首先,建立一个项目#可在github账户下载完整代码:https://github.com/connordb/scrapy-jiandan2
scrapy startproject jiandan2
打开pycharm,把建立的此项目的文件打开,在中断新建一个爬虫文件
scrapy genspide jiandan jandan.net/ooxx
在Items中配置我们需要的信息
import scrapy class Jiandan2Item(scrapy.Item): # define the fields for your item here like: img_url = scrapy.Field() # 图片的链接 img_name = scrapy.Field()
在jian_pan 文件开始我们对网页的解析
import base64
from jiandan2 import item
class JiandanSpider(scrapy.Spider):
name = 'jiandan'
allowed_domains = ['jandan.net']
start_urls = ['http://jandan.net/ooxx']
def parse(self, response):
img = response.xpath('//div[@id="comments"]/ol[@class="commentlist"]/li[@id]')
for i in img:
img_name = i.xpath('.//span[@class="righttext"]/a/text()').get()#获取图片名字
img_hash = i.xpath('.//p//span[@class="img-hash"]/text()').get()#因为直接无法获得图片链接,所以使用此方式
#获取图片链接
img_url_raw = base64.b64decode(img_hash)
img_url = 'https:' + str(img_url_raw, encoding='utf-8')
#此步我们便获取到了图片的链接
item = items.Jiandan2Item(img_name=img_name, img_url=img_url)
#把此数值赋到Items项目中
print(item)
yield item
url = response.xpath('//a[@class="previous-comment-page"]//@href').extract_first() # 翻页
next_url='https:'+ url
if next_url:
print('url存在'+next_url+'数据')
yield scrapy.Request(url=next_url,callback=self.parse)
在pipelines中保存我们的信息
import requests import os class Jiandan2Pipeline(object): def process_item(self, item, spider): path = os.path.abspath('..')#绝对路径C:\users save_path = path + '\img'#保存路径为C:\users\img if not os.path.exists(save_path):#not os.path.exist(save_path)此文件不存在返回True,存在返回None os.mkdir(save_path)#生成单级目录;相当于shell中mkdir dirname print('文件夹创建成功!') img_url = item['img_url'] img_name = item['img_name'] save_img = save_path + '\' +img_name+'.jpg'#保存图片名字 r = requests.get(img_url) with open(save_img, 'wb') as f: f.write(r.content) f.close()
在settings中设置我们的爬虫信息
ROBOTSTXT_OBEY =False
ITEM_PIPELINES = {
'jiandan2.pipelines.Jiandan2Pipeline': 1,
}
在termninal端,运行我们的爬虫,scrapy crawl jiandan
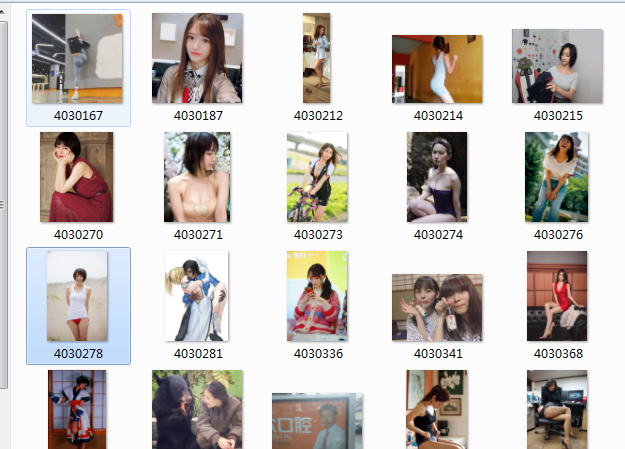
爬取成功!!!
部分截图: