能够学习到短文本分类模型——Tgrocery,十分感谢@GavinBuildSomething把源码及测试数据分享,在此我也作为一名学习者将自己的学习过程记录下来,希望对其他人有所帮助。
1.学习Tgrocery
这是作者在github上的项目链接包括源码及测试——https://github.com/2shou/TextGrocery
2.Tgrocery使用及细节问题
运行环境:Linux 、mac os (这个必须注意,不然无法运行)
(1)安装Linux
首先需要安装Linux系统,作者安装的是ubuntu14,下载及安装具体见http://www.cnblogs.com/Climbing-Snail/p /6410128.html(安装ubuntu14是有原因的,在后面遇到会说明)
(2)查看python版本,以及安装交互环境idle
Ubuntu会默认安装python,在命令行输入python可以查看python版本。

这里可以看出使用的python版本为2.7.6 接下来安装python的交互环境idle,在命令行输入下面命令:
sudo apt-get install idle
运行idle可以通过在命令行输入 /usr/bin/idle-python2.7 ,也可以通过图形桌面查找idle,并将其托至左侧创建快捷图标。

(3)安装tgrocery库
Tgrocery是一个python的第三方库,按照作者的话说,在python第三方库中“只此一家,别无分店”。
pip install tgrocery
通过命令 dpkg -s tgrocery 查看包是否安装成功,奇怪的是竟然显示没有安装(当然可能也是刚使用Linux系统,命令不熟,请各位指教)

那么在idle中导入tgrocery来验证是否安装成功,居然是成功的,那么这样就可以顺利进行下面的测试啦。
(4)在idle中测试
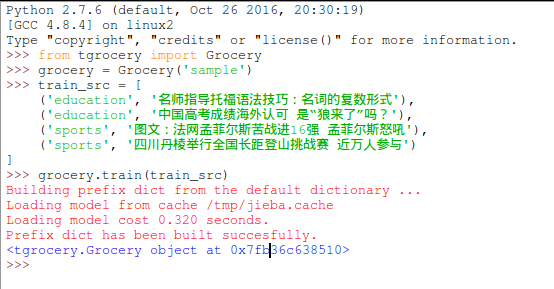
已经训练成功,但是出现了python2到python3的兼容问题,后面也不会出现预测值等。这个问题楼主百度了很久都没有解决,后来想到在命令行执行。(这也是博主选择ubuntu14以及python2的原因)
(5)命令行执行测试代码
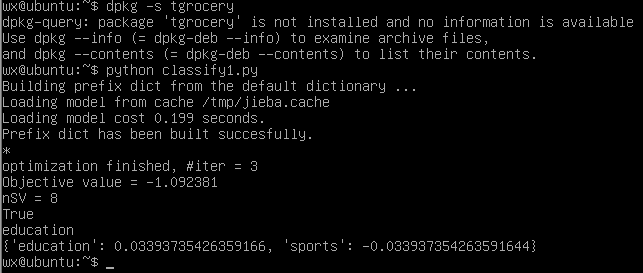
成功啦!!!
下面将测试代码附上
classify1.py
# coding: utf-8 from tgrocery import Grocery grocery = Grocery('test') train_src = [ ('education', '名师指导托福语法技巧:名词的复数形式'), ('education', '中国高考成绩海外认可 是“狼来了”吗?'), ('sports', '图文:法网孟菲尔斯苦战进16强 孟菲尔斯怒吼'), ('sports', '四川丹棱举行全国长距登山挑战赛 近万人参与') ] grocery.train(train_src) print grocery.get_load_status() predict_result = grocery.predict('考生必读:新托福写作考试评分标准') print predict_result print predict_result.dec_values
classify2.py
# coding: utf-8 from tgrocery import Grocery grocery = Grocery('read_text') train_src = '/home/wx/sample_data/train_file.txt' grocery.train(train_src) print grocery.get_load_status() predict_result = grocery.predict('考生必读:新托福写作考试评分标准') print predict_result print predict_result.dec_values
test1.py
# coding: utf-8 from tgrocery import Grocery grocery = Grocery('test') train_src = [ ('education', '名师指导托福语法技巧:名词的复数形式'), ('education', '中国高考成绩海外认可 是“狼来了”吗?'), ('sports', '图文:法网孟菲尔斯苦战进16强 孟菲尔斯怒吼'), ('sports', '四川丹棱举行全国长距登山挑战赛 近万人参与') ] grocery.train(train_src) print grocery.get_load_status() test_src = [ ('education', '福建春季公务员考试报名18日截止 2月6日考试'), ('sports', '意甲首轮补赛交战记录:米兰客场8战不败国米10年连胜'), ] test_result = grocery.test(test_src) print test_result.accuracy_labels print test_result.recall_labels
test4.py
# coding: utf-8 from tgrocery import Grocery grocery = Grocery('read_text') train_src = '/home/wx/sample_data/train_file.txt' grocery.train(train_src) print grocery.get_load_status() f=open('/home/wx/sample_data/question.txt','r') question=f.readlines() for line in question: line=line.strip() predict_result = grocery.predict(line) print line print predict_result print predict_result.dec_values f.close()
前三段代码2shou已经码好,作者主要写了段对批量文本做预测的代码,希望能有用。
下面博主将会将短文本分类部署到一个简单的服务器上,具体见下节