空值清洗 - 处理丢失数据
常见的两种空值数据(丢失数据)
None
np.nan(NaN)
None
None是python自带的,其类型为python object .因此,None不能参与到任何计算中
type(None) #NoneType Npne + 1 #报错
np.nan(NaN)
np.nan是浮点型,能参与计算,但计算的结果总是NaN
import numpy as np type(np.nan) #浮点型 float np.nan + 1 #nan
pandas中的None 与 NaN
import numpy as np import pandas as pd from pandas import Series,DataFrame """pandas 中 None 与 np.nan都视作 np.nan"""
首先创建一个DataFrame
#创建DataFrame数据 df = DataFrame(data=np.random.randint(0,100,size=(10,12))) #将某些数组元素赋值为nan df.iloc[1,1] = None df.iloc[2,4] = None df.iloc[4,4] = None df.iloc[2,8] = None df.iloc[3,5] = np.nan df
效果如下:制造出存在NaN的元素
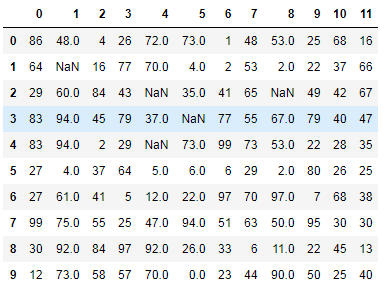
现在把存在空值的行删除
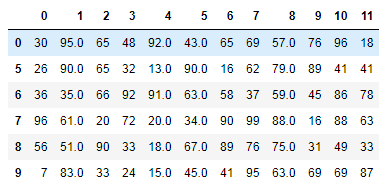
"""将对应行的空值删除""" '''方式1''' # 步骤1 找到空值 df.isnull().any(axis=1) #isnull 搭配 any 使用 # df.notnull().all(axis=1) #notnull 搭配 all使用 两者效果相同 #步骤2 删除空值 drop_index = df.loc[df.isnull().any(axis=1)].index # drop_index = df.loc[~(df.notnull().all(axis=1))].index # df.drop(labels=drop_index,axis=0) #drop方式删除,axis 应用正好相反. '''方式2''' df.dropna() # 默认删除行 axis = 0 ,参数可写可不写
结果如下:
这里必须补充下axis参数的应用
# 常规使用 axis = 1 表示行 axis = 0 表示列 # 但在drop系列中应用正好相反 df.drop(axis = 0) #这里表示删除行
pandas处理空值操作
dropna() 过滤丢失数据
df.dropna(axis=0) #可以选择过滤的是行/列(默认为行),axis在drop中 0 为行,1为列
fillna() 填充丢失数据
# fillna() value和method参数 """主要是 method 中bfill与ffill的使用""" bfill 向后填充 ffill 向前填充 df.fillna(method='bfill',axis=0)
针对上述数据稍微改动
df.iloc[0,1] = None df.iloc[2,1] = None df
改成如下效果数据
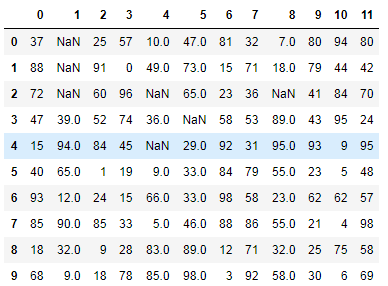
bfill 向后填充
df.fillna(method='bfill',axis=0) #按照列向后填充,将NaN对应的列后面的数据填充NaN
效果如下 :
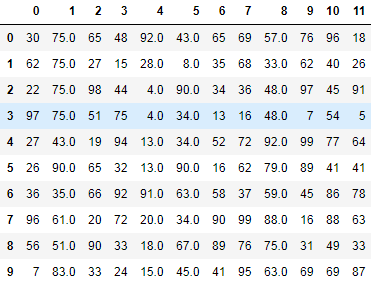
ffill 向前填充
#ffill 向前填充 df.fillna(method='ffill',axis=0)
效果如下 :
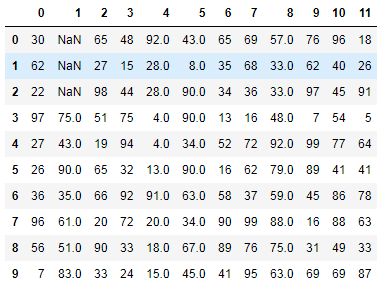
通过观察发现,除了第2列连续3个NaN元素数据没有被填充成功,其他都被前面的数据填充了,这是因为NaN的前面全是NaN导致的.如果前面(注意并不是前1个数据,NaN的前面都算)一旦不是空值数据,NaN就会被填充成功
数据的拼接与合并
pandas的拼接分为两种:
- 级联:pd.concat | pd.append
- 合并:pd.merge | pd.join
pd.concat() 级联
#pandas使用pd.concat函数 与 np.concatenate()函数相似,只是多了参数 abjs axis=0 keys join = 'outer'/ 'inner' 表示级联的方式,outer会将所有项进行级联(忽略匹配和不匹配), 而inner只会讲匹配的项级联,不匹配的不级联 ignore_index=False
1. 匹配级联
df1 = DataFrame(data=np.random.randint(0,100,size=(3,3)),index=['a','b','c'],columns=['A','B','C']) df2 = DataFrame(data=np.random.randint(0,100,size=(3,3)),index=['a','e','c'],columns=['A','E','C'])
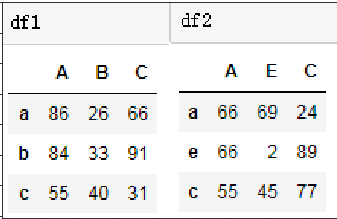
代码展示
pd.concat((df1,df1),axis=0,join='inner') #列内联 pd.concat((df1,df2),axis=0,join='outer') #B,E列没有匹配outer属性级联就会补空值,在实际中我们用outer,因为我们要保证数据的完整性,用inner的话数据就被删除了
2. 不匹配级联
""" 不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致 有2种连接方式: 外连接:补NaN(默认模式) 内连接:只连接匹配的项 """
3. 使用df.append()
df1.append(df2) #跟concat outer相似,不常用
4. 总结 :级联就是将两张表纵向和横向与列的拼接
数据合并
一对一合并
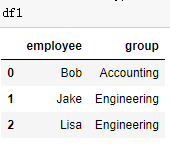
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering'],
})
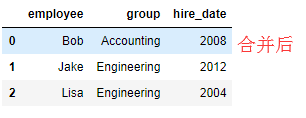
df2 = DataFrame({'employee':['Lisa','Bob','Jake'],
'hire_date':[2004,2008,2012],
})
pd.merge(df2,df1,how='outer',on='employee') #相当于做了数据汇总,合并了数据
#其中on参数写不写都可以,默认共有条件合并

多对一合并
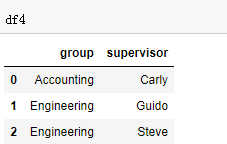
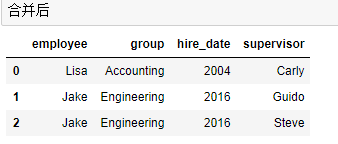
df3 = DataFrame({ 'employee':['Lisa','Jake'], 'group':['Accounting','Engineering'], 'hire_date':[2004,2016]}) df4 = DataFrame({'group':['Accounting','Engineering','Engineering'], 'supervisor':['Carly','Guido','Steve'] }) pd.merge(df3,df4,how='outer') #Engineering对应有两个supervisor

多对多合并
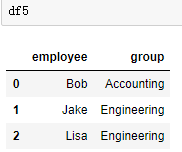
df5 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering']})
df6 = DataFrame({'group':['Engineering','Engineering','HR'],
'supervisor':['Carly','Guido','Steve']
})
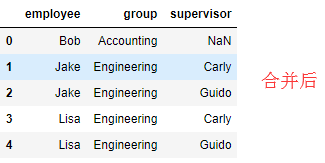
pd.merge(df5,df6,how='left') #内联接只能连接能够连接的数据,外连接都合并,左连接包含左表所有数据,右连接一定包含右表所有数据

key的规范化
① 当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个列作为key,配合suffixes指定冲突列名
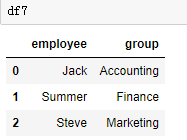
df7 = DataFrame({'employee':['Jack',"Summer","Steve"],
'group':['Accounting','Finance','Marketing']})
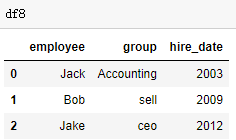
df8 = DataFrame({'employee':['Jack','Bob',"Jake"],
'hire_date':[2003,2009,2012],
'group':['Accounting','sell','ceo']})
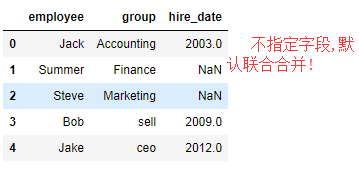
1. pd.merge(df1,df2,how='outer') #默认 employee 和group联合合并
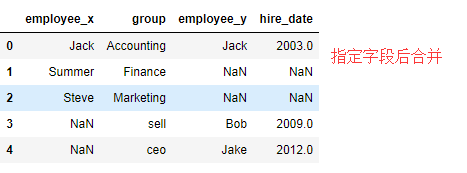
2. pd.merge(df1,df2,how='outer',on='group') #合并结构将employee分成两列,通过suffixes参数可以改列名
② 当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列
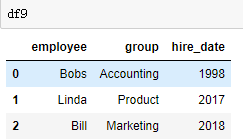
df9 = DataFrame({'employee':['Bobs','Linda','Bill'],
'group':['Accounting','Product','Marketing'],
'hire_date':[1998,2017,2018]})
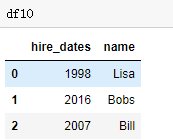
df10 = DataFrame({'name':['Lisa','Bobs','Bill'],
'hire_dates':[1998,2016,2007]})
pd.merge(df9,df10,left_on='employee',right_on='name')
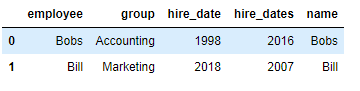
....