) # 从第三个开始,取出3个 db.media.find({Title: "Matrix, the"}, {Cast: {$slice: [2, 3]}}) # 忽略最后5个,限制输出4个 db.media.find({Title: "Matrix, the"}, {Cast: {$slice: [-5, 4]}})
9、探索求余 / 奇偶数
# 找出所有Released字段为偶数的文档 db.media.find({Released: {$mod: [2, 0]}}) # 找出所有Released字段为奇数的文档 db.media.find({Released: {$mod: [2, 0]}})
10、$size 通过过滤 数组长度 来搜索文档,如下例子,找出含两首歌曲的CD
db.media.find({Tracklist: {$size: 2}})
11、$exists 特定字段存在的情况下才返回文档, 如下例子,找出没有作者的CD
db.media.find({Author: {$exists: false}})
12、根据BSON类型来判断
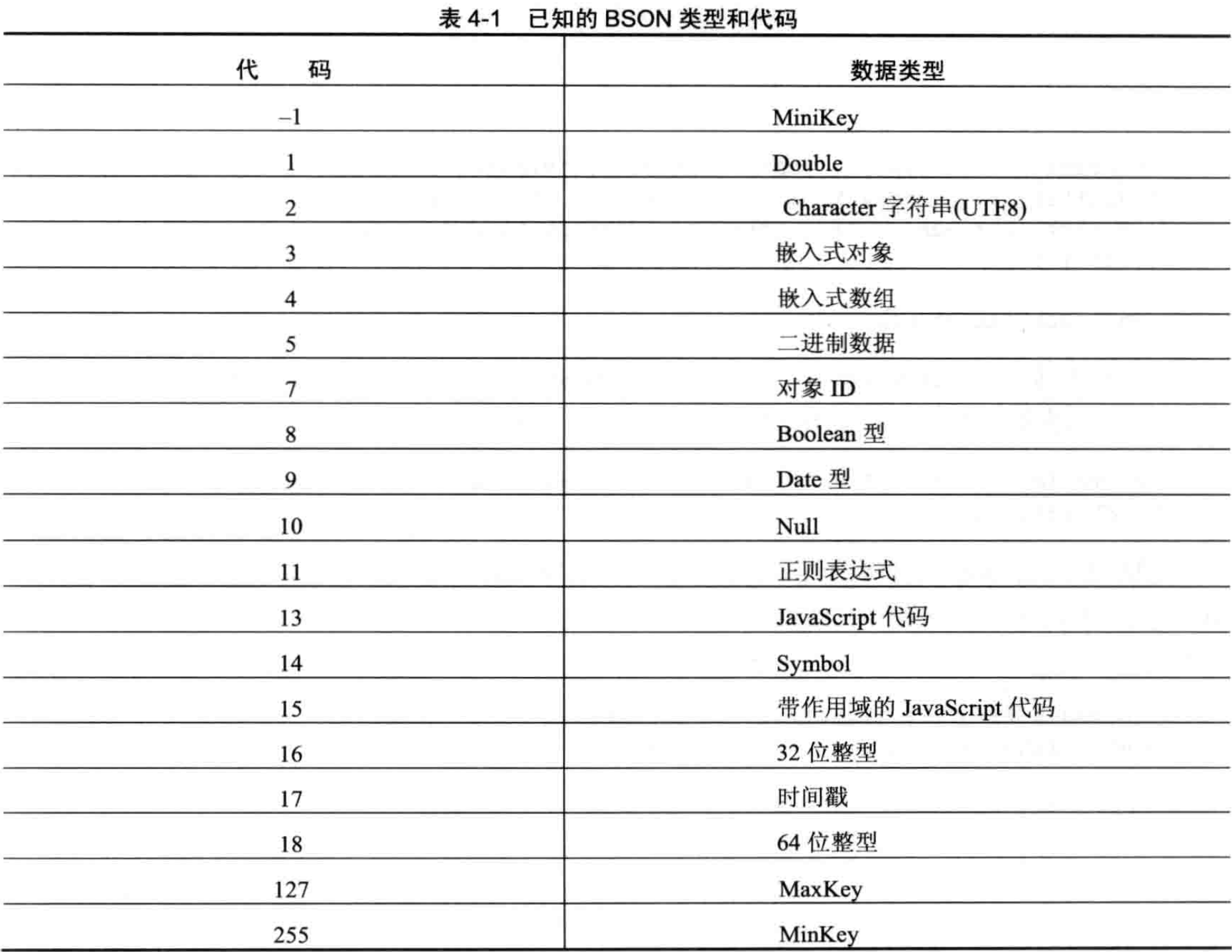
# 找出Tracklist为内嵌类型(Object)的文档 db.media.find({Tracklist: {$type: 3}})
13、使用javascript语法查询。特色是非常灵活非常js,缺点是比源生慢一点
# 直接查询
db.media.find("this.Released < 1995")
# 定义函数 + 使用函数查询
f = function () {return this.Released < 1995}
db.media.find(f)
更新数据
1、使用update()
它接受三个参数:1、查询条件 2、更新数据 3、可选项(upsert 和 multi)
upsert : 如果数据不存在则插入,如果存在就更新
multi: 默认只更新第一个文档。为true时更新所有文档
$set 操作符将某个字段设置为指定值
db.media.update({Title: "Matrix, the"}, {$set: {Type: "DVD", Title: "Matrix,The", Released: 1999, Genre: "Action"}},{upsert: true, multi: true})
也可以用 save() 来实现upsert() . 它的用法和uodate() 很相似,区别仅仅在于省略第三个可选项参数
db.media.update({Title: "Matrix, the"}, {Type: "DVD", Title: "Matrix,The", Released: 1999, Genre: "Action"})
2、使用 $inc 快速增值或者减值
db.media.update({Title: "Toy Story 3"}, {$inc: {Released: 4}})
db.media.update({Title: "Toy Story 3"}, {$inc: {Released: -4}})
3、删除字段
# 删除了 Released 字段
db.media.update({Title: "Toy Story 3"}, {$unset: {Released: 1}})
4、remove() 删除数据
# 删除所有数据
db.users.remove({})
# 按条件删除 db.documents.remove({"a": 1}) # 使用javascript删除 db.documents.remove("this.a < 4")
5、添加字段与值
db.media.update({Title: "Toy Story 3"}, {$push: {"Author": "Lee"}})