说话人自适应技术 (Speaker Adaptation ,SA);非特定人 (Speaker Independent ,SI);特定人 (Speaker Dependent ,SD) 『SA+SI』
自适应凡是分类:批处理式、在线式、立即式 | 监督 无监督
自适应经典算法:基于最大后验概率 (Maximum a posteriori ,MAP) 的算法、基于变换的算法『Tip : 对于掌握SA技术,先学习SI语音识别技术相关知识』
- 基本MAP算法
『初次见解: 类似极大似然,就是找出概率最大的匹配(注意:匹配项必需已给定)』『第二次见解:贝叶斯学习理论,从假设范围中选取最佳假设』
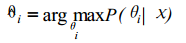
其中 χ为训练样本 ,θ i 为第 i 个语音模型的参数 ,为模型参数的最大后验概率估计值。
- 基于线性预测的 MAP 算法
基本假设是:不同语音模型间的关系可以用线性函数表示,其过程为 : 利用 SI系统的训练语音库统计出不同语音的模型参数间的线性关系 ,在自适应时对于未出现的语音的模型 ,用已出现的语音的自适应结果以及线性关系预测其自适应结果:
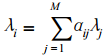
其中 ,λ为语音模型参数 , i 为训练语音中未出现的某语音模型编号 , j 为出现的语音模型编号 ,αij为事先训练好的预测参数
- 矢量场平滑 (Vector Field Smoothing ,VFS) 算法
基本假设是:不同语音模型自适应后的变化量是一个连续函数 ,因此我们可以用已出现语音模型自适应后的变化量预测相邻的未出现语音的模型的变化量 ,从而获得未出现语音模型的自适应结果:

其中{λj , j = 1 ,2 , …, M} 为已出现语音的模型参数 ,λi 为未出现语音的模型参数. 这里αij是训练好的预测参数
- 马尔科夫随机场 (Markov Random Field ,MRF) 算法『待查阅』
基本假设是:码本的均值可以用二维随机场中的点来表示“相近”的码本相互连通 , 两两连通的点的集合构成了一个类 , 类的先验概率用 Gibbs 分布来描述. 自适应过程按类进行 ,因此可以对未出现过的语音做自适应.
基本假设是:相近语音的 SI 系统语音空间与被适应人语音空间的变换关系也是相近的 ,因此可以利用训练语音中出现过的语音统计出这一变换关系 ,对未出现的语音的模型用该变换实现从 SI 系统到被适应人语音空间的映射 ,从而完成自适应过程。语音空间根据一定测度 (如欧氏距离 ,似然度等) 被划分为 R类 ,各类的变换为 Tr (·) ,分别对应的训练语音集为Xr , r = 1 ,2 , …, R ,模型参数为 λr , r = 1 ,2 ,…, R ,则最优的自适应变换满足 :
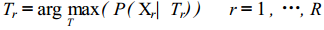
自适应后的参数λr , r = 1 ,2 , …, R满足 :

- 最大似然线性回归 (Maximum Likelihood Linear Regression ,MLLR) 算法

该算法采用的变换形式是仿射变换 ,即:
y = Ax + b
x 为自适应前的参数矢量 ; y为自适应后的参数矢量 ;A、 b分别为根据自适应训练语音 ,用最大似然准则估计出的变换参数.
- 随机匹配 (Stochastic Match ,SM) 算法
采用的变换形式是平移变换 :
y = x + b
式中各项的意义与 MLLR 算法中相同.
- 非线性变换算法
References:
李虎生, 刘加, 刘润生. 语音识别说话人自适应研究现状及发展趋势[J]. 电子学报, 2003, 31(1):103-108. DOI:10.3321/j.issn:0372-2112.2003.01.027.