一张图片有可以被表示为三维数组的形式,每个像素值从0到255
图像属性:染色通道 。
彩色图有三个:r,g,b。
黑白图有一个染色通道。例如某图片:300*100*3,值越大越黑。(图像是三维的 H*W*C)
对图片处理面对的挑战:光照角度,光照强度,形状改变,部分遮蔽,背景混入
机器学*常规套路:
1.收集数据并给定标签
2.训练一个分类器
3.测试,评估
K-*邻
对于不同的参数的选择对结果产生影响
对未知类别属性数据集中的点:
1.计算已知类别数据集中的点与当前点的距离
2.按照距离依次排序
3.选取与当前点距离最小的K个点
4.确定前K个点所在的类别出现的概率
5.返回前K个点出现频率最高的类别作为当前点预测分类
对于图像处理模块使用K*邻:
1.选取超参数的方法:将原始训练集分为训练集和验证集,我们在验证机上尝试不同的超参数,最后保留表现最好的
2.如果训练数据量不够,使用交叉验证的方法,帮助我们选取最优超参数的时候减少噪音
3.一旦找到最优的超参数,让算法以该参数在测试集跑且只跑一次,并根据测试结果评价算法
4,最*邻分类器能够在CIFAR-10上得到将*40%的准确率。该算法简单易实现,但需要存储所有训练数据,并且在测试的时候过于消耗计算能力
5.仅仅使用L1,L2范数来进行像素的比较是不够的,图像更多的时按照背景和颜色分类,而不是语义主体分身。
数据库样例:CIFAR-10
10个嘞标签
50000个训练数据
10000个测试数据
大小均为32*32
方式:计算像素点之间的差异值distance,像素点越小越暗
超参数:K*邻算法-4.超参数 - 凌晨四点的洛杉矶 - 博客园 (cnblogs.com)
- 超参数:在算法运行之前需要决定的参数
- 模型参数:算法过程中学*到的参数
KNN算法作为最简单的机器学*算法,它没有模型参数,下面讨论它的超参数
加载数据集:
from sklearn import datasets, neighbors, model_selection data = datasets.load_digits() x = data.data y = data.target x_train,x_test,y_train,y_test = model_selection.train_test_split(x,y,test_size=0.2)
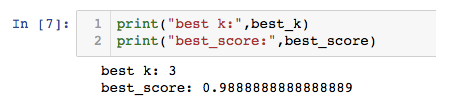
寻找最好的k:
best_score = 0.0
best_k = -2
for k in range(1,15):
knn_clf = neighbors.KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(x_train,y_train)
score = knn_clf.score(x_test,y_test)
if score > best_score:
best_k = k
best_score = score
训练集(train)验证集(validation)测试集(test)与交叉验证法
用交叉验证进行选择
训练集(train)验证集(validation)测试集(test)与交叉验证法 - 知乎 (zhihu.com)
交叉验证与训练集、验证集、测试集_九城风雪的博客-CSDN博客_交叉验证集
背景主导:如何让背景不影响,只让主题参加?