环境: hadoop1.2.1
1.启动hadoop集群时DataNode无法启动
这个问题基本上是因为在namenode端多次运行hadoop namenode –format 导致的。在hadoop的core-site.xml文件中(不同的hadoop版本名字会有不同)找到<name>hadoop.tmp.dir</name>,清空对应的文件夹。举例:
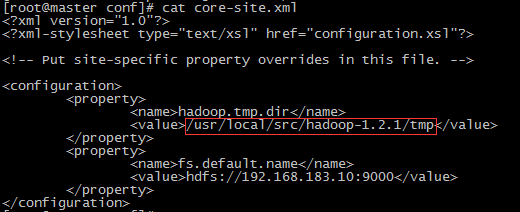
运行命令: # rm -rf /usr/local/src/hadoop-1.2.1/tmp/*
然后重新启动hadoop, 在datanode端通过jps命令看datanode是否启动.
==============================================================================
2.hadoop集群中datanode启动几秒钟自动关闭
当执行./start-all.sh后,运行jps查看进程运行状态,你会发现主从节点都起动了,去查看从节点,运行jps时会发现,你的datanode运行正常,但是过几秒钟你再运行jps指令,你会发现你的datanode进程成功的挂了,
1.于是你可以在slave1节点上ping master看看能不能连通master主机,当发现master是连通后,说明你的/etc/hosts文件配置好了的;
2.那就说明你的机器的防火墙没关,你需要把每个机器的防火墙关闭下,通过指令: iptables -L 查看防火墙状态, 运行指令关闭防火墙:service iptables stop,然后停止集群,重新运行集群就可以了。
1) 重启后生效
开启: chkconfig iptables on
关闭: chkconfig iptables off
2) 即时生效,重启后失效
开启: service iptables start
关闭: service iptables stop
温馨提示:一般情况下大家都是忘记了关闭防火墙,切记每台机器都要关,不然浏览器访问不了的(浏览器的默认访问端口是:50070,例如本人访问:http://localhost:50070)。
==============================================================================
3.子节点slave中TaskTracker可以启动, DataNode无法启动


通常是因为master和slave节点的current目录下的VERSION文件中namespaceID不一样.
解决方案一: 修改namespaceID使其一致.
解决方案二: 删除DataNode的所有资料(即将集群中每个datanode的/hdfs/data/current中的VERSION删掉,然后执行hadoop namenode -format重启集群,错误消失。<推荐>)
==============================================================================
4.启动集群时出现很多Stop it first.
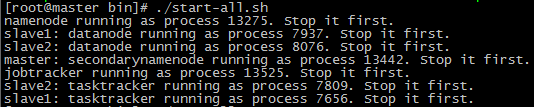
集群没启动成功, 原因是原来启动过集群还没关闭, 需要先关闭才行.Stop it first.
==============================================================================
5.通过./stop-all.sh关闭集群时, 出现no namenode to stop.
原因是找不到namenode进程的pid, 所以无法通过pid来关闭进程.
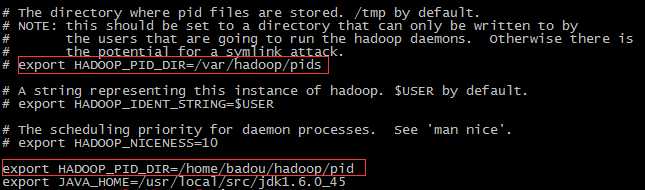
解决方法: (1). 通过jps查看进程, 再通过手动杀死进程

(2). 在hadoop-1.2.1/conf目录下的hadoop-env.sh文件中配置pid存放的位置, 每个节点都配置一下.
=============================================================================
6.当运行一个简单的wordcount时, 在windows环境通过浏览器无法访问Tracking URL.
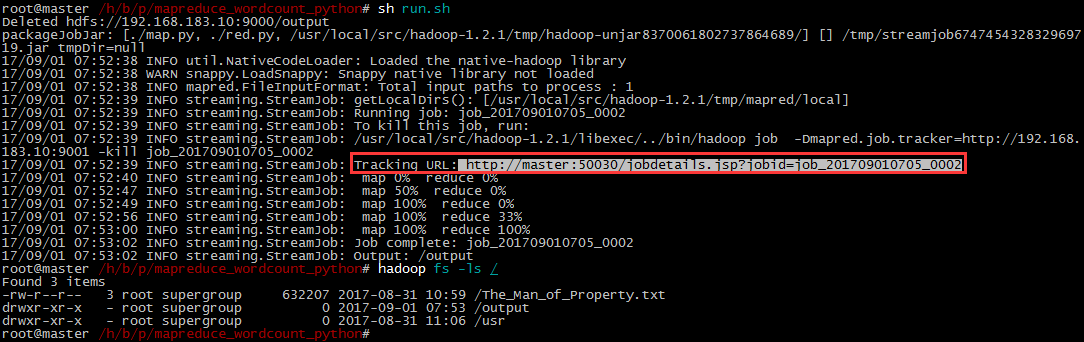
原因是因为在windows环境没有配置hostname对应的ip地址, 所以无法识别master.
有两种办法, 第一种是将url中master改成对应主机的ip地址. 第二种办法是在windows的hosts文件中添加配置.
=================================================================
7.误删文件怎么恢复
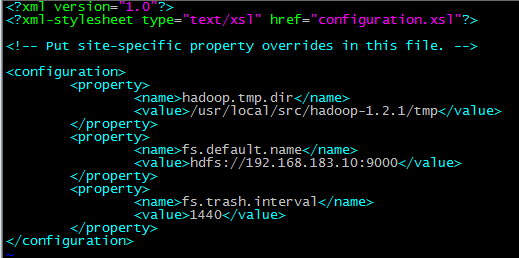
使用空间回收机制(回收站), 需要给core-site.xml增加一个配置, 同时要将配置同步到从节点, 并且要重启hadoop集群.
name: fs.trash.interval
value: 1440 (这个单位是分钟,60*24=1440, 这个配置表示删除的数据可以保留1天时间)
同步到从节点: # scp -rp core-site.xml slave1:/usr/local/src/hadoop-1.2.1/conf/ //备注:slave2也是同样的操作
查看误删文件的目录位置: # hadoop fs -ls /user/root/.Trash
还原误删文件到HDFS: # hadoop fs -cp /user/root/.Trash/文件名 /
如果删除文件时用了 -skipTrash 就不会进入到回收站
=================================================================
8.master节点启动后namenode没启动, 过了一会儿JobTracker自动关闭


查看以上日志发现是ip绑定错误. 修改hadoop的/conf/目录下的core-site.xml和mapred-site.xml中的ip即可.