scrapy框架基础
- 框架 : 具有很多功能,且具有很强通用性的项目模板
- 环境安装 :
#环境准备 linux 系统 pip3 install scrapy windows系统 1 pip3 install wheel 2 下载 Twisted-19.2.0-cp36-cp36m-win-amd64.whl 3 进入下载目录,执行 pip3 install Twisted‑19.2.0‑cp36‑cp36m‑win_amd64.whl 4 pip3 install pywin 5 pip3 install wheel
什么是scrapy?
Scrapy 是一个为了爬取网站数据,提取结构性数据编写的应用框架,.非常强大,所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。对于框架的学习,重点是要学习其框架的特性、各个功能的用法即可。
scrapy的用法
#创建一个爬虫工程 scrapy startproject projectName #cd proName #创建爬虫文件 scrapy genspider first www.xxx.com #执行工程 scrapy crawl spiderName #执行对应的爬虫应用 scrapy crawl spiderName --no log #忽略日志输出
Scrapy目录结构
#项目结构: project_name/ scrapy.cfg: project_name/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py scrapy.cfg #项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中) items.py #设置数据存储模板,用于结构化数据,如:Django的Model pipelines #数据持久化处理 settings.py #配置文件,如:递归的层数、并发数,延迟下载等 spiders #爬虫目录,如:创建文件,编写爬虫解析规则
Scrapy 写法说明
# -*- coding: utf-8 -*- import scrapy class FirstSpider(scrapy.Spider): #爬虫文件的名称:就是爬虫文件的一个唯一标示 name = 'first' #允许的域名 # allowed_domains = ['www.xxx.com'] #一般不用 #起始url列表:列表元素都会被自动的进行请求的发送 start_urls = ['https://www.qiushibaike.com/text/'] #解析数据 def parse(self, response): div_list = response.xpath('//div[@id="content-left"]/div') names = [] for div in div_list: #特性:xpath返回的列表元素一定是Selector对象,使用extract()就可以获取Selecot中data的数据 # author = div.xpath('./div[1]/a[2]/h2/text()')[0].extract() author = div.xpath('./div[1]/a[2]/h2/text()').extract_first() #在基于终端指令进行持久化存储的时候必须将解析到的数据封装到字典中 dic = { 'name':author } names.append(dic) return names
Scrapy初始配置
#修改内容及其结果如下: 19行:USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' #伪装请求载体身份 22行:ROBOTSTXT_OBEY = False #可以忽略或者不遵守robots协议
LOG_LEVEL
scrapy应用
了解五大核心组件
Scrapy使用了Twisted异步网络库来处理网络通讯,整体架构如下
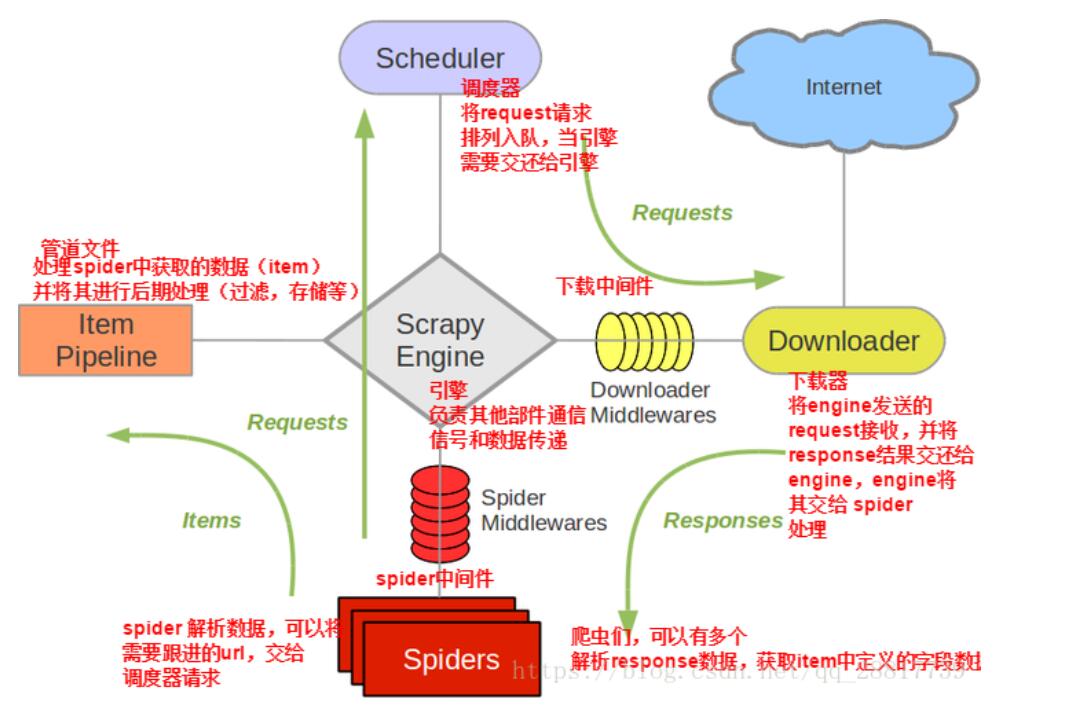
scrapy组件介绍:
引擎(Engine) : 用来处理整个系统的数据流,触发事务(框架的核心)
调度器(Scheduler) : 用来接收引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回,可以想象成一个url的优先队列,由它来决定下一个要抓取的网址是什么,同时去处重复的网址
下载器(Downloader) : 用于下载网页内容,并将网页内容返回给spiders(下载器是建立在Twisted这个高效的异步模型上的)
爬虫文件(Spiders) : 爬虫是主要进行从特定的网页中提取自己需要的信息,即所谓的实体(item),用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
管道(Pipeline) : 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体,验证实体的有效性,清除不需要的信息,当页面被爬虫解析后,将发送到项目管道,并经过几个特定的次序处理数据
scrapy三个中间件
下载器中间件 : 位于scrapy引擎和下载器之间的框架,主要处理scrapy引擎和下载器之间的请求和响应
#作用 批量拦截请求和响应 #拦截请求: 1.篡改请求头信息(User-Agent) 2.设置相关请求对象的代理ip(process_exception中) #三个方法 1.process_request ---> 拦截所有非异常的请求 2.process_response ---> 拦截所有响应对象 3.process_exception ---> 拦截发生异常的请求对象,需要对异常请求对象进行相关处理,让其变成正常的请求对象,然后通过return request 对该请求进行重新发送
爬虫中间件 : 位于scrapy引擎和爬虫文件之间的框架,主要工作是处理爬虫的响应输入和请求输出
调度中间件 : 介于scrapy 引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应
Scrapy运行流程
- 引擎从调度器中取出一个url用于接下来的抓取
- 引擎把url封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步处理
- 解析出的链接url,则把url交给调度器等待抓取
Scrapy持久化存储实现流程
- 基于终端指令 :
只可以将parse方法的返回值存储在磁盘文件中,解析的内容结构必须为字典
scrapy crawl first -o qiubai.csv #指定文件类型有要求.json .csv
- 基于管道 :
- 数据解析
- 封装item类
- 实例化item类型的对象
- 将解析倒的数据依次存储封装到item类型的对象中
- 将item对象提交给管道
- 在管道中实现IO操作
- 开启管道
注意事项如下:
#注意事项主要是数据存储 将同一份数据存储到不同的平台中: 1. 管道文件中一个管道类负责将item存储到某一个平台中 2. 配置文件中设定管道类的优先级 3. process_item方法中 return item 的操作将item传递给下一个类


#爬取校花网 #持久化存储 三种数据库的配置和写入 xiaohua.py # -*- coding: utf-8 -*- import scrapy from xiaohuaPro.items import XiaohuaproItem class XiaohuaSpider(scrapy.Spider): name = 'xiaohua' # allowed_domains = ['http://www.521609.com/'] start_urls = ['http://www.521609.com/daxuemeinv/'] #生成通用的url模板 url = "http://www.521609.com/daxuemeinv/list8%d.html" page_num = 1 #详情页数据抓取 def parse_detail(self,response): pass def parse(self, response): li_list = response.xpath("//div[@class='index_img list_center']/ul/li") for li in li_list: name = li.xpath("./a[2]/text() | ./a[2]/b/text()").extract_first() img_url = "http://www.521609.com/" + li.xpath("./a[1]/img/@src").extract_first() #实例化一个item对象 item = XiaohuaproItem() item['name'] = name item['img_url'] = img_url #item 提交给管道 yield item #全站数据爬取,分页操作 :手动请求发送 #对其他页面的url进行手动请求发送 if self.page_num<= 3: self.page_num += 1 new_url = format(self.url%self.page_num) yield scrapy.Request(url=new_url,callback=self.parse) pipeline.py #持久化存储到mysql,redis,mongodb,文件 # -*- coding: utf-8 -*- import pymysql import pymongo from redis import Redis from scrapy.conf import settings #作用:将解析到的数据存储到某一个平台中 class XiaohuaproPipeline(object): fp = None def open_spider(self,spider): print('开始爬虫') self.fp = open('./xiaohua.txt','w',encoding='utf-8') #作用:实现持久化存储的操作,凡是涉及到持久化存储都得写到该方法中 #对象可以数据存储, #该方法的参数item就可以接受爬虫文件提交的过来的item对象 #该方法没接收一个item就会被调用一次 def process_item(self, item, spider): name = item['name'] img_url = item['img_url'] self.fp.write(name+':'+img_url+" ") return item #返回值的作用:就是将item传递给下一个类 def close_spider(self,spider): print('关闭爬虫') self.fp.close() class MySQLPipeline(object): conn = None cursor = None def open_spider(self,spider): self.conn = pymysql.Connect(host="127.0.0.1",port=3306,user="feige",password='keke',db='xiaohua') print(self.conn) def process_item(self,item,spider): self.cursor = self.conn.cursor() try: self.cursor.execute("insert into xiaohua values ('%s','%s')"%(item['name'],item['img_url'])) self.conn.commit() except Exception as e: print(e) self.conn.rollback() return item def close_spider(self, spider): self.cursor.close() self.conn.close() class RedisPipeline(object): conn = None def open_spider(self,spider): self.conn = Redis(host="127.0.0.1",port=6379) print(self.conn) def process_item(self,item,spider): dic = { "name":item['name'], "img_url":item['img_url'] } print(item['name']) self.conn.lpush('xiaohua',str(dic)) return item def close_spider(self, spider): pass class MongoDBPipeline(object): conn = None def __init__(self): host = settings['MONGODB_HOST'] port = settings['MONGODB_PORT'] db_name = settings['MONGODB_NAME'] client = pymongo.MongoClient( host=host,port=port ) db = client[db_name] self.post = db[settings['MONGODB_COLLECTION']] def open_spider(self,spider): pass def process_item(self,item,spider): house_info = dict(item) self.post.insert(house_info) return item def close_spider(self, spider): pass settings.py配置 ITEM_PIPELINES = { 'xiaohuaPro.pipelines.XiaohuaproPipeline': 300, #300优先级,数值越小,优先级越高 'xiaohuaPro.pipelines.MySQLPipeline': 301, #300优先级,数值越小,优先级越高 'xiaohuaPro.pipelines.RedisPipeline': 302, #300优先级,数值越小,优先级越高 'xiaohuaPro.pipelines.MongoDBPipeline': 303, #300优先级,数值越小,优先级越高 } #关于mongodb的配置 MONGODB_HOST = "127.0.0.1" MONGODB_PORT = 27017 MONGODB_NAME = "scrapy_xiaohua" MONGODB_COLLECTION = "item" items.py class XiaohuaproItem(scrapy.Item): name = scrapy.Field() #返回定义的属性,name就是一个属性 img_url = scrapy.Field() #为什么用Field定义?理解:存储万能的类型数据
# -*- coding: utf-8 -*- import scrapy class BaidufayiSpider(scrapy.Spider): name = 'baidufayi' # allowed_domains = ['www.xxx.com'] start_urls = ['https://fanyi.baidu.com/sug'] #引擎触发方法,默认get请求,重写post请求 def start_requests(self): # start_ requests 固定写法 data = { 'kw':'dog' } for url in self.start_urls: #FromRequest 通过这个方法即可发送post请求 yield scrapy.FormRequest(url=url,callback=self.parse,formdata=data) def parse(self, response): print(response.text) #scrapy 默认发送get请求,但是也可以重写post请求的方法,如果爬取post请求数据不建议使用scrapy框架,直接使用requests模块会更便捷
Scrapy递归解析(全站数据爬取)
- 手动请求的发送:
1. 设定一个通用的url模板
2. 手动请求的操作:parse方法
3. yield scrapy.Request(url,callback)
# -*- coding: utf-8 -*- import scrapy from qiushibaike.items import QiushibaikeItem # scrapy.http import Request class QiushiSpider(scrapy.Spider): name = 'qiushi' allowed_domains = ['www.qiushibaike.com'] start_urls = ['https://www.qiushibaike.com/text/'] #爬取多页 pageNum = 1 #起始页码 url = 'https://www.qiushibaike.com/text/page/%s/' #每页的url def parse(self, response): div_list=response.xpath('//*[@id="content-left"]/div') for div in div_list: #//*[@id="qiushi_tag_120996995"]/div[1]/a[2]/h2 author=div.xpath('.//div[@class="author clearfix"]//h2/text()').extract_first() author=author.strip(' ') content=div.xpath('.//div[@class="content"]/span/text()').extract_first() content=content.strip(' ') item=QiushibaikeItem() item['author']=author item['content']=content yield item #提交item到管道进行持久化 #爬取所有页码数据 if self.pageNum <= 13: #一共爬取13页(共13页) self.pageNum += 1 url = format(self.url % self.pageNum) #递归爬取数据:callback参数的值为回调函数(将url请求后,得到的相应数据继续进行parse解析),递归调用parse函数 yield scrapy.Request(url=url,callback=self.parse)
Scrapy日志等级
当我们在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息。
日志等级
#日志等级,种类 ERROR : 一般错误 WARNING : 警告 INFO : 一般的信息 DEBUG : 调试信息
在配置文件中设置指定输出
#在settings.py配置文件中,加入 LOG_LEVEL = "ERROR" --- 日志等级 LOG_FILE = "log.txt" --- 表示日志文件路径进行存储
Scrapy请求传参的应用场景:
- 爬取且解析的数据没有在同一张页面中
- 在请求方法中使用meta(字典)参数,该字典会传递给回调函数,回调函数会接收 meta : response.meta["key"]
Scrapy中如何给所有请求对象尽可能多的设置不一样的请求载体身份标识?
开启UA池,process_request方法中写入定义好的UA池
Scrapy中如何给发生异常的请求设置代理IP?
IP池,process_exception(_request,response,spider): request.meta['proxy'] = "http://ip:port"
将异常的请求拦截之后,通过代理ip相关操作,就可以改异常的请求变成非异常请求,对该请求进行重新请求发送, :return request
如何提高scrapy的爬取效率
1. 增加并发 #默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100。 2 .降低日志级别 #在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:LOG_LEVEL = ‘INFO’ 3. 禁止cookie #如果不是真的需要cookie,则在scrapy爬取数据时可以进制cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:COOKIES_ENABLED = False 4 . 禁止重试 #对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:RETRY_ENABLED = False 5. 减少下载超时: #如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:DOWNLOAD_TIMEOUT = 10 超时时间为10s
crawlSpider全站数据爬取
创建爬虫文件方式
scrapy genspider -t crawl spiderName www.xxx.com
连接提取器 : 可以根据指定规则进行连接的提取
规则解析器: 根据指定规则进行响应数据的解析
如下代码备注表名具体参数说明
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class CrawlSpider(CrawlSpider): name = 'c' # allowed_domains = ['www.xxx.com'] start_urls = ['https://www.qiushibaike.com/text/'] #连接提取器:可以根据指定规则进行连接的提取 #allow表示的就是提取连接规则:正则 link = LinkExtractor(allow=r'') link1 = LinkExtractor(allow=r'/text/') rules = ( #规则解析器:根据指定规则进行响应数据的解析 #follow:将连接提取器继续作用到连接提取器提取出的连接所对应的页面源码中 Rule(link, callback='parse_item', follow=True), Rule(link1, callback='parse_item'), ) #回调函数调用的次数是由连接提取器提取连接个数决定 def parse_item(self, response): print(response)
Selenium如何作用在scrapy中,编码流程?
应用: 当页面数据动态加载,就需要使用selenium
编码流程:
#编码流程
- 实例化一个浏览器对象(只实例化1次):spider 的init方法 - 需要编写浏览器自动化的操作(中间件的process_response) - 关闭浏览器(spider的closed方法中进行关闭操作)
spider.py class WangyiSpider(RedisSpider): name = 'wangyi' #allowed_domains = ['www.xxxx.com'] start_urls = ['https://news.163.com'] def __init__(self): #实例化一个浏览器对象(实例化一次) self.bro = webdriver.Chrome(executable_path='/Users/bobo/Desktop/chromedriver') #必须在整个爬虫结束后,关闭浏览器 def closed(self,spider): print('爬虫结束') self.bro.quit() #中间件文件 from scrapy.http import HtmlResponse #参数介绍: #拦截到响应对象(下载器传递给Spider的响应对象) #request:响应对象对应的请求对象 #response:拦截到的响应对象 #spider:爬虫文件中对应的爬虫类的实例 def process_response(self, request, response, spider): #响应对象中存储页面数据的篡改 if request.url in['http://news.163.com/domestic/','http://news.163.com/world/','http://news.163.com/air/','http://war.163.com/']: spider.bro.get(url=request.url) js = 'window.scrollTo(0,document.body.scrollHeight)' spider.bro.execute_script(js) time.sleep(2) #一定要给与浏览器一定的缓冲加载数据的时间 #页面数据就是包含了动态加载出来的新闻数据对应的页面数据 page_text = spider.bro.page_source #篡改响应对象 return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8',request=request) else: return response #settings.py DOWNLOADER_MIDDLEWARES = { 'wangyiPjt.middlewares.WangyiproDownloaderMiddleware': 543, }
....