GoogleNet的发展
Inception V1:
Inception V1中精心设计的Inception Module提高了参数的利用率;nception V1去除了模型最后的全连接层,用全局平均池化层(将图片尺寸变为1x1),在先前的网络中,全连接层占据了网络的大部分参数,很容易产生过拟合现象;(详细见下面论文分析)
Inception V2:
Inception V2学习了VGGNet,用两个3*3的卷积代替5*5的大卷积核(降低参数量的同时减轻了过拟合),同时还提出了注明的Batch Normalization(简称BN)方法。BN是一个非常有效的正则化方法,可以让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率可以的到大幅度提高。
BN在用于神经网络某层时,会对每一个mini-batch数据的内部进行标准化处理,使输出规范化到(0,1)的正态分布,减少了Internal Covariate Shift(内部神经元分布的改变)。BN论文指出,传统的深度神经网络在训练时,每一层的输入的分布都在变化,导致训练变得困难,我们只能使用一个很小的学习速率解决这个问题。而对每一层使用BN之后,我们可以有效的解决这个问题,学习速率可以增大很多倍,达到之间的准确率需要的迭代次数有需要1/14,训练时间大大缩短,并且在达到之间准确率后,可以继续训练。以为BN某种意义上还起到了正则化的作用,所有可以减少或取消Dropout,简化网络结构。
当然,在使用BN时,需要一些调整:
- 增大学习率并加快学习衰减速度以适应BN规范化后的数据
- 去除Dropout并减轻L2正则(BN已起到正则化的作用)
- 去除LRN
- 更彻底地对训练样本进行shuffle
- 减少数据增强过程中对数据的光学畸变(BN训练更快,每个样本被训练的次数更少,因此真实的样本对训练更有帮助)
Inception V3:
Inception V3主要在两个方面改造:
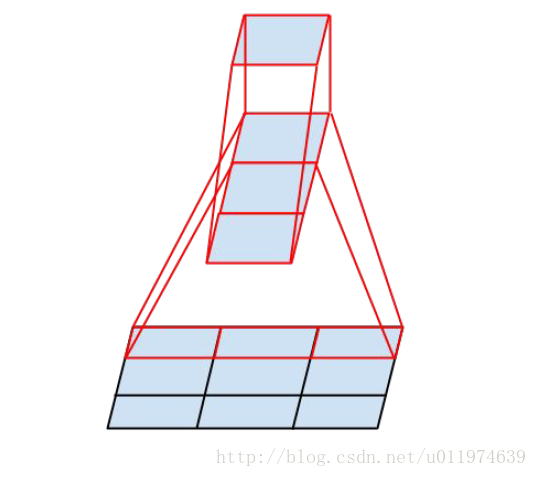
- 引入了Factorization into small convolutions的思想,将一个较大的二维卷积拆成两个较小的一位卷积,比如将7*7卷积拆成1*7卷积和7*1卷积(下图是3*3拆分为1*3和3*1的示意图)。 一方面节约了大量参数,加速运算并减去过拟合,同时增加了一层非线性扩展模型表达能力。论文中指出,这样非对称的卷积结构拆分,结果比对称地拆分为几个相同的小卷积核效果更明显,可以处理更多、更丰富的空间特征、增加特征多样性。
3*3卷积核拆分为1*3卷积和3*1卷积示意图:
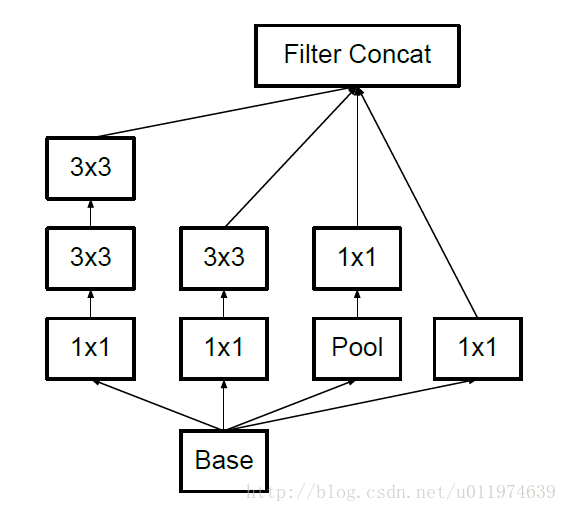
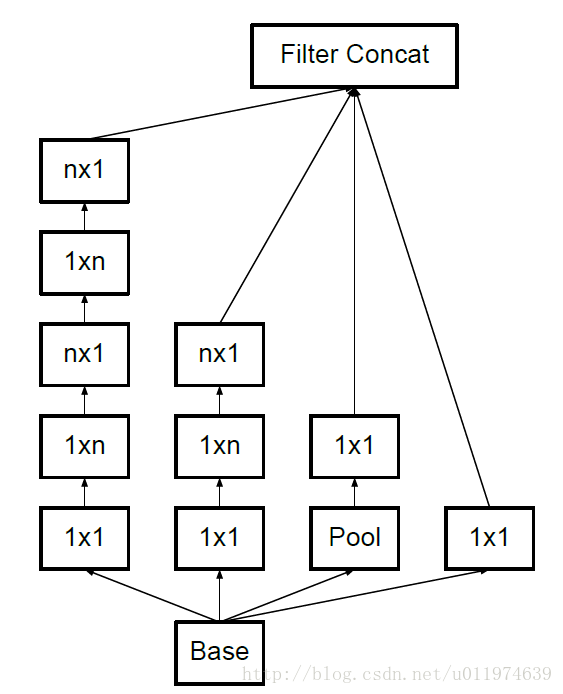
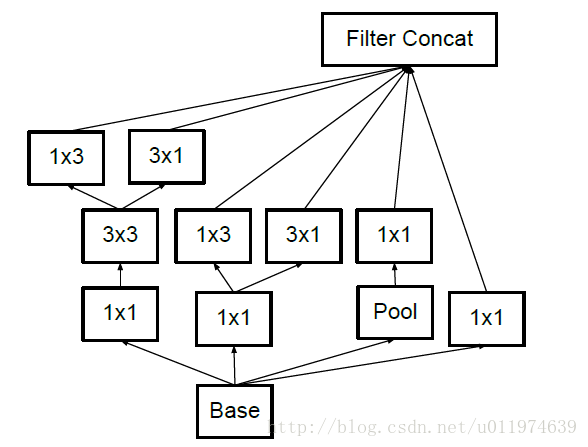
- 另一方面,Inception V3优化了Inception Module的结构,现在Inception Module有35*35、17*17和8*8三种不同的结构,如下图。这些Inception Module只在网络的后部出现,前部还是普通的卷积层。并且还在Inception Module的分支中还使用了分支。
Inception V3中三种结构的Inception Module:
Inception V4:
Inception V4相比V3主要是结合了微软的ResNet,有兴趣的可以查看《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》论文。
对于Inception的实现,截取一段tf的googleNet代码:
with tf.Variable_scope('inception_1_m1'): with tf.Variable_scope('Branch_0'): branch_0=slim.conv2d(net, 64, [1,1], scope='conv2d_0a_1xa') with tf.Variable_scope('Brance_1'): branch1_1=slim.conv2d(net, 48, [1,1], scope='conv2d_1a_1x1') branch1_2=slim.conv2d(branch1_1, 64, [5,5], scope='conv2d_1b_5x5') with tf.Variable_scope('Branch_2'): branch2_1 = slim.conv2d(net, 64, [1,1], scope='conv2d_2a_1x1') branch2_2 = slim.conv2d(branch2_1, 96, [3,3], scope='conv2d_2b_3x3') branch2_3 = slim.conv2d(branch2_2, 96, [3,3], scope='conv2d_2c_3x3') with tf.Variable_scope('Branch_3'): branch3_1 = slim.avg_pool2d(net, [3,3], scope='avgPool_3a_3x3') branch3_2 = slim.conv2d(branch3_1, 32, [1,1], scope='conv2d_3b_1x1') ##四个branch net合并,output的xXy维度相同,在channel维度叠加 net = tf.concat([branch_0, branch1_2, branch2_3. branch3_2], 3)
把最终的output变成如图:
