YOLO3主要的改进有:调整了网络结构;利用多尺度特征进行对象检测;对象分类用Logistic取代了softmax。
1.Darknet-53 network
在论文中虽然有给网络的图,但我还是简单说一下。这个网络主要是由一系列的1x1和3x3的卷积层组成(每个卷积层后都会跟一个BN层和一个LeakyReLU)层,作者说因为网络中有53个convolutional layers,所以叫做Darknet-53(我数了下,作者说的53包括了全连接层但不包括Residual层)。下图就是Darknet-53的结构图,在右侧标注了一些信息方便理解。(卷积的strides默认为(1,1),padding默认为same,当strides为(2,2)时padding为valid)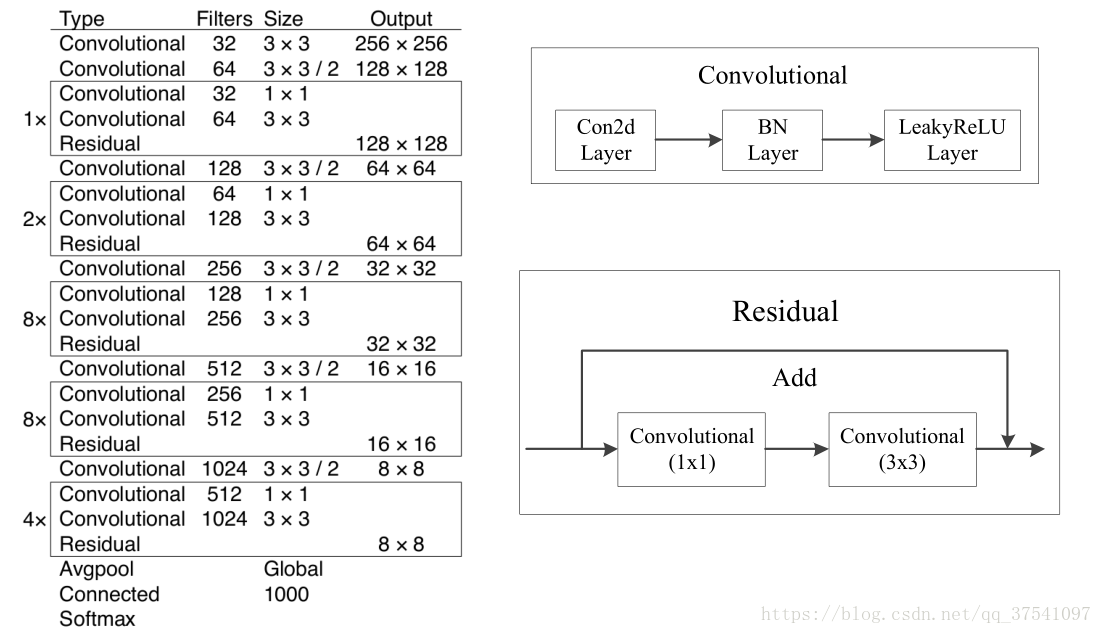
看完上图应该就能自己搭建出Darknet-53的网络结构了,上图是以输入图像256 x 256进行预训练来进行介绍的,常用的尺寸是416 x 416,都是32的倍数。下面我们再来分析下YOLOv3的特征提取器,看看究竟是在哪几层Features上做的预测。

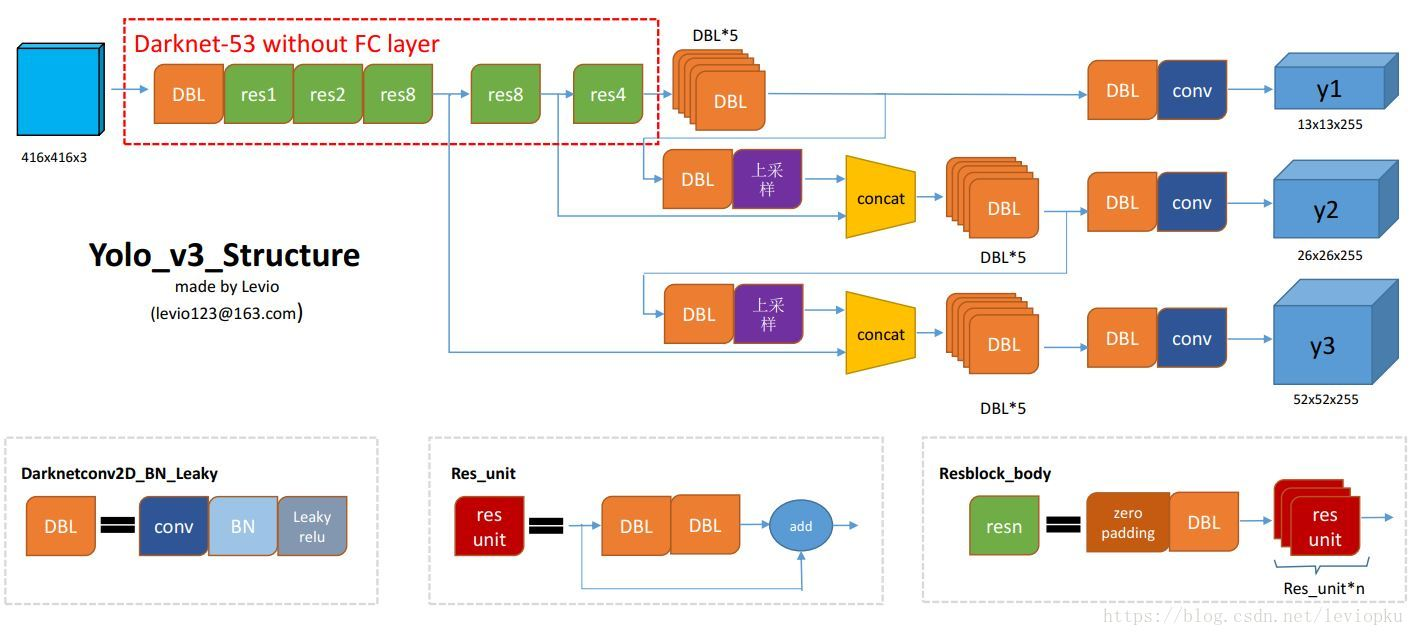
整个v3结构里面,是没有池化层和全连接层的。前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)。在yolo_v2中,要经历5次缩小,会将特征图缩小到原输入尺寸的1/32。输入为416x416,则输出为13x13(416/32=13)。
yolo_v3也和v2一样,backbone都会将输出特征图缩小到输入的1/32。所以,通常都要求输入图片是32的倍数。
yolo_v3并没有那么追求速度,而是在保证实时性(fps>60)的基础上追求performance。不过还有一个tiny-darknet作为backbone可以替代darknet-53,在官方代码里用一行代码就可以实现切换backbone。搭用tiny-darknet的yolo,也就是tiny-yolo在轻量和高速两个特点上,显然是state of the art级别。
2.利用多尺度特征进行对象检测
结合上图看,卷积网络在79层后,经过下方几个黄色的卷积层得到一种尺度的检测结果。相比输入图像,这里用于检测的特征图有32倍的下采样。比如输入是416*416的话,这里的特征图就是13*13了。由于下采样倍数高,这里特征图的感受野比较大,因此适合检测图像中尺寸比较大的对象。
为了实现细粒度的检测,第79层的特征图又开始作上采样(从79层往右开始上采样卷积),然后与第61层特征图融合(Concatenation),这样得到第91层较细粒度的特征图,同样经过几个卷积层后得到相对输入图像16倍下采样的特征图。它具有中等尺度的感受野,适合检测中等尺度的对象。
最后,第91层特征图再次上采样,并与第36层特征图融合(Concatenation),最后得到相对输入图像8倍下采样的特征图。它的感受野最小,适合检测小尺寸的对象。
随着输出的特征图的数量和尺度的变化,先验框的尺寸也需要相应的调整。YOLO2已经开始采用K-means聚类得到先验框的尺寸,YOLO3延续了这种方法,为每种下采样尺度设定3种先验框,总共聚类出9种尺寸的先验框。在COCO数据集这9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。
分配上,在最小的13*13特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。中等的26*26特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。较大的52*52特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。

感受一下9种先验框的尺寸,下图中蓝色框为聚类得到的先验框。黄色框式ground truth,红框是对象中心点所在的网格。

预测对象类别时不使用softmax,改成使用logistic的输出进行预测。这样能够支持多标签对象(比如一个人有Woman 和 Person两个标签)。
输入映射到输出

不考虑神经网络结构细节的话,总的来说,对于一个输入图像,YOLO3将其映射到3个尺度的输出张量,代表图像各个位置存在各种对象的概率。
我们看一下YOLO3共进行了多少个预测。对于一个416*416的输入图像,在每个尺度的特征图的每个网格设置3个先验框,总共有 13*13*3 + 26*26*3 + 52*52*3 = 10647 个预测。每一个预测是一个(4+1+80)=85维向量,这个85维向量包含边框坐标(4个数值),边框置信度(1个数值),对象类别的概率(对于COCO数据集,有80种对象)。
对比一下,YOLO2采用13*13*5 = 845个预测,YOLO3的尝试预测边框数量增加了10多倍,而且是在不同分辨率上进行,所以mAP以及对小物体的检测效果有一定的提升。