"""
金额匹配是财务业务经常要处理的一个逻辑,比如发票金额与结算数据的匹配,而这种匹配经常存在1对1,1对多的关系,即一个发票金额可能正好和一条结算数据相匹配,
也可能会和多条结算数据相匹配;有时候结算数据还会有重复值;有时候能够匹配发票的结算数据组合有多种;有时候还要考虑其他因素,比如结算数据对应的结算时间。
这些都增加了匹配的难度。。。下面根据简化的实际业务情景,给出了一种解决方案:
"""
from itertools import combinations
import pandas as pd
import numpy as np
import time
def mark_dkjs_data_book(amount,book_path):
"""从台账中得到所有与发票金额相匹配的结算数据方案,并从中找到尽可能使匹配日期靠前的方案,然后在台账中作标记。(注:'业务日期'值是唯一的)"""
# 1--获取最新台账数据:
df_new=pd.read_excel(book_path)
jie_suan_date_list=df_new["结算日期"].tolist()
money_list=df_new["结算金额"].tolist()
print(money_list)
# 2--获取包含所有匹配方案(列表)的列表:切香肠式的传入money_list片段,在一定程度上保证匹配的数据日期靠前。
target_combinations=[]
for i in range(1,len(money_list)+1): # i 控制传入的列表长度
target_combination_list=[]
money_tuple_list_sub=list(zip(jie_suan_date_list[0:i],money_list[0:i])) # 将日期和金额关联起来
for j in range(1,len(money_tuple_list_sub)+1): # j 控制深度,即组合的最大长度
possible_tuple_tuple_list=combine(money_tuple_list_sub,j) # 以j为深度的所有组合(元组)为元素构成的列表
for k in possible_tuple_tuple_list: # k 为组合方案
target_combination_list=[]
if get_sum_from_tuple(k)==amount:
target_combination_list=list(k)
if target_combination_list and target_combination_list not in target_combinations:
target_combinations.append(target_combination_list)
break
if not target_combinations:
return "No matched money was found"
else:
# 3--获取接近最优解的方案:
print("所有可能的组合为:")
print(target_combinations)
print("尽可能的最优组合为:")
print(target_combinations[0])
most_possible_tagrget=target_combinations[0]
# 4--对原数据进行匹配标记:
time_format = "%Y-%m-%d"
time_now=time.strftime(time_format,time.localtime())
for date_money in most_possible_tagrget:
df_new.loc[(df_new['结算日期']==date_money[0])&(df_new['结算金额']==date_money[1]),'匹配结果']="已匹配"+"_"+time_now
# return df_book
print(df_new)
# 5--将标记后的新数据覆盖写回台账:
df_new["结算金额"]=df_new["结算金额"].astype(np.float64)
df_new.to_excel(book_path,index=None)
return "matching and marking completed"
# 辅助函数:
def combine(temp_list, n):
'''根据长度n获得列表中的所有可能组合(n个元素为一组)'''
temp_list2 = []
for c in combinations(temp_list, n): # combinations(temp_list, n)结果类似于生成器类型的对象。
temp_list2.append(c)
return temp_list2
def get_sum_from_tuple(tuple_tuple):
sum=0
for item in tuple_tuple:
sum+=item[1]
return sum
amount=19145
book_path=r"C:UsersXuYunPengDesktop结算数据表简化.xlsx"
mark_dkjs_data_book(amount,book_path)
output:
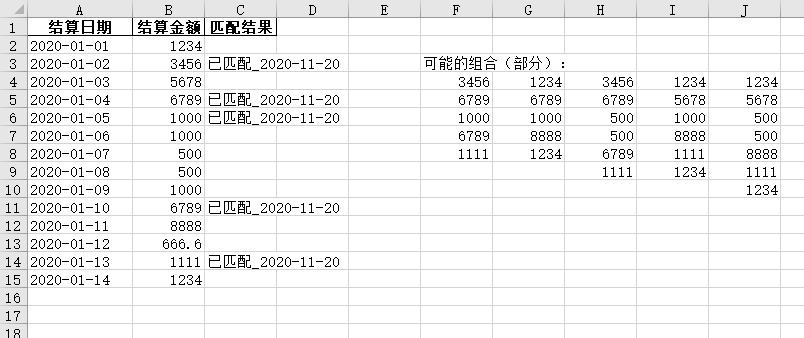
匹配前:

匹配后:
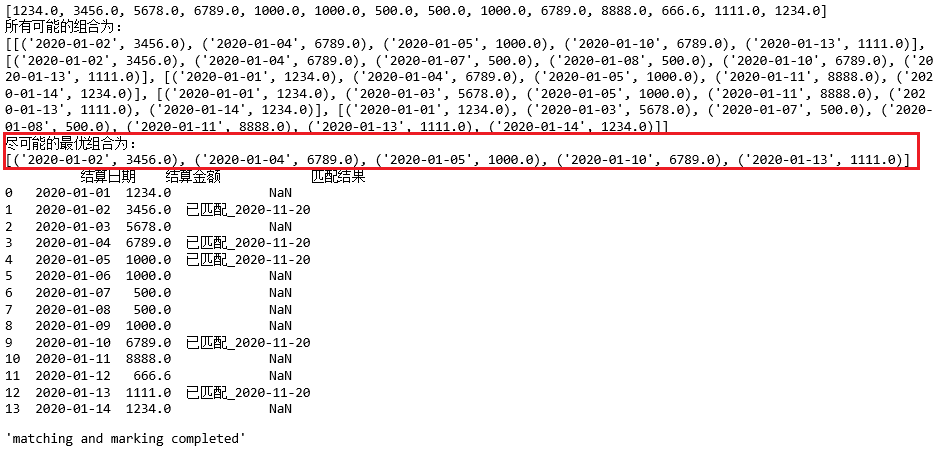
控制台输出:
作者:Collin wx:pxy123abc tel:17763230890