$
匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘ ' 或 ‘ '。要匹配 $ 字符本身,请使用 $。
( )
标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 。
*
匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 *。
+
匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 +。
.
匹配除换行符 之外的任何单字符。要匹配 .,请使用 。
[ ]
标记一个中括号表达式的开始。要匹配 [,请使用 [。
?
匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 ?。
将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n' 匹配字符 ‘n'。' ' 匹配换行符。序列 ‘\' 匹配 “”,而 ‘(' 则匹配 “(”。
^
匹配输入字符串的开始位置,除非在方括号表达式中使用,此时它表示不接受该字符集合。要匹配 ^ 字符本身,请使用 ^。
{ }
标记限定符表达式的开始。要匹配 {,请使用 {。
|
指明两项之间的一个选择。要匹配 |,请使用 |。
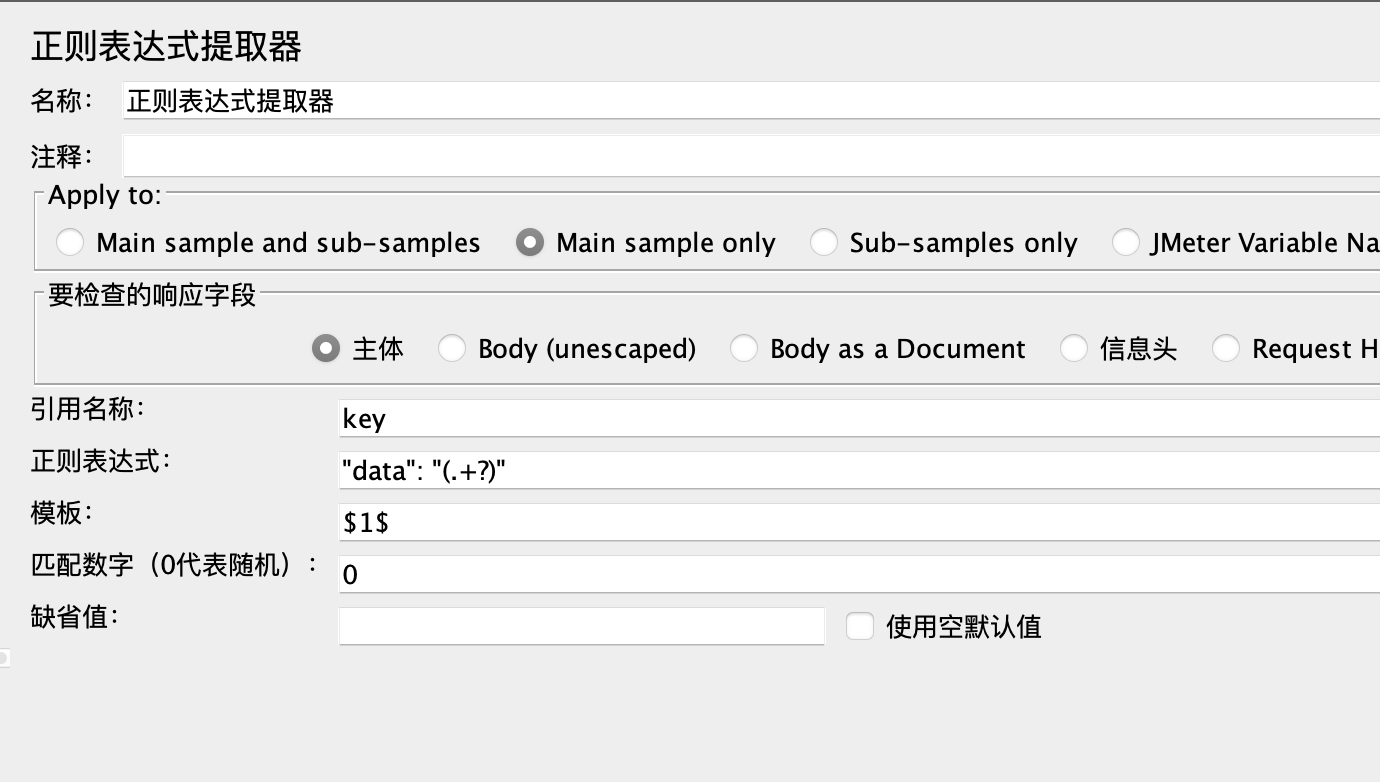
.+ (要提取的字符).+
返回多个相同的字符时,可以使用该方法,类似相对定位,参考资料https://jingyan.baidu.com/article/7908e85cbf4506af481ad2e4.html