https://www.cse.unsw.edu.au/~cs9313/20T2/slides/L2.pdf
https://drive.google.com/drive/folders/13_vsxSIEU9TDg1TCjYEwOidh0x3dU6es
第二节课花了40分钟讲,如果dataNode坏掉之后,block丢失的概率,以及每个Block的数量设置为3的科学之处;剩余10分钟讲了HDFS文件的create write read.
1. Block的存储
1)每个Block设置为3个,分别存放于不同的DataNode中,第一份存放于local DataNode,其他两份存放于不同于第一份的rack中的两个dataNode 这样防止出现电力事故造成的数据丢失。
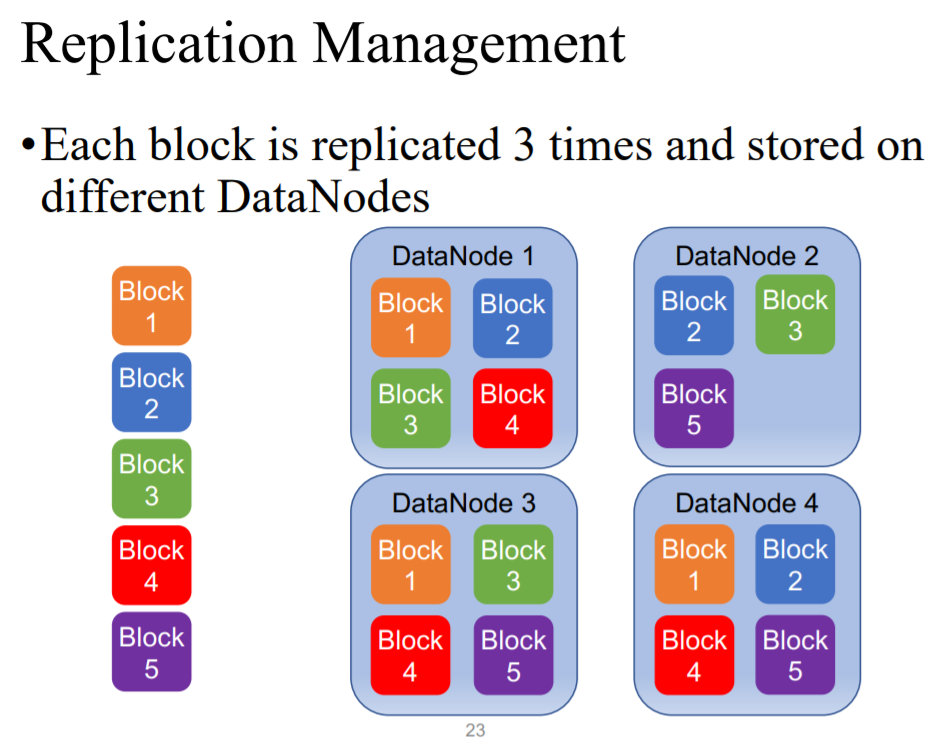

2)为什么每个block数量要设置为3
设有4000个nodes,三百万个blocks,每个Node便有750个blocks,每日丢失一个node
这些计算好无聊啊 - -






HDFS独写:
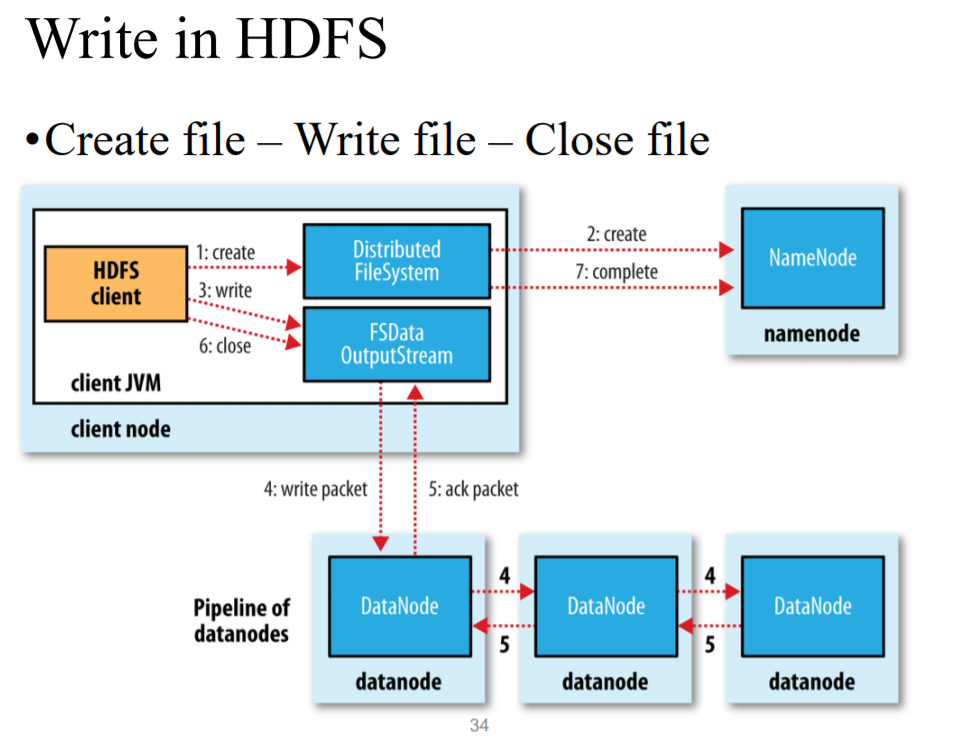
1. write
1)先向分DFS申请空间,然后DFS向NameNode发出申请
2)Client经过FSDataOutputStream 开始在Pipeline of datanodes里面写三份
3) 写完之后 经过FSDataOutputStream关闭,并告诉NameNode 结束
1) 对于一份文件同时只能一个人写
2)blocks可以同时进行写

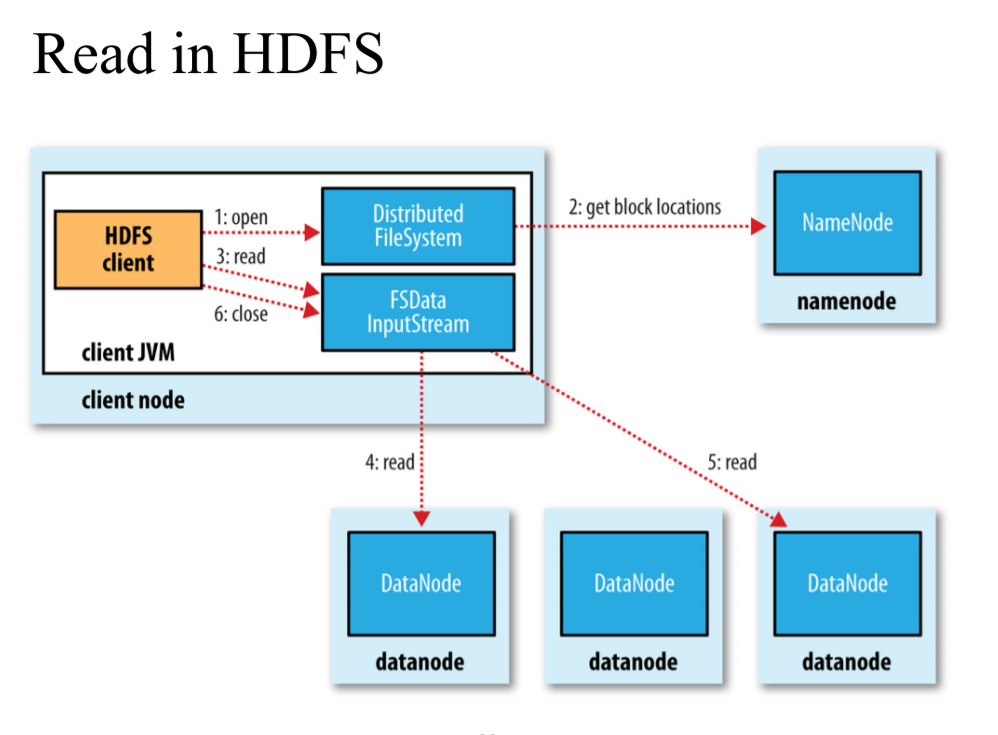
read: