在网上查阅了好几个EXCEL转Json的代码,有的是仅支持一个层级的Json(这个就不支持多层级的json),有的太过复杂看的不是很懂,所以就自己写了一个目前符合自己使用的代码。
我先讲下实现的方式。
如果遇到一个如下的json格式,我该怎么存到excel方便读取出来呢?
{
"name": "haha",
"value": 12,
"floor_area": 43.5,
"categories": [
{
"id": 1,
"extra_property": "xixi",
"renovation_type": [
1,
2
],
"subcategories": [
{
"subcategory_id": 1,
"subcategory_value": 2
}
]
}
]
}
这是个多维json,存在excel中不是很好存放,读取出来也得花点心思,毕竟你不知道后期又会有什么格式的json出现。为了应对千奇百怪的json格式,我想到如下方式
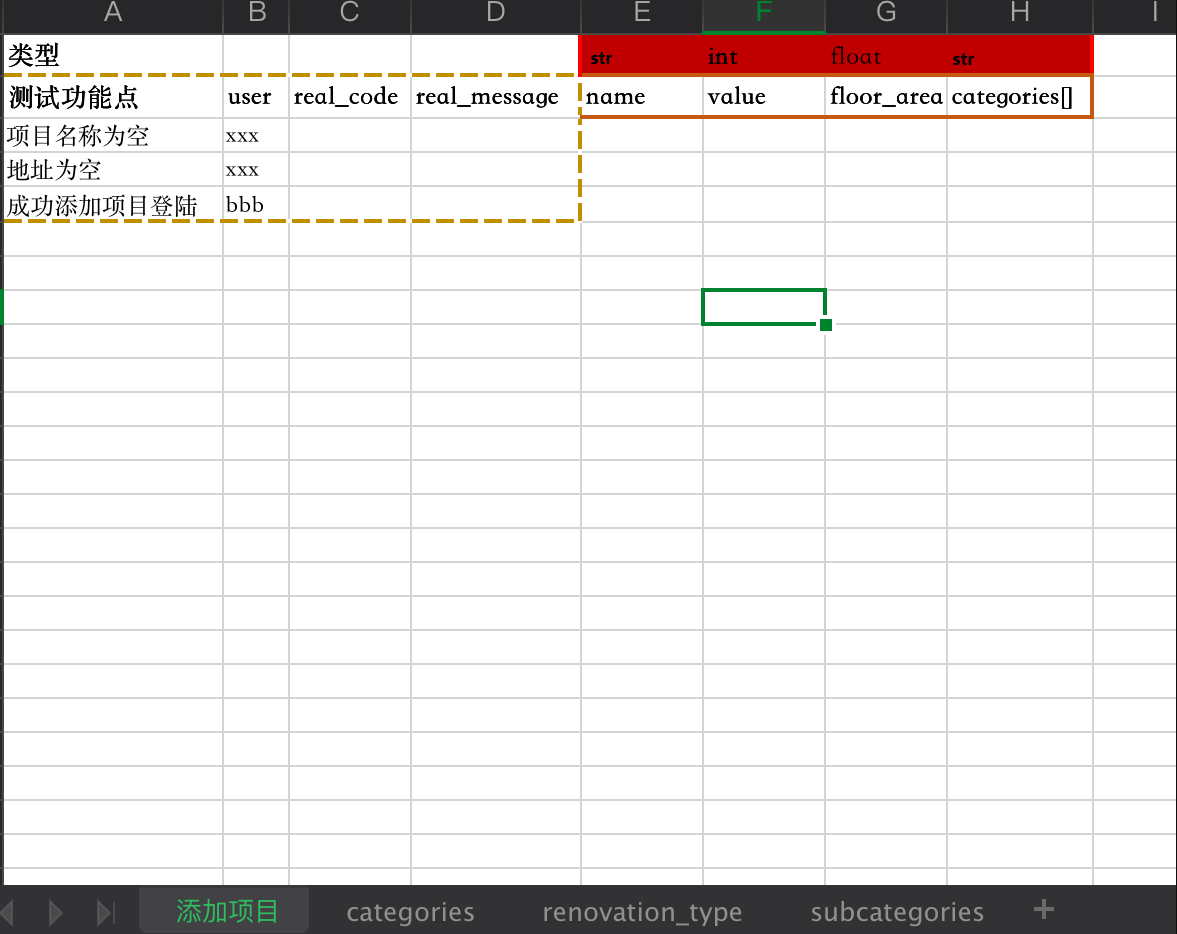
上图中特别标注的,可以划分为三个部分,以下对这三个部分进行讲解。
区域一(功能校验区域):
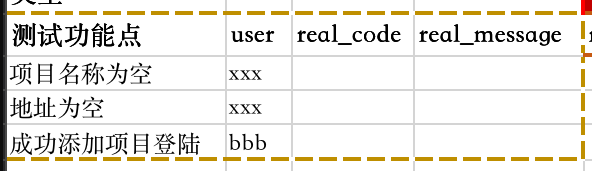
user:登陆的用户或操作的用户
real_code:预计接口执行操作后需要返回的code值,如200、401等
real_message:预计接口执行操作后需要返回的message,如“请求成功‘、”无操作权限“等
区域二(参数类型区域):

传递参数的类型无外乎这几种:int、str、float、boolean。同样我们需要告诉代码这个参数是什么类型的参数,以免传递数据的时候发生参数类型错误。在代码中我做了处理,可以识别常用的四种类型(不区分大小写)。
区域三(参数区域):


如果是数组类型的数据,用"[]"来标记,不同的数据存储在不同的单元格中,如:

看到图的时候你会问:为什么sheet里面会有参数的名称?

我们可以看出“categories”是个哈希,底下还存在不同的参数。为了知道哪些参数是在“categories”下的,我们可以用一张sheet去存储“categories”参,这样我们可以通过代码方便去找到。
有可能“categories”存在多组数据,所以我们需要用"[]"来告知代码。要读取那些数据,我们可以存储行号,不同的行号可以用顿号分隔
附上代码:
# -*- coding: utf-8 -*-
# !/usr/bin/python3
import os
import re
import xlrd
import json
import unicodedata
_author_ = 'garcia'
class DataCenter:
def __init__(self):
# Default File Path:
self.data_dir = os.getenv('AUTO_DATACENTER', '存放excel的文件夹地址')
self.filename = ''
self.path = ''
self.sheetNames = ''
@staticmethod
def is_number(val):
"""判断val是否是str"""
try:
return True
except ValueError:
pass
try:
unicodedata.numeric(val)
return True
except (TypeError, ValueError):
pass
def keep_integer_type_from_excel(self, value):
# Keep integer number as integer type. When reading from excel it has been changed to float type.
if self.is_number(value) and type(value) != str and value % 1 == 0:
return int(value)
else:
return value
def change_field_type(self, table, col, val):
# 字段类型转换
field_type = table.cell(0, col).value
val = self.keep_integer_type_from_excel(val)
try:
if val == '' or val is None:
pass
elif field_type.lower() == 'int':
return int(val)
elif field_type.lower() == 'float':
return float(val)
elif field_type.lower() == 'boolean':
return int(bool(val))
elif field_type.lower() == 'str' or field_type == '' or field_type is None:
return str(val)
else:
return '字段类型错误!'
except Exception as e:
print(e)
@staticmethod
def unic(item):
# Resolved Chinese mess code.
try:
item = json.dumps(item, ensure_ascii=False, encoding='UTF-8')
except UnicodeDecodeError:
try:
item = json.dumps(item, ensure_ascii=False, encoding='UTF-8')
except:
pass
except:
pass
# Convert json data string back
item = json.loads(item, encoding='UTF-8')
return item
@staticmethod
def get_sheet_names(wb):
"""
Returns the names of all the worksheets in the current workbook.
"""
sheet_names = wb.sheet_names()
return sheet_names
@staticmethod
def __convert_to_list(val):
"""转换字符串为list"""
value_list = re.split(',|,|、', val)
for i in range(len(value_list)):
value_list[i] = int(value_list[i])
return value_list
def get_table(self, sheet_name):
if self.path is None:
# Default Data Directory
file = os.path.join(self.data_dir, self.filename)
else:
file = os.path.join(self.path, self.filename)
try:
excel_date = xlrd.open_workbook(file)
# 得到excel的全部sheet标签值
self.sheetNames = self.get_sheet_names(excel_date)
my_sheet_index = self.sheetNames.index(sheet_name)
table = excel_date.sheet_by_index(my_sheet_index)
except Exception as e:
print(e)
return table
@staticmethod
def get_row_and_col(table):
"""获取列数、行数"""
total_row = table.nrows
total_col = table.ncols
return total_row, total_col
@staticmethod
def get_param(table, start_col, total_col):
param_list = [] # 获取参数
for col in range(start_col, total_col):
param = table.cell(1, col).value # 获取字段名
if param is None or param == '':
param_list.append(param_list[-1])
else:
param_list.append(param)
return param_list
def get_child_param(self, param, row, includeEmptyCells):
if param in self.sheetNames:
table = self.get_table(param)
child_total_row, child_total_col = self.get_row_and_col(table)
child_param = self.get_param(table, 1, child_total_col)
data_dic = {}
count = 0
for col in range(1, child_total_col):
# Solve issue that get integer data from Excel file would be auto-changed to float type.
val = self.change_field_type(table, col, table.cell(row, col).value)
param = child_param[count]
count += 1
if '[]' in param:
if val == '' or val is None:
pass
else:
param = param[:param.index('[')]
data_dic[param] = [] if param not in data_dic.keys() else data_dic[param]
if param in self.sheetNames:
val_list = self.__convert_to_list(val)
for i in range(len(val_list)):
data_dic[param].append(
self.get_child_param(param, val_list[i] - 1, includeEmptyCells))
else:
data_dic[param].append(val)
else:
if param in self.sheetNames:
if val is not None and val != '':
val_list = self.__convert_to_list(val)
for i in range(len(val_list)):
data_dic[param] = self.get_child_param(param, val_list[i] - 1, includeEmptyCells)
elif (val == '' or val is None) and includeEmptyCells == 'False':
pass
else:
data_dic[param] = val
return data_dic
def param_to_json(self, filename, sheet_name, includeEmptyCells, path=None):
"""
获取指定sheet中接口参数
:param filename: 文件名
:param sheet_name: 读取excel的sheet名称
:param path:文件路径
:return:
"""
try:
self.filename = filename
self.path = path
table = self.get_table(sheet_name)
total_row, total_col = self.get_row_and_col(table)
function_point_list = []
check_list = []
user_list = []
all_data_list = []
param_list = self.get_param(table, 4, total_col)
for row in range(2, total_row):
data_dic = {}
get_check_list = []
count = 0
for col in range(4, total_col):
# Solve issue that get integer data from Excel file would be auto-changed to float type.
val = self.change_field_type(table, col, table.cell(row, col).value)
param = param_list[count]
count += 1
if '[]'in param:
if val == '' or val is None:
pass
else:
param = param[:param.index('[')]
data_dic[param] = [] if param not in data_dic.keys() else data_dic[param]
if param in self.sheetNames:
val_list = self.__convert_to_list(val)
for i in range(len(val_list)):
data_dic[param].append(
self.get_child_param(param, val_list[i] - 1, includeEmptyCells))
else:
data_dic[param].append(val)
else:
if param in self.sheetNames:
if val is not None and val != '':
val_list = self.__convert_to_list(val)
for i in range(len(val_list)):
data_dic[param] = self.get_child_param(param, val_list[i] - 1, includeEmptyCells)
else:
pass
elif (val == '' or val is None) and includeEmptyCells == 'False':
pass
else:
data_dic[param] = val
print(data_dic)
get_check_list.append(self.keep_integer_type_from_excel(table.cell(row, 2).value))
get_check_list.append(self.keep_integer_type_from_excel(table.cell(row, 3).value))
check_list.append(get_check_list)
all_data_list.append(data_dic)
user_list.append(table.cell(row, 1).value)
function_point_list.append(table.cell(row, 0).value)
except Exception as e:
print(e)
# return all_data_list, function_point_list
return user_list, all_data_list, function_point_list, check_list
if __name__ == '__main__':
dc = DataCenter()
userlist, allList, FunctionPoint, checklist = dc.param_to_json('存放数据的excel名称', 'sheet名', 'False')
print(userlist, allList, FunctionPoint, checklist)
说到这,我们来讲讲她的缺点:
1、如果存在多张表的嵌套,代码执行的时间比较长