使用union来打包/拆包数据
联合的成员存储在共享存储区中。这是使我们能够找到有趣的工会应用程序的关键功能。
考虑下面的联合:
- union {
- uint16_t word;
- struct {
- uint8_t byte1;
- uint8_t byte2;
- };
- } u1;
此union内部有两个成员:第一个成员“ word”是一个两字节的变量。第二个成员是两个单字节变量的结构。为联合分配的两个字节在其两个成员之间共享。
分配的内存空间可以如下图1所示。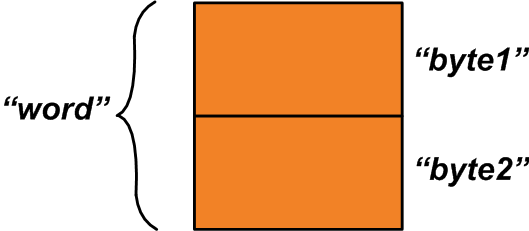
图1
“ word”变量是指整个分配的内存空间,“ byte1”和“ byte2”变量是指构成“ word”变量的一字节区域。我们如何使用此功能?假设您有两个单字节变量“ x”和“ y”,应将其组合以产生单个两字节变量。
在这种情况下,您可以使用上述联合并为结构成员分配“ x”和“ y”,如下所示:
- u1.byte1 = y;
- u1.byte2 = x;
现在,我们可以读取并集的“ word”成员,以获得由“ x”和“ y”变量组成的两字节变量(参见图2)。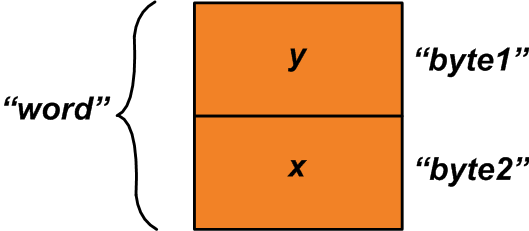
图2
上面的示例显示了使用并集将两个一个字节的变量打包为单个两个字节的变量。我们也可以做相反的事情:将两个字节的值写入“ word”,然后通过读取“ x”和“ y”变量将其解压缩为两个一个字节的变量。将值写入工会的一个成员并读取工会的另一个成员有时被称为“数据修剪”。
处理器字节序
当使用联合对数据进行打包时,我们需要注意处理器的字节顺序。正如罗伯特·基姆(Robert Keim)关于字节序的文章所讨论的那样,该术语指定了数据对象的字节在内存中存储的顺序。处理器可以是小端或大端。使用big-endian处理器时,数据的存储方式是,包含最高有效位的字节具有最低的内存地址。在小端系统中,包含最低有效位的字节首先存储。
图3中所示的示例说明了序列0x01020304的小端和大端存储。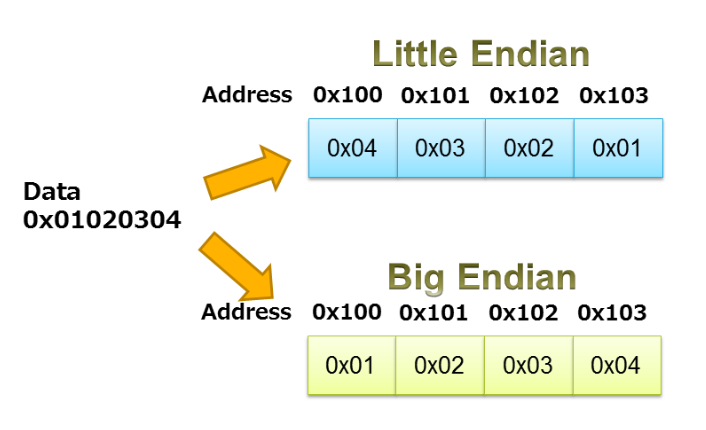
图3.图片由IAR提供。
让我们使用以下代码尝试上一节的并集:
- #include <stdio.h>
- #include <stdint.h>
- int main()
- {
- union {
- struct{
- uint8_t byte1;
- uint8_t byte2;
- };
- uint16_t word;
- } u1;
- u1.byte1 = 0x21;
- u1.byte2 = 0x43;
- printf("Word is: %#X", u1.word);
- return 0;
- }
运行此代码,我得到以下输出:
词是:0X4321
这表明共享存储空间的第一个字节(“ u1.byte1”)用于存储“ word”变量的最低有效字节(0X21)。换句话说,我用来执行代码的处理器是Little Endian。
如您所见,联合的特定应用程序可能表现出与实现有关的行为。但是,这不是一个严重的问题,因为对于这样的低级编码,我们通常知道处理器的字节序。如果我们不知道这些细节,我们可以使用上面的代码来查找数据在内存中的组织方式。
替代解决方案
除了使用并集,我们还可以使用按位运算符来执行数据打包或拆包。例如,我们可以使用以下代码来组合两个一个字节的变量“ byte3”和“ byte4”,并产生一个单个的两个字节的变量(“ word2”):
- word2 = (((uint16_t) byte3) << 8 ) | ((uint16_t) byte4);
让我们比较一下小端和大端两种情况下这两种解决方案的输出。考虑下面的代码:
- #include <stdio.h>
- #include <stdint.h>
- int main()
- {
- union {
- struct {
- uint8_t byte1;
- uint8_t byte2;
- };
- uint16_t word1;
- } u1;
- u1.byte1 = 0x21;
- u1.byte2 = 0x43;
- printf("Word1 is: %#X ", u1.word1);
- uint8_t byte3, byte4;
- uint16_t word2;
- byte3 = 0x21;
- byte4 = 0x43;
- word2 = (((uint16_t) byte3) << 8 ) | ((uint16_t) byte4);
- printf("Word2 is: %#X ", word2);
- return 0;
- }
如果我们针对大型字节序处理器(例如TMS470MF03107)编译此代码,则输出为:
Word1是:0X2143
Word2是:0X2143
但是,如果我们针对像STM32F407IE这样的小端序处理器对其进行编译,则输出将是:
Word1是:0X4321
Word2是:0X2143
尽管基于联合的方法表现出与硬件有关的行为,但是基于移位操作的方法却得到相同的结果,而不管处理器的字节顺序如何。这是由于以下事实:在后一种方法中,我们为变量的名称(“ word2”)分配了一个值,并且编译器负责该设备使用的内存组织。但是,使用基于联合的方法,我们正在更改构成“ word1”变量的字节的值。
尽管基于联合的方法表现出与硬件有关的行为,但它具有更易读和可维护的优点。这就是为什么许多程序员更喜欢在该应用程序中使用联合的原因。
“数据校正”的实际示例
在使用常见的串行通信协议时,我们可能需要执行数据打包或拆包。考虑一个串行通信协议,该协议在每个通信序列期间发送/接收一个字节的数据。只要我们使用一字节长的变量,就很容易传输数据,但是如果我们有一个任意大小的结构应该通过通信链接怎么办?在这种情况下,我们必须以某种方式将数据对象表示为一字节长的变量数组。一旦获得了字节数组表示,就可以通过通信链接传输字节。然后,在接收器端,我们可以适当地打包它们并重建原始结构。
例如,假设我们需要通过UART通信发送一个浮点变量“ f1”。浮点变量通常占用四个字节。因此,我们可以将以下并集用作提取“ f1”的四个字节的缓冲区:
- union {
- float f;
- struct {
- uint8_t byte[4];
- };
- } u1;
发送器将变量“ f1”写入联合的float成员。然后,它读取“字节”数组并将字节发送到通信链接。接收器进行相反的操作:它将接收到的数据写入其自己的并集的“字节”数组,并读取并集的float变量作为接收值。我们可以使用这种技术来传输任意大小的数据对象。以下代码可以作为验证此技术的简单测试。
- #include <stdio.h>
- #include <stdint.h>
- int main()
- {
- float f1=5.5;
- union buffer {
- float f;
- struct {
- uint8_t byte[4];
- };
- };
- union buffer buff_Tx;
- union buffer buff_Rx;
- buff_Tx.f = f1;
- buff_Rx.byte[0] = buff_Tx.byte[0];
- buff_Rx.byte[1] = buff_Tx.byte[1];
- buff_Rx.byte[2] = buff_Tx.byte[2];
- buff_Rx.byte[3] = buff_Tx.byte[3];
- printf("The received data is: %f", buff_Rx.f);
- return 0;
- }
下面的图4展示了所讨论的技术。请注意,字节是顺序传输的。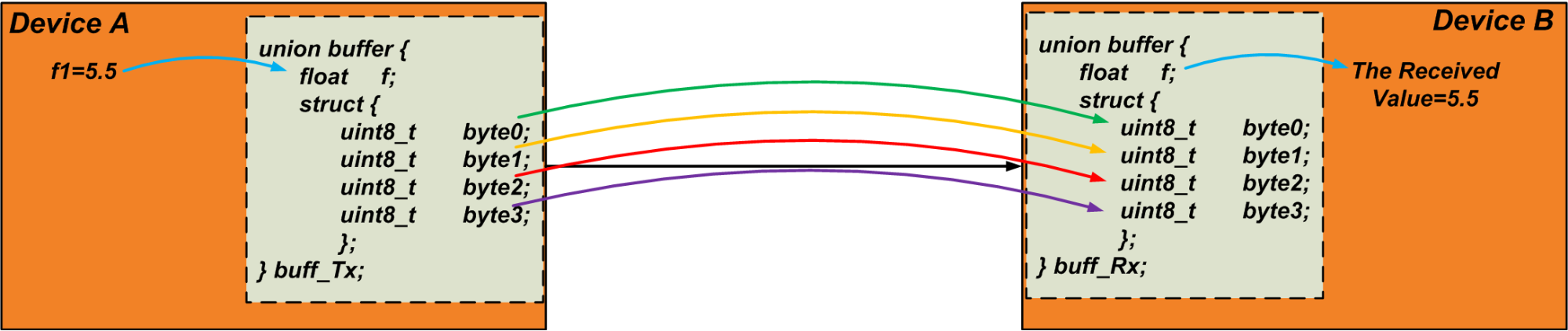
图4
结论
联合的原始应用程序创建了互斥变量的共享存储区,但随着时间的流逝,程序员已经广泛使用联合用于完全不同的应用程序:使用联合进行数据打包/拆包。工会的这种特殊应用涉及将值写入工会的一个成员并读取工会的另一个成员。
“数据修剪”或使用联合进行数据打包/拆包可能导致依赖于硬件的行为。但是,它具有更具可读性和可维护性的优点。这就是为什么许多程序员更喜欢在该应用程序中使用联合的原因。当我们有任意大小的数据对象应通过串行通信链接时,“数据修剪”将特别有用。
https://bbs.elecfans.com/jishu_1994084_1_1.html