1、安装:
终端输入:pip install locust 安装,安装后locust --version查看当前Locust版本
终端输入: locust --help 显示帮助信息
locust官网: https://www.locust.io/
官网帮助文档: https://docs.locust.io/en/latest/installation.html
大并发量测试时,建议在linux系统下进行;
2、python编写性能测试脚本
locust通过client属性来使用Python requests库的所有方法,调用方式与reqeusts一样(源码中变量client赋值了HttpSession类,而HttpSession继承自requests.Session,故client可以使用requests库中的所有方法,感兴趣的可以看下源码)。
以访问博客园为例,编写实例脚本如下:
from locust import HttpLocust, TaskSet, task # 定义用户行为 class UserBehavior(TaskSet): def on_start(self): print("start") @task(1) def bky_index(self): self.client.get("/") @task(2) def blogs(self): self.client.get("/Clairewang/p/8622280.html") class WebsiteUser(HttpLocust): host = "https://www.cnblogs.com" task_set = UserBehavior min_wait = 1500 max_wait = 5000
UserBehavior类继承TaskSet类,用于描述用户行为:
- 使用@task装饰的方法为一个事务,方法的参数用于指定该行为的执行权重,参数越大每次被用户执行的概率越高,默认为1(事务blogs()被执行的概率是bky_index()的2倍);
- on_start():每个locust用户执行测试事务之前执行一次,用于做初始化的工作,如登录;
WebsiteUser类用于设置性能测试属性:
- host :要加载主机的URL前缀(即“https://www.cnblogs.com”),通常是在命令行启动locust时使用--host选项指定,若命令行启动时未指定,该属性被使用;
- task_set:指向定义的一个用户行为类;
- min_wait:模拟用户在执行每个任务之间等待的最小时间,单位为毫秒;
- max_wait:模拟用户在执行每个任务之间等待的最大时间,单位为毫秒(min_wait和max_wait默认值为1000,因此,如果没有声明min_wait和max_wait,则locust将在每个任务之间始终等待1秒。);
- weight:一个文件中有多个locust用户类时,指定用户类的权重(默认新增locust用户时会随机选择一个用户类);
class WebUserLocust(Locust): weight = 3 ... class MobileUserLocust(Locust): weight = 1 ...
WebUserLocus用户执行的概率是MobileUserLocust用户的三倍。
实例中只用了get方式请求,post方式请求操刀实例如下:
class JingClue(TaskSet): def on_start(self): self.login() self.header = { "Authorization": self.token } def login(self): username = '18200389565' password = '123456' with self.client.post('/security/log/login', {'username': username, "password": password}) as response: if response.status_code == 200: self.token = "Bearer " + response.json()["data"]["token"] @task def publicoceanclues(self): url = '/DataService/publicOcean/getPublicOceanClues' data = { "pageSize": 20, "pageIndex": 1, "sortField": "discardTime", "sortType": -1 } self.client.post(url, json=data, headers=self.header)
3、启动:
终端进入代码目录,输入 locust -f bokeyuan.py --host=https://www.cnblogs.com
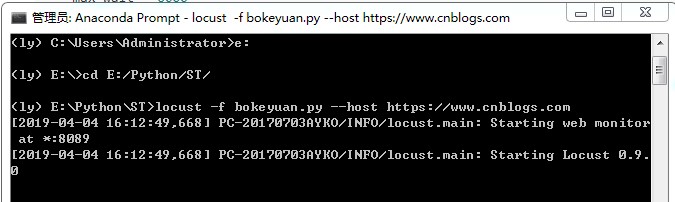
- -f :指定要运行的测试脚本文件;
- -host :要加载主机的URL前缀,不指定时,读取WebsiteUser类中定义的host;
- --master:单台机器不能模拟更多用户时,分布式模式,通过--master指定主进程;
4、打开Locust的web界面
使用上面的命令行启动Locust之后,应该打开浏览器并将其指向http://127.0.0.1:8089(如果您在本地运行Locust)。
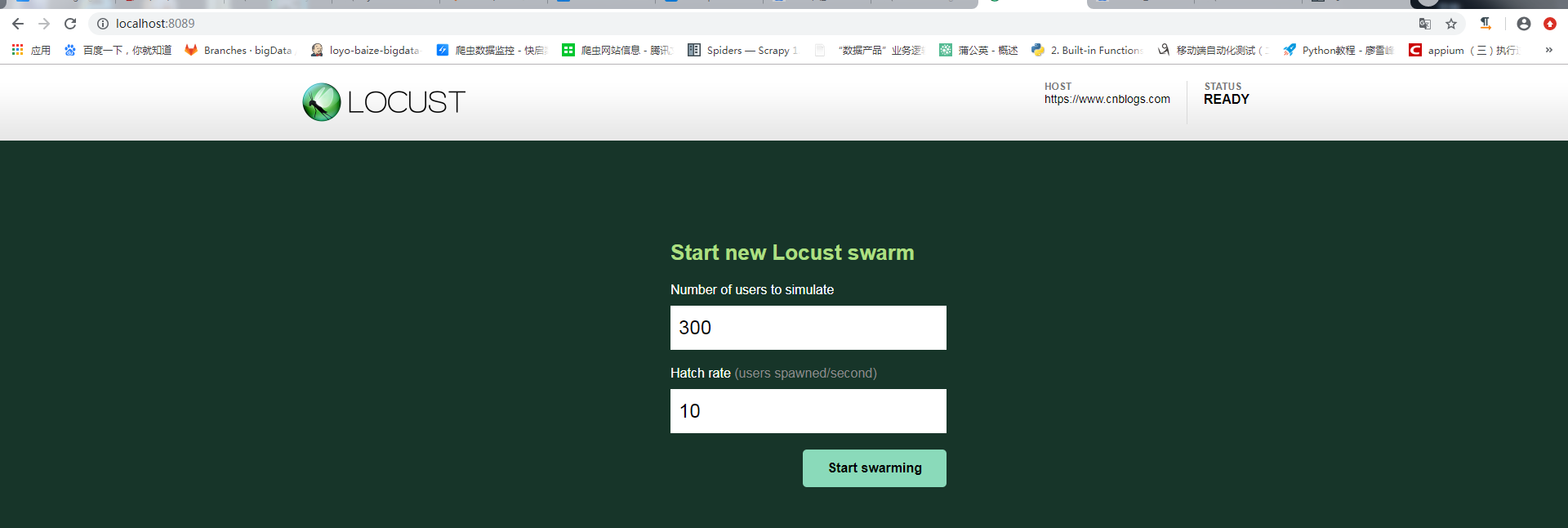
- Number of users to simulate :设置模拟用户数;
- Hatch rate(users spawned/second) :每秒产生(启动)的虚拟用户数;
设置好模拟用户后,点击Start swarming开始测试,测试结果如下:
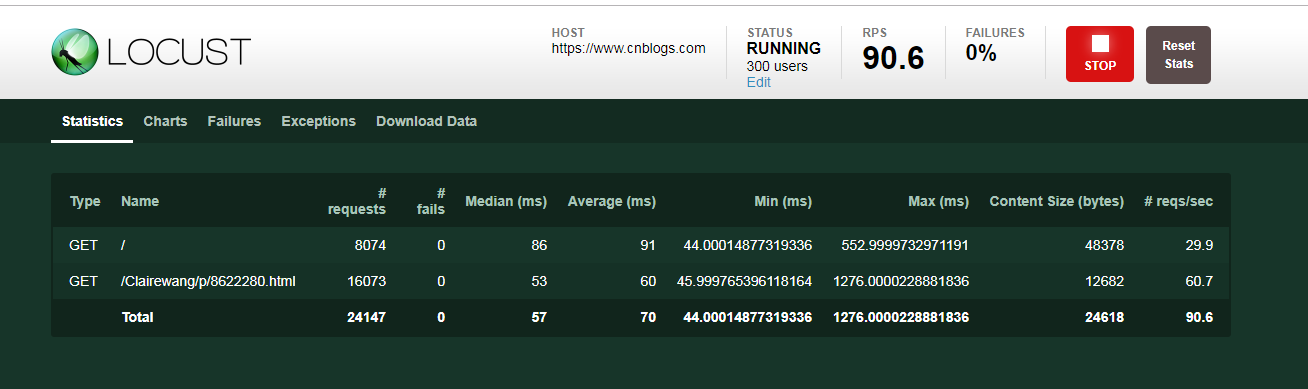
- Type :请求的类型,如GET/POST;
- Name :请求的路径;
- request :已发出请求数量;
- fails :请求失败的数量;
- Median :响应时间的中间值(单位:毫秒);
- Average :平均响应时间(单位:毫秒);
- Min :请求的最小响应时间(单位:毫秒);
- Max :请求的最大响应时间(单位:毫秒);
- Content Size:单个请求的大小(单位:字节);
- reqs/sec:每秒钟请求的个数;
今日先更到这里吧,断点、使用队列参数化、分布式测试等后续空了再继续更。
加微信交流或打赏鼓励:

交流QQ:1271782085