前言
缓存文件置换的原因是电脑存储器空间固定,不可能将服务器上所有数据都加载在存储空间中,当需要调用不用的数据时,那么势必需要将需要的数据进来存储空间替换原有数据
常见的缓存文件置换方法有:
先进先出算法(FIFO):最先进入的内容作为替换对象
最久未使用算法(LRU):最久没有访问的内容作为替换对象
最近最少使用算法(LFU):最近最少使用的内容作为替换对象
非最近使用算法(NMRU):在最近没有使用的内容中随机选择一个作为替换对象
内存的平均引用时间为:
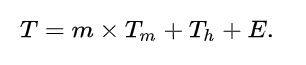
其中
- T= 内存平均引用时间
- m= 未命中率 = 1 - (命中率)
- Tm= 未命中时访问主内存需要的时间 (或者在多层缓存中对下级缓存的访问时间)
- Th= 延迟,即命中时引用缓存的时间
- E= 各种次级因素, 如多处理器系统中的队列效应
衡量缓存的指标主要有两个:延迟和命中率。同时也存在其他一些次级因素影响缓存的性能。
缓存的命中率是指需要的对象在缓存中被找到的频率。 高效的置换策略会保留较多的实用信息来提升命中率(在缓存大小一定的情况下)。
缓存的延迟是指命中后,从发出请求到缓存返回指定对象所需的时间。 快速的置换策略通常会保留较少的置换信息,甚至不保留信息,来减少维护该信息所需要的时间。
每种置换策略都是在命中率和置换之间妥协。
先进先出算法(FIFO)
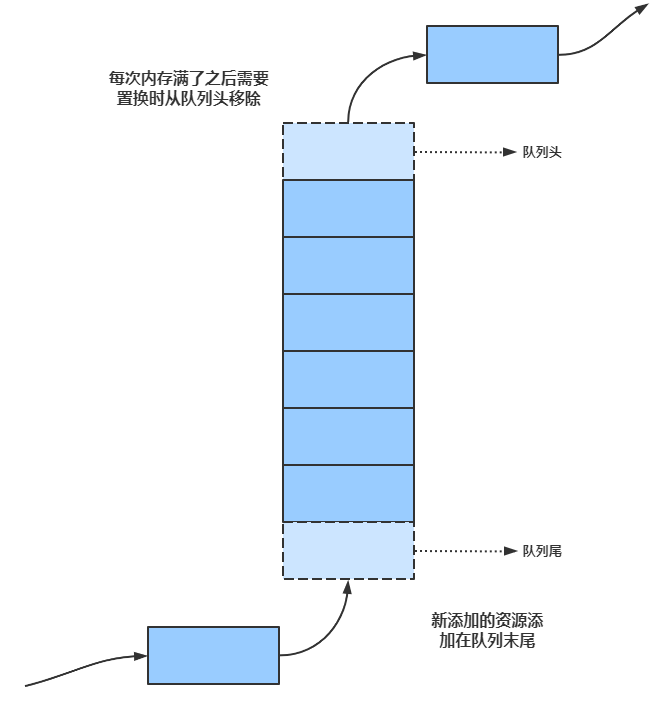
如上图,在一个队列中,如果队列未满,添加资源时添加在末尾,如果队列资源已经满了,那么再添加资源时需要先将队列头部的资源移除,腾出空间后再将待添加的资源加至队列尾。
代码实现:
public class FIFO implements Cacheable {
private int maxLength = 0;
private Queue<Object> mQueue = null;
public FIFO(int _maxLength) {
... ...
}
@Override
public void offer(Object object) {
if (mQueue == null) {
throw new NullPointerException("策略队列对象为空");
}
// check is need swap or not
if (mQueue.size() == maxLength) {
clean();
}
mQueue.offer(object);
}
@Override
public void visitting(Object object) {
System.out.println("Visited " + object);
}
private void clean() {
mQueue.poll();
}
}
最久未使用算法(LRU)
最久未使用算法图示:
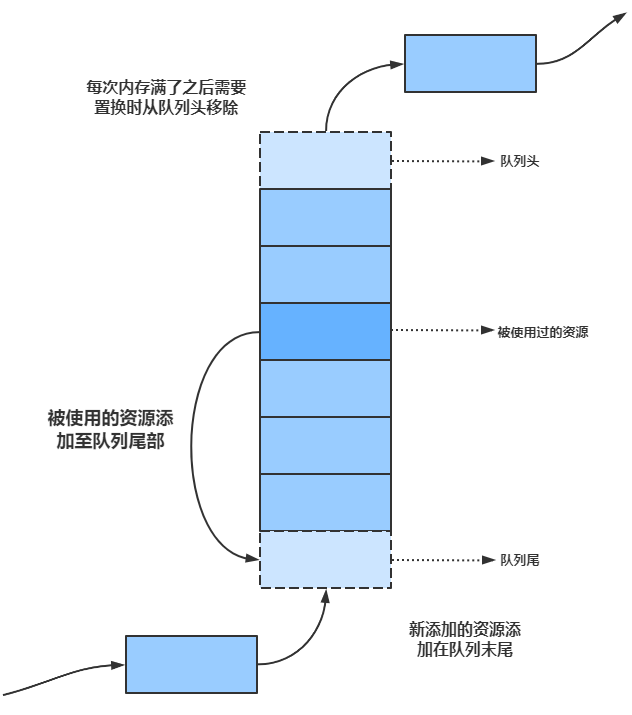
对比FIFO原理图和LRU原理图,可以很明显地看到只是在被使用的资源部分有一些小的改动。在一般地使用过程中,和FIFO一样,如果队列还未满时,我们可以随意加入,当队列缓存的数据满了的时候,我们一样地从队列的尾部加入,从队列的头部移除了。当我们要访问一个资源的时候,就把这个资源移动到队列的尾部,让这个资源看上去就像最新添加的一样。这个就是我们LRU算法的核心了。
代码:
public class LRU implements Cacheable {
private int maxLength = 0;
private Queue<Object> mQueue = null;
public LRU(int _maxLength) {
... ...
}
@Override
public void offer(Object object) {
if (mQueue == null) {
throw new NullPointerException("策略队列对象为空");
}
// check is need swap or not
if (mQueue.size() == maxLength) {
clean();
}
mQueue.offer(object);
}
@Override
public void visitting(Object object) {
if (mQueue == null || mQueue.isEmpty()) {
throw new NullPointerException("访问对象不存在");
}
System.out.println("Visited " + object);
displace(object);
}
// remove the longer no visit
private void clean() {
mQueue.poll();
}
// cache core code
private void displace(Object object) {
for (Object tmp : mQueue) {
if (object.equals(tmp)) {
mQueue.remove(tmp);
break;
}
}
mQueue.offer(object);
}
}
LRU算法改进版 LRU-K
LRU-K图示

算法简介:
主要思想是统计一下对象加载的频率,达到设定的K值之后才进入缓存,进入缓存之后实行最久未使用(LRU)淘汰策略。
LRU算法中存在的问题:
LRU-K算法从名字就可以知道这一定是基于LRU算法的,LRU-K算法是在LRU算法上的一次改进。现在我们分两种情况分别来看看LRU算法的效果。
第一种,假设存在一定量连续的访问,比如说我先访问A资源10次,再访问B资源10次,再访问A资源10次,再访问C资源10次,等等等等。这样我可以大致补上一个画面就是缓存队列是在一个比较小的范围里来回替换,这样就减少换入换出的次数,提高系统的性能,这是第一种情况。
第二种情况就是我们依次访问资源A、B、C、...、Y、Z,再重复n次。并且我们的缓存列队长度比这个循环周期要小。这样,我们的资源就需要不停地换入换出,增加IO操作,效率自然就下来了。这种情况导致的效果也被称着是缓存污染。
LRU-K的优势:
针对上面第二种情况产生的缓存污染,我们做了一个相应地调整——加入了一个新的历史记录的队列。前面LRU算法中,我们是只要访问了某一个资源,那么就把这个资源加入缓存,这样的结果是资源浪费,毕竟缓存队列的资源有限。而在LRU-K算法中,我们不再把只访问一次的资源放入缓存,而是当资源被访问了K次之后,才把这个资源加入到缓存队列中去,并且从历史队列中删除。当资源放入缓存中之后,我们就不用再考虑它的访问次数了。在缓存队列中,我们是以LRU算法来进行更新和淘汰的(对于历史队列可以使用FIFO也可以使用LRU)。
你是不是要问,既然这里加了一个新的历史队列还是要使用LRU算法,那么优势在哪里?而且加入了一个新的队列,也是开销呀,怎么能说还解决了LRU的问题呢?事实上一开始我也有这样的念头,后来一想,我们的历史记录队列只是一个记录数组,我们可以让它的开销很小。这里要怎么做呢?能想到么?
我们知道我们这里要说的资源,可能是一个进程,可能是一个什么其他比较大的对象。那么,如果直接在历史队列中保存这些对象或是进程,并不是一件很划算的事情,不是吗?所以,我们的突破点就是这个历史记录队列能不能尽可能地小?是可以的。我们可以对对象进行Hash成一个整数,这样就可以不用保存原来的对象了,而后面的次数可以使用byte来保存(因为我们可以默认某一个资源在一定时间内,访问的次数不会大得离谱,当然可以使用int或是long,没问题)。如此一来,历史列队就可以做得很小了。
代码实现
添加新元素:
public void offer(Object object) {
if (histories == null) {
throw new NullPointerException();
}
if (histories.size() == maxHistoryLength) {
cleanHistory();
}
LRUHistory history = new LRUHistory();
history.setHash(object.hashCode());
history.setTimes(1);
histories.add(history);
}
访问一存在的资源(visitting):
public void visitting(Object object) {
if (histories == null) {
throw new NullPointerException();
}
if (caches == null) {
throw new NullPointerException();
}
int hashCode = object.hashCode();
if (inHistory(hashCode)) {
boolean offerCache = modifyHistory(hashCode);
if (!offerCache) {
return;
}
offerToCache(object);
} else if (inCache(object)) {
displace(object);
} else {
throw new NullPointerException("对象不存在");
}
}
修改历史记录:
boolean offerCache = modifyHistory(hashCode);
if (!offerCache) {
return;
}
offerToCache(object);
上面代码的逻辑描述是当我去修改历史记录队列时,发现某一资源可以加入到缓存中去了,就把这个资源添加到缓存中去。
访问缓存队列某元素:
因为LRU-K中的缓存队列就是一个完完全全的LRU,所以LRU-K中缓存队列的访问与LRU中访问方式一致,如下:
private void displace(Object object) {
for (Object item : caches) {
if (item.equals(object)) {
caches.remove(item);
break;
}
}
caches.add(object);
}
最近最少使用算法(LFU)
LFU的英文全称Least Frequently Used中就可以看到,此算法是基于资源被访问的次数来实现的。由于算法很简单,我们就直接给出思路,而逻辑代码就不再展示了(因为下面的LRU-K和MQ才是本文的关键)。
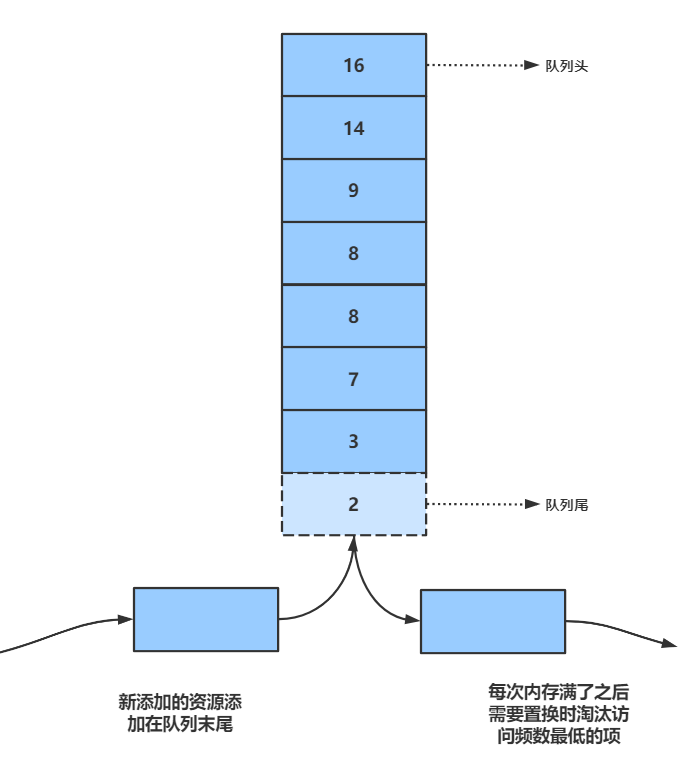
算法步骤:
(1)当有新资源被访问时,就把这个资源添加到缓存队列的尾部;
(2)当访问一个已经存在的资源时,就把这个资源被访问的次数+1,再上移至合适的位置;
(3)在被访问次数相同的资源集合中,是按照访问时间来排序的;
(4)当新资源加入时,检测到此时队列已满,那么就把队列尾部的资源换出,将新资源添加到队列的尾部。
算法评价:
此算法并不是一个很好缓存算法,因为它不能很好地反映“用户”在一个比较短的时间里访问资源的走向。