一、前言
目前,企业中大多数数项目中都会用redis做缓存,既然用了缓存,就可能会涉及到redis和数据库的双写,那么就一定会遇到数据一致性问题,我们该怎么解决一致性问题呢?
我想每家企业都会根据自己业务的需要有一套自己的解决方案,下面我们来分析一下常见的方案。
二、Redis做为只读缓存
2.1 先删除缓存再更新数据库
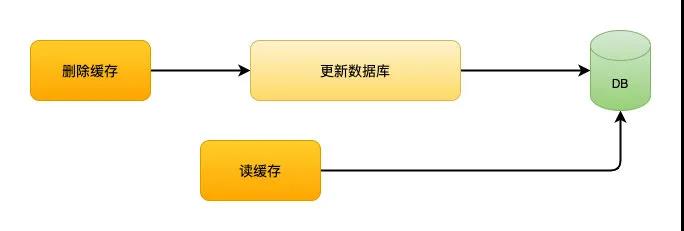
在对数据进行更新的时候先删除缓存,再更新数据库,在单线程情况下这个方案不会有问题,但是在并发比较高的情况下就会出现问题了,我们看一下下面这个例子。
假设有A、B两个请求,请求A做更新操作,请求B做查询读取操作:
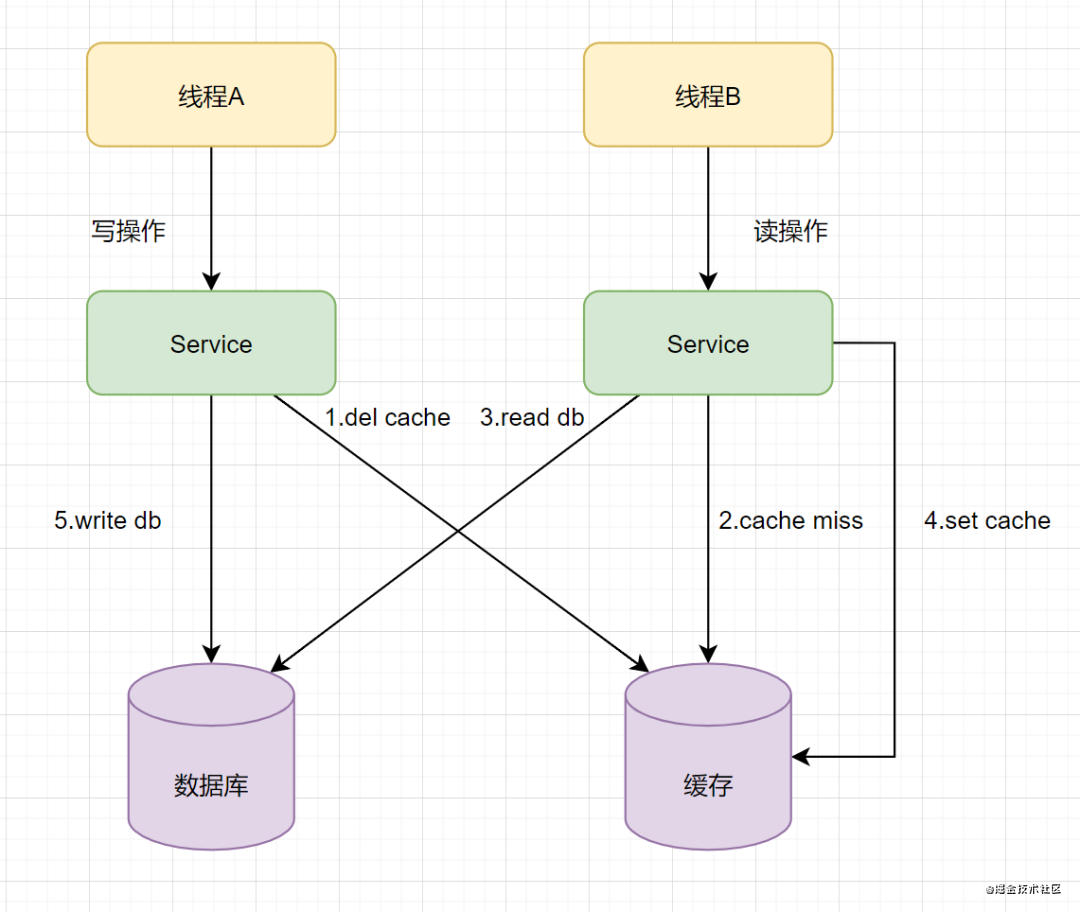
- 线程A发起一个写操作,首先删除缓存。
- 此时线程B发起一个读操作,查询缓存没有命中,接着从数据库读取结果,设置缓存后返回。
- 此时线程A将数据库更新成新数据。
这样子就有问题了,缓存和数据库就不一致了。缓存保存的是老数据,数据库中存的却是新数据。往后的查询操作也都会命中缓存,读到老数据。
那么这该怎么办呢?
在线程A更新完数据库的值之后,我们可以让它先sleep一小段时间,再进行一次缓存删除操作。
之所以要sleep,就是为了让线程B先能够从数据库里面读取数据,把缺失的数据写入缓存后,线程A再删除。所有线程Asleep的时间就需要大于线程B读取数据再写入缓存的时间。这个时间的值需要对接口读取和写缓存的时间进行统计,以此为基础进行估算。这种方式叫做延迟双删
2.2 先更新数据库再删除缓存
如果先更新数据库再删除缓存是不是就不会存在问题了呢?也不是的,我们再来看一个例子。
如果线程A更新了数据库中的值,还没来得及删除缓存中的值,线程B就开始读取数据了,那么线程B查询缓存时,发现命中就会直接 从缓存中读取旧值。不过,再这种情况下,如果其他线程并发读缓存请求不多,那么,就不会有很多的请求读到旧值。所以这种情况对业务影响比较小。
在大多数业务场景中,我们会把redis作为只读缓存使用。对于只读缓存,我们既可以先删除缓存再更新数据库,也可以先更新数据库再删除缓存。我建议优先使用先更新数据库再更删除缓存的方法。原因如下
- 先删除缓存再更新数据库,有可能导致请求因缓存缺失访问数据库,给数据造成压力;
- 如果业务应用中读取数据库和写缓存的时间不好估算,那么,延迟双删中的等待时间就不好设置。
如果业务层要求必须读取一致性数据,那么我们就需要在更新数据库时,现在Redis客户端暂存并发读请求,等数据更新完,缓存值删除后,再读取数据,从而保证一致性。
2.3 借助消息队列删除
这是对先更新数据库再删除缓存时,删除删除缓存失败的情况的完善,整个流程如下图
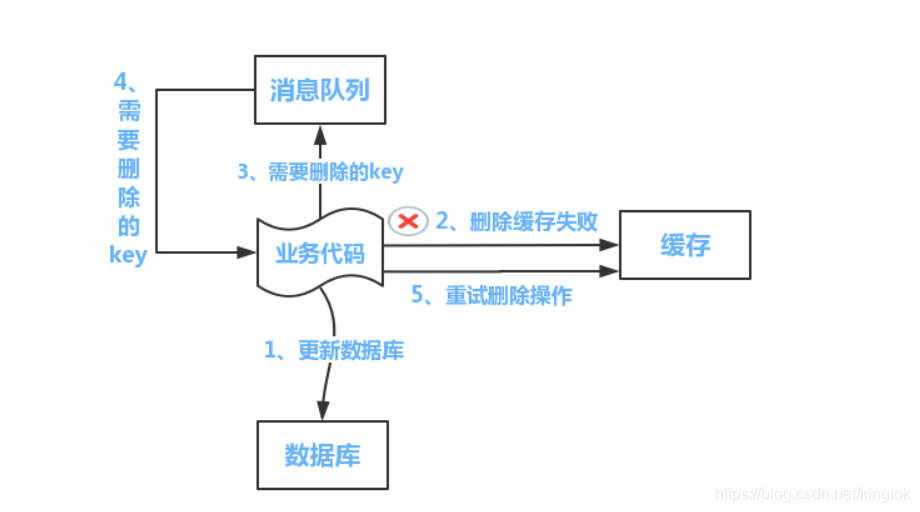
流程如下所示
(1)更新数据库数据;
(2)缓存因为种种问题删除失败
(3)将需要删除的key发送至消息队列
(4)自己消费消息,获得需要删除的key
(5)继续重试删除操作,直到成功
然而,该方案有一个缺点,对业务线代码造成大量的侵入。于是有了方案二,在方案二中,启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。
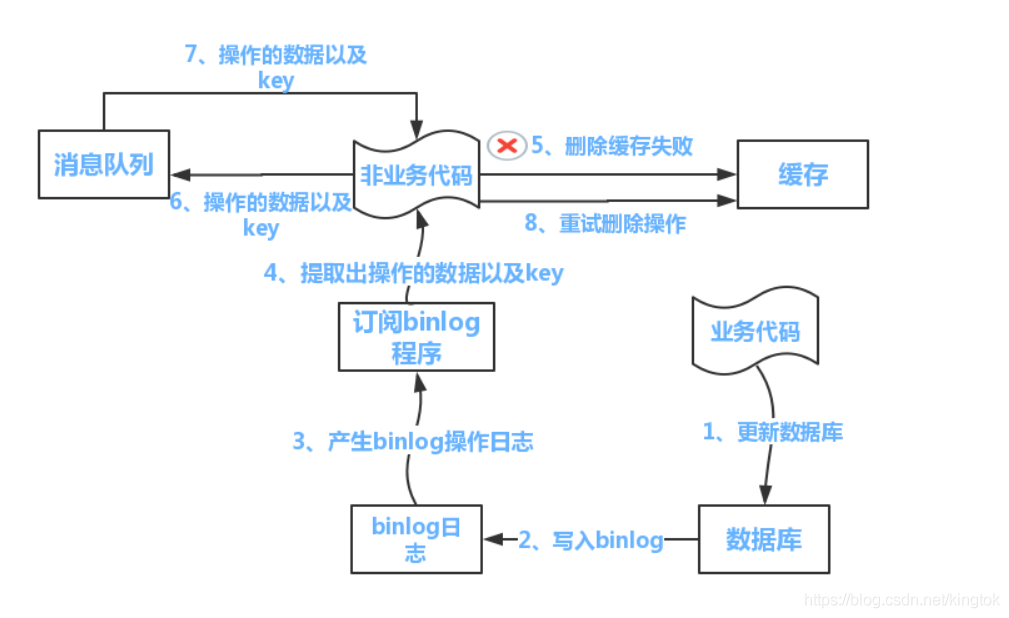
- 可以使用阿里的canal将binlog日志采集发送到MQ队列里面
- 然后通过ACK机制确认处理这条更新消息,删除缓存,保证数据缓存一致性
三、Redis做为读写缓存
先更新数据库再更新缓存
这种情况下,如果更新数据库成功,但是更新缓存失败,此时数据库中是最新值,但缓存中是旧值,后续请求直接命名缓存得到旧值。
先更新缓存再更新数据库
如果数据库更新失败,此时缓存中是新值数据库中是旧值,后续请求命中缓存,但是得到新值,短期内可能影响不大,但是一旦缓存过期或淘汰,读请求会从数据库中读取旧值,并设置到缓存中,之后都会读取旧值,对业务产生影响。
针对这种其中有一次操作可能失败的情况,也可以使用重试机制解决,把第二步放入消息队列中,消费者从消息队列取出消息,在更新数据库或缓存,以此达到最终一致性。
以上是没有并发请求的情况。如果存在并发读写,也会产生不一致,分为以下4种场景。
1、先更新数据库,再更新缓存,写+读并发:线程A先更新数据库,之后线程B读取数据,此时线程B会命中缓存,读取到旧值,之后线程A更新缓存成功,后续的读请求会命中缓存得到最新值。这种场景下,线程A未更新完缓存之前,在这期间的读请求会短暂读到旧值,对业务短暂影响。
2、先更新缓存,再更新数据库,写+读并发:线程A先更新缓存成功,之后线程B读取数据,此时线程B命中缓存,读取到最新值后返回,之后线程A更新数据库成功。这种场景下,虽然线程A还未更新完数据库,数据库会与缓存存在短暂不一致,但在这之前进来的读请求都能直接命中缓存,获取到最新值,所以对业务没影响。
3、先更新数据库,再更新缓存,写+写并发:线程A和线程B同时更新同一条数据,更新数据库的顺序是先A后B,但更新缓存时顺序是先B后A,这会导致数据库和缓存的不一致。
4、先更新缓存,再更新数据库,写+写并发:与场景3类似,线程A和线程B同时更新同一条数据,更新缓存的顺序是先A后B,但是更新数据库的顺序是先B后A,这也会导致数据库和缓存的不一致。
场景1和2对业务影响较小,场景3和4会造成数据库和缓存不一致,影响较大。也就是说,在读写缓存模式下,写+读并发对业务的影响较小,而写+写并发时,会造成数据库和缓存的不一致。
针对场景3和4的解决方案是,对于写请求,需要配合分布式锁使用。写请求进来时,针对同一个资源的修改操作,先加分布式锁,这样同一时间只允许一个线程去更新数据库和缓存,没有拿到锁的线程把操作放入到队列中,延时处理。用这种方式保证多个线程操作同一资源的顺序性,以此保证一致性。
综上,使用读写缓存同时操作数据库和缓存时,因为其中一个操作失败导致不一致的问题,同样可以通过消息队列重试来解决。而在并发的场景下,读+写并发对业务没有影响或者影响较小,而写+写并发时需要配合分布式锁的使用,才能保证缓存和数据库的一致性。