LeNet-5结构分析及caffe实现————卷积部分
1、lenet-5的结构以及部分原理
2、caffe对于lenet-5的代码结构
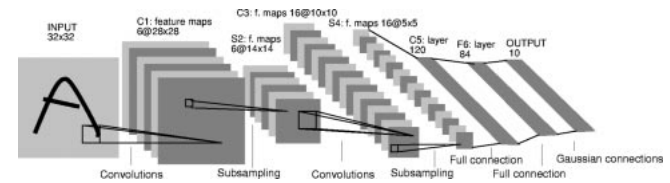
图一
图一是整个LeNet-5的结构图,要点有:convolutions、subsampling、full connection、gaussian connection。
要点拆分:
1、convolution 是卷积操作,对应的概念有卷积核、特征图、权值共享。

图二
图二表示CNN中卷积操作。对卷积的要点解释:1、红色框内为2*2卷积核。2、蓝色框内为3*4的输入图像。3、绿色框为3*3的特征图。注意:绿框中未包含偏置项。如加入偏置项则每个输出多加上同一个偏置B,此时类似如:aw+bx+ey+fz+B bw+cx+fy+gz+B等。所谓的权值共享是每个卷积运算使用同一个卷积核,在上图中使用的是同一个卷积核,即共享权值。
卷积的优势:1、sparse interactions 2、parameter sharing 3、equivariant respections
sparse interactions————》》图三是效果图。蓝色框中是全连接神经网络,红色框是卷积网络。
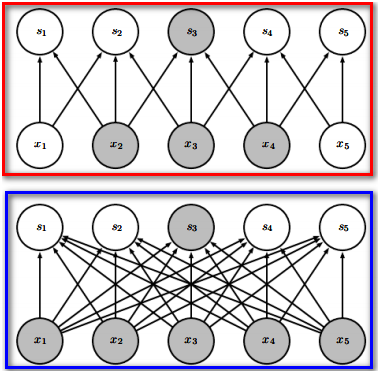
图三
卷积相对于全连接是稀疏的。优势:1、参数更少 2、计算量降低。那么效果比较呢?

图四
图四是多层结构的联系图,可知通过增加网络层数,保留全局的特征。
parameter sharing————》》在图二部分已经分析完毕。优势:同样是减少了参数量。
equivariant respections——————》》当输入图像通过平移后,卷积的结果也会平移。
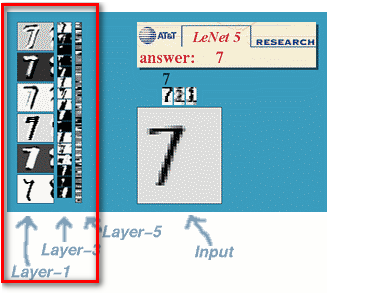

如上所示:数字7从右向左平移,对应红色框里的layer-1也进行了平移。同时注意:单就卷积操作而言,这种等变换在缩放、旋转上是不成立的。
对比:整个CNN操作(包括卷积层以及后面的层),主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。
参考:
《Deep Learning》Ian Goodfellow,Yoshua Bengio,AND Aaron Courville
《Gradient-Based Learning Applied to Document Recognition》YANN LECUN, MEMBER, IEEE, LEON BOTTOU, YOSHUA BENGIO, AND PATRICK HAFFNER
http://yann.lecun.com/exdb/lenet/index.html