TensorFlow 是google提供的一个机器学习的主流框架,调用一下Wiki的解释: Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow为张量从流图的一端流动到另一端计算过程。TensorFlow是将复杂的数据结构传输至人工智能神经网中进行分析和处理过程的系统。
上一章节通过Make your own neural network这本书,对神经网络底层的知识已经有所了解并做以练习,所以接下来尝试学习一些主流的机器学习框架,了解框架的应用以及原理。
通过两个入门级的tensorflow程序来应用tf:
import tensorflow as tf import numpy as np
Practice A:
首先导入tf需要的包,以及numpy,一个非常强大的py数学处理包
第一个程序我们来模拟一下数据集:
x_data = np.float32(np.random.rand(2,100)) # 生成一个2维的100列的数组 y_data = np.dot([0.100,0.200], x_data) + 0.300 # dot方法,矩阵相乘
x为input data,y为假设的真实数据的结果
接下来在一个神经网络中,会有我们之前提到的权重,以及biars,也就是一个常量,因为在图像识别里,会有许多与我们所需要信息相比,无关的信息。
调用 tf.Variable来初始化这些变量:
b = tf.Variable(tf.zeros([1])) # biars 设置为0 w = tf.Variable(tf.random_uniform([1,2], -1.0, 1.0)) # weight
tf.matmul方法表示用w与x_data相乘的和,之后每组数据跑出的output y,当然在这里没有应用到激励函数,按照之前的模型,需要再把结果用激励函数转化为非线性模型,比如:sigmoid(y), Relu(y)等,代码:
y = tf.matmul(w, x_data) + b # y为 输出结果tf.matmul方法相当于weight和x相乘累加,再加上biars b
接下来就需要做back propagation,去modify我们的w和b了,我们定义loss为真实数据和训练输出的差异,如果差异越小,就说明训练的结果越好。
loss = tf.reduce_mean(tf.square(y - y_data)) #计算训练结果和真实数据y_data的差异, reduce_mean,求平均值 optimizer = tf.train.GradientDescentOptimizer(0.5) train = optimizer.minimize(loss)
初始化所有参数:
init = tf.global_variables_initializer()
接下来初始化参数,并在session中执行:
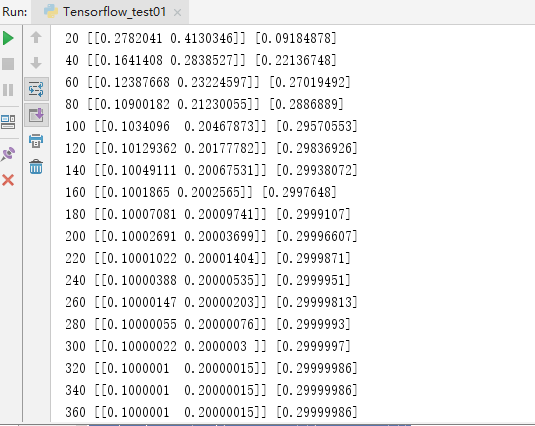
sess = tf.Session() sess.run(init) for step in range(0, 361): sess.run(train) if step % 20 == 0: print (step, sess.run(w), sess.run(b))
可以看一下执行了361次的对应的参数的变化结果,发现在执行过程中,参数在不断地靠拢所执行的特定的结果,在320次左右的时候,值不发生改变: