索引
可以理解为一种特殊的目录,索引是通过二叉树的数据结构来描述的。
聚集索引(clustered index,也称聚类索引、簇集索引)
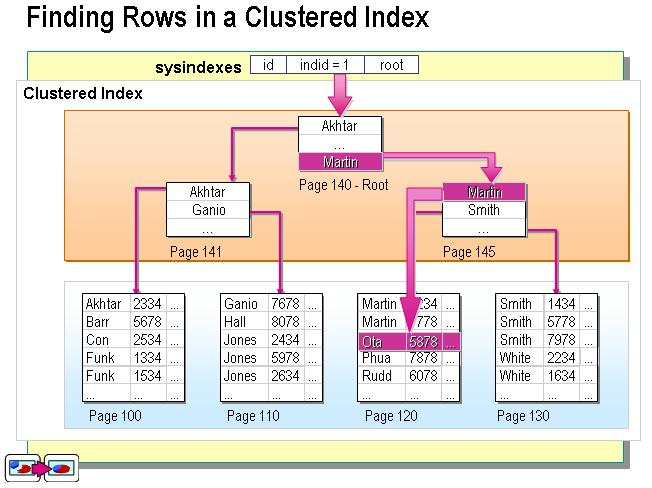
是一种键值的逻辑顺序决定了表中相应行的物理顺序的索引,索引的叶节点就是数据节点
由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引。但该索引可以包含多个列(组合索引),就像电话簿按姓氏和名字进行组织一样。
聚集索引对于那些经常要搜索范围值的列特别有效。使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻。
同样,如果对从表中检索的数据进行排序时经常要用到某一列,则可以将该表在该列上聚集(物理排序),避免每次查询该列时都进行排序,从而节 省成本。
当索引值唯一时,使用聚集索引查找特定的行也很有效率。例如,使用唯一雇员 ID 列 emp_id 查找特定雇员的最快速的方法,是在 emp_id 列上创建聚集索引或 PRIMARY KEY 约束。

非聚集索引(nonclustered index,也称非聚类索引、非簇集索引)
是一种索引的逻辑顺序与磁盘上行的物理存储顺序不同的索引,非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
非聚集索引中的项目按索引键值的顺序存储,而表中的信息按另一种顺序存储(这可以由聚集索引规定)。
对于非聚集索引,可以为在表非聚集索引中查找数据时常用的每个列创建一个非聚集索引。
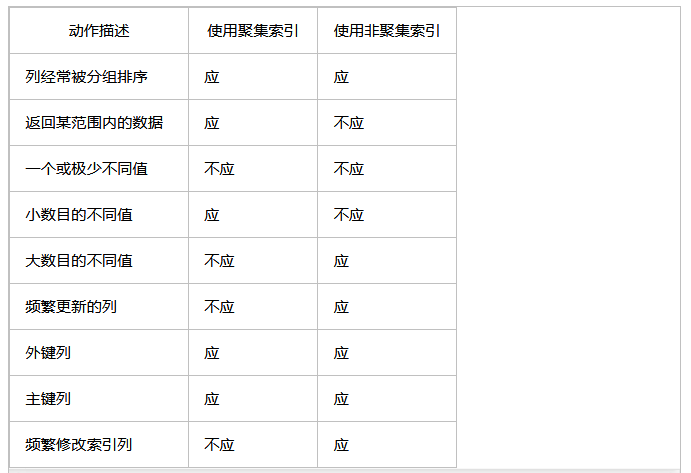
使用聚集索引或非聚集索引的情景
一个表只能有一个聚集索引和多个非聚集索引
想要深入理解聚合索引和非聚合索引的童鞋请打开以下链接
http://www.cnblogs.com/aspnethot/articles/1504082.html