本文来自网络,属于对各评价指标的总结,如果看完之后,还不是很理解,可以针对每个评价指标再单独搜索一些学习资料。加油~!
对于分类算法,常用的评价指标有:
(1)Precision
(2)Recall
(3)F-score
(4)Accuracy
(5)ROC
(6)AUC
ps:不建议翻译成中文,尤其是Precision和Accuracy,容易引起歧义。
1.混淆矩阵
混淆矩阵是监督学习中的一种可视化工具,主要用于比较分类结果和实例的真实信息。矩阵中的每一行代表实例的预测类别,每一列代表实例的真实类别。
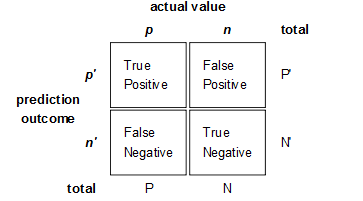
图1 混淆矩阵
如图1所示,在混淆矩阵中,包含以下四种数据:
a、真正(True Positive , TP):被模型预测为正的正样本
b、假正(False Positive , FP):被模型预测为正的负样本
c、假负(False Negative , FN):被模型预测为负的正样本
d、真负(True Negative , TN):被模型预测为负的负样本
根据这四种数据,有四个比较重要的比率,其中TPR和TNR更为常用:
-
真正率(True Positive Rate , TPR)【灵敏度(sensitivity)】:TPR = TP /(TP + FN) ,即正样本预测结果数/ 正样本实际数
-
假负率(False Negative Rate , FNR) :FNR = FN /(TP + FN) ,即被预测为负的正样本结果数/正样本实际数
-
假正率(False Positive Rate , FPR) :FPR = FP /(FP + TN) ,即被预测为正的负样本结果数 /负样本实际数
-
真负率(True Negative Rate , TNR)【特指度(specificity)】:TNR = TN /(TN + FP) ,即负样本预测结果数 / 负样本实际数
2.评价指标
1)(Precision): P = TP/(TP+FP)
2)(Recall): R = TP/(TP+FN),即真正率
3)F-score:Precision和Recall的调和平均值, 更接近于P, R两个数较小的那个: F=2* P* R/(P + R)
4)(Aaccuracy): 分类器对整个样本的判定能力,即将正的判定为正,负的判定为负: A = (TP + TN)/(TP + FN + FP + TN)
5)ROC(Receiver Operating Characteristic):ROC的主要分析工具是一个画在ROC空间的曲线——ROC curve,横坐标为false positive rate(FPR),纵坐标为true positive rate(TPR)。
如何画ROC曲线?
对于二值分类问题,实例的值往往是连续值,通过设定一个阈值,将实例分类到正类或者负类(比如大于阈值划分为正类)。因此,可以变化阈值,根据不同的阈值进行分类,根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。ROC curve经过(0,0) (1,1),实际上(0,0)和(1,1)连线形成的ROC curve实际上代表的是一个随机分类器。一般情况下,这个曲线都应该处于(0,0)和(1,1)连线的上方,如图2所示。
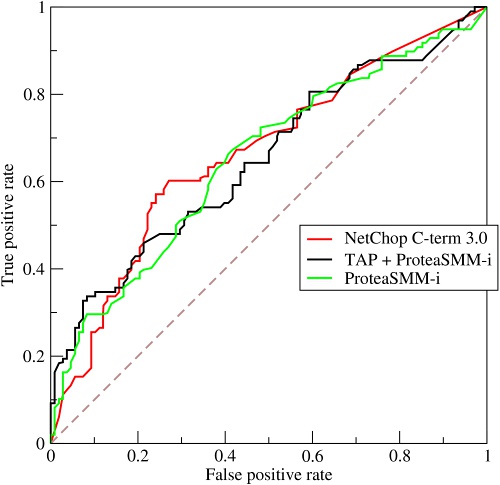
图2 ROC曲线
ROC上几个关键点的解释:
(TPR=0,FPR=0):把每个实例都预测为负类的模型
(TPR=1,FPR=1):把每个实例都预测为正类的模型
(TPR=1,FPR=0):理想模型,全部预测正确
(TPR=0,FPR=1):最差模型,全部预测错误
一个好的分类模型应该尽可能靠近图形的左上角,而一个随机猜测模型应位于连接点(TPR=0,FPR=0)和(TPR=1,FPR=1)的主对角线上。
既然已经这么多评价标准,为什么还要使用ROC和AUC呢?
因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
6)AUC(Area Under ROC Curve)
AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的performance。如果模型是完美的,那么它的AUG = 1,如果模型是个简单的随机猜测模型,那么它的AUG = 0.5,如果一个模型好于另一个,则它的曲线下方面积相对较大。