https://drive.google.com/drive/folders/13_vsxSIEU9TDg1TCjYEwOidh0x3dU6es
https://www.cse.unsw.edu.au/~cs9313/20T2/slides/L7.pdf
Machine Learning :
1. Construct a model, predicting new data
2.
Evaluation Matrix:
Positive/Negative: Label ∈{a,b,c,d} 选择a为positive,则其他都是negative
False Positive: not a but classified as a
False Negative: a but classified as b or c or d
True Positive : a and classified as a
Precision = tp / tp+fp
Recall = tp / tp+fn
F1 = 2 * precision*recall / ( precision + recall)
Micro: True label 是 positive
Macro: mean of F1 of each class label
Classification:
1. Preprocessing and Feature Engineering
1) bag of words
2) 去高频词

2. Train classifier
3. Evaluate the classifier
1) split a 'development set' from the training set
2) k-fold cross-validation, 然后取 avg(accuracy)

Text Classification:
1. Input •Document or sentence
2. •Output •Class label C ∈ {c1, c2, … }
3. Classification methods:
•Naïve bayes
•Logistic regression
•Support-vector machines •…
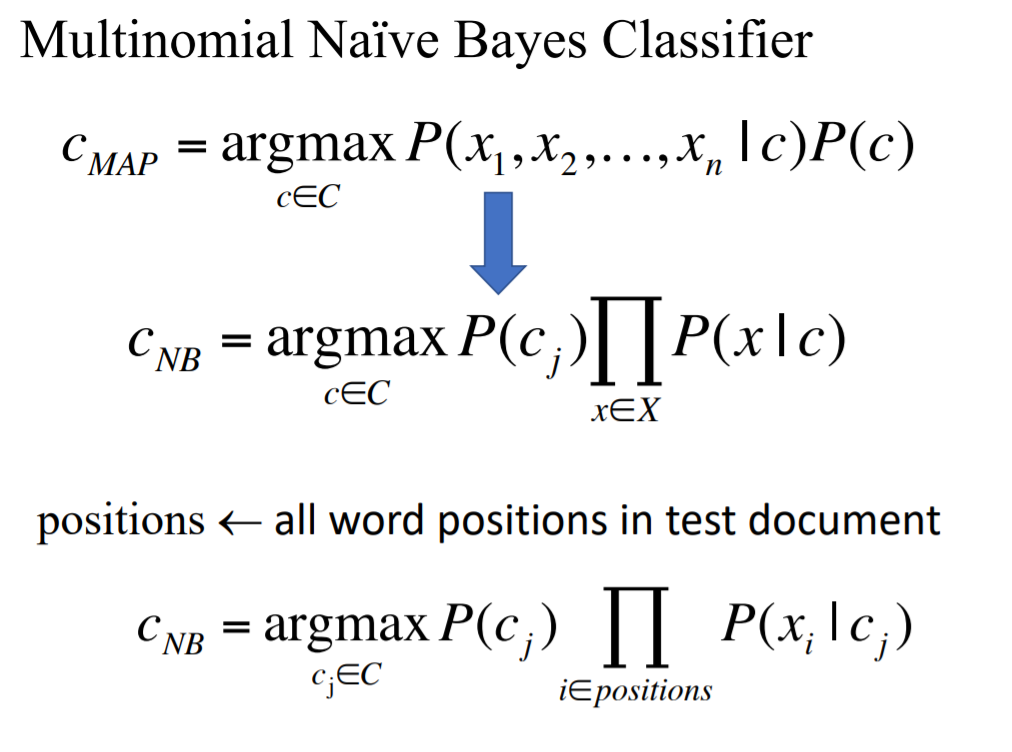
4. Naïve Bayes
1) bag of words -> features变成d维向量,label为c
2) 最大后验概率
3)假设条件独立。假设位置无关
4) 



PySpark MLlib: