摘要:
- Mask RCNN可以看做是一个通用实例分割架构。
- Mask RCNN以Faster RCNN原型,增加了一个分支用于分割任务。
- Mask RCNN比Faster RCNN速度慢一些,达到了5fps。
- 可用于人的姿态估计等其他任务;
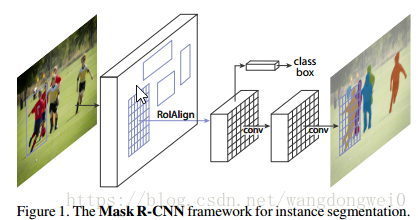
1、Introduction
- 实例分割不仅要正确的找到图像中的objects,还要对其精确的分割。所以Instance Segmentation可以看做object dection和semantic segmentation的结合。
- Mask RCNN是Faster RCNN的扩展,对于Faster RCNN的每个Proposal Box都要使用FCN进行语义分割,分割任务与定位、分类任务是同时进行的。
- 引入了RoI Align代替Faster RCNN中的RoI Pooling。因为RoI Pooling并不是按照像素一一对齐的(pixel-to-pixel alignment),也许这对bbox的影响不是很大,但对于mask的精度却有很大影响。使用RoI Align后mask的精度从10%显著提高到50%,第3节将会仔细说明。
- 引入语义分割分支,实现了mask和class预测的关系的解耦,mask分支只做语义分割,类型预测的任务交给另一个分支。这与原本的FCN网络是不同的,原始的FCN在预测mask时还用同时预测mask所属的种类。
- 没有使用什么花哨的方法,Mask RCNN就超过了当时所有的state-of-the-art模型。
- 使用8-GPU的服务器训练了两天。
2、Related Work
相比于FCIS,FCIS使用全卷机网络,同时预测物体classes、boxes、masks,速度更快,但是对于重叠物体的分割效果不好。
3、Mask R-CNN
MaskRCNN网络结构泛化图:
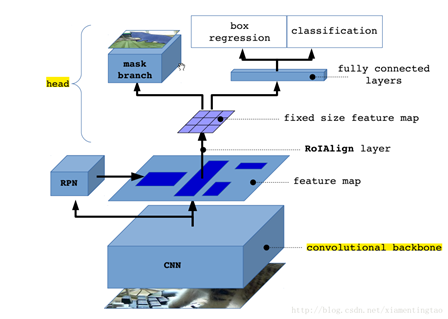
从上面可以知道,mask rcnn主要的贡献在于如下:
1. 强化的基础网络
通过 ResNeXt-101+FPN 用作特征提取网络,达到 state-of-the-art 的效果。
2. ROIAlign解决Misalignment 的问题
3. Loss Function
细节描述
1. resnet +FPN
作者替换了在faster rcnn中使用的vgg网络,转而使用特征表达能力更强的残差网络。
另外为了挖掘多尺度信息,作者还使用了FPN网络。
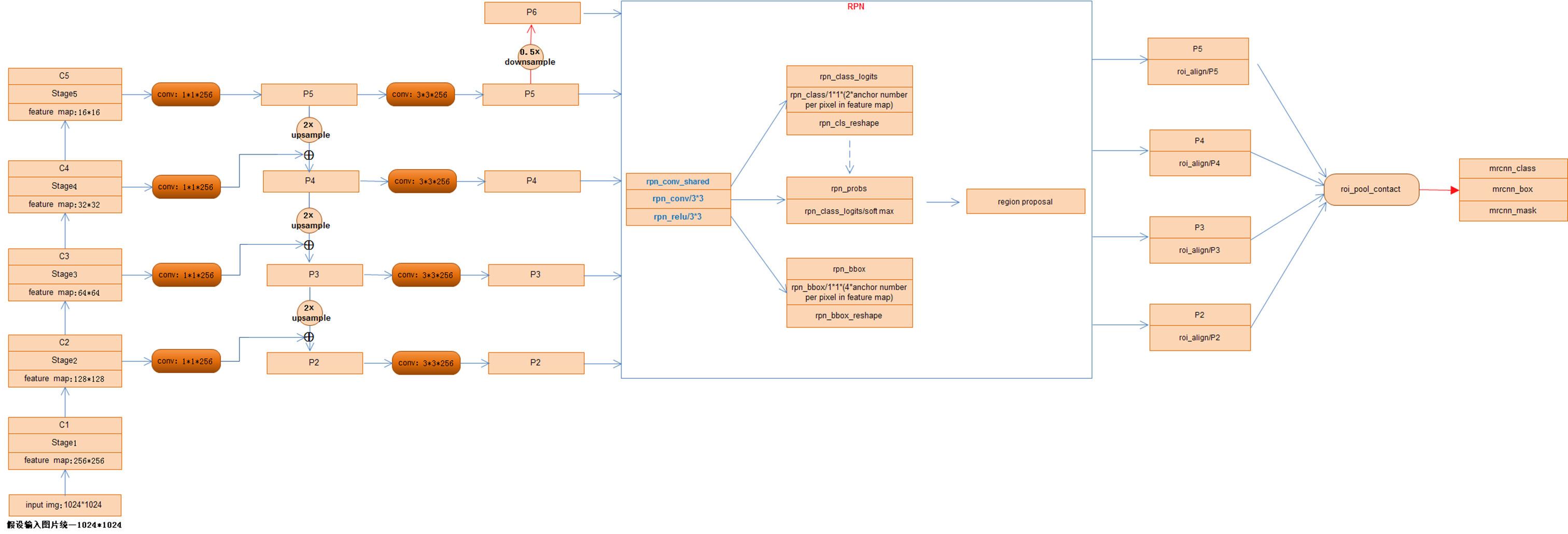
stage1和stage2层次结构图:
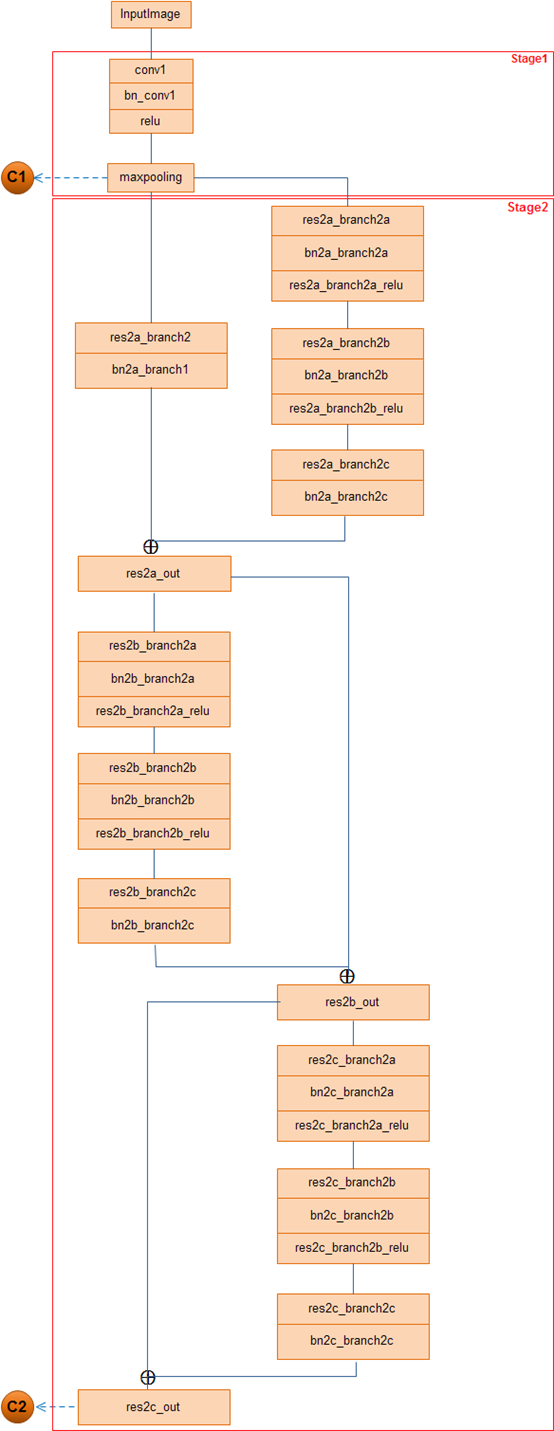

结合MaskRCNN网络结构图,注重点出以下几点:
1) 虽然事先将ResNet网络分为5个stage,但是,并没有利用其中的Stage1即P1的特征,官方的说法是因为P1对应的feature map比较大计算耗时所以弃用;相反,在Stage5即P5的基础上进行了下采样得到P6,故,利用了[P2 P3 P4 P5 P6]五个不同尺度的特征图输入到RPN网络,分别生成RoI.
2)[P2 P3 P4 P5 P6]五个不同尺度的特征图由RPN网络生成若干个anchor box,经过NMS非最大值抑制操作后保留将近共2000个RoI(2000为可更改参数),由于步长stride的不同,分开分别对[P2 P3 P4 P5]四个不同尺度的feature map对应的stride进行RoIAlign操作,将经过此操作产生的RoI进行Concat连接,随即网络分为三部分:全连接预测类别class、全连接预测矩形框box、全卷积预测像素分割mask
2. ROIAlign
对于roi pooling,经历了两个量化的过程:
第一个:从roi proposal到feature map的映射过程。方法是[x/16],这里x是原始roi的坐标值,而方框代表四舍五入。
第二个:从feature map划分成7*7的bin,每个bin使用max pooling。
这两种情况都会导致证输入和输出之间像素级别上不能一一对应(pixel-to-pixel alignment between network input and output)。
为了解决ROI Pooling的上述缺点,作者提出了ROI Align这一改进的方法。ROI Align的思路很简单:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。值得注意的是,在具体的算法操作上,ROI Align并不是简单地补充出候选区域边界上的坐标点,然后将这些坐标点进行池化,而是重新设计了一套比较优雅的流程:
- 遍历每一个候选区域,保持浮点数边界不做量化。
- 将候选区域分割成k x k个单元,每个单元的边界也不做量化。
- 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
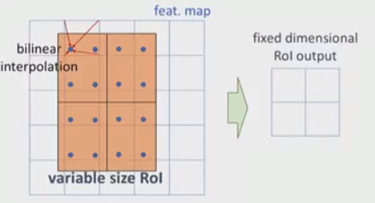
如上,roi映射到feature map后,不再进行四舍五入。然后将候选区域分割成k x k个单元, 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
3、损失函数:分类误差+检测误差+分割误差,即L=Lcls+Lbox+Lmask
Lcls、Lbox:利用全连接预测出每个RoI的所属类别及其矩形框坐标值,可以参看FasterRCNN网络中的介绍。
Lmask:
① mask分支采用FCN对每个RoI的分割输出维数为K*m*m(其中:m表示RoI Align特征图的大小),即K个类别的m*m的二值mask;保持m*m的空间布局,pixel-to-pixel操作需要保证RoI特征 映射到原图的对齐性,这也是使用RoIAlign解决对齐问题原因,减少像素级别对齐的误差。
K*m*m二值mask结构解释:最终的FCN输出一个K层的mask,每一层为一类,Log输出,用0.5作为阈值进行二值化,产生背景和前景的分割Mask
这样,Lmask 使得网络能够输出每一类的 mask,且不会有不同类别 mask 间的竞争. 分类网络分支预测 object 类别标签,以选择输出 mask,对每一个ROI,如果检测得到ROI属于哪一个分 类,就只使用哪一个分支的相对熵误差作为误差值进行计算。(举例说明:分类有3类(猫,狗,人),检测得到当前ROI属于“人”这一类,那么所使用的Lmask为“人”这一分支的mask,即,每个class类别对应一个mask可以有效避免类间竞争(其他class不贡献Loss)
② 对每一个像素应用sigmoid,然后取RoI上所有像素的交叉熵的平均值作为Lmask。
每个 ROI 区域会生成一个 m*m*numclass 的特征层,特征层中的每个值为二进制掩码,为 0 或者为 1。根据当前 ROI 区域预测的分类,假设为 k,选择对应的第 k 个 m*m 的特征层,对每个像素点应用 sigmoid 函数,然后计算平均二值交叉损失熵,如下图所示:

上图中首先得到预测分类为 k 的 mask 特征,然后把原图中 bounding box 包围的 mask 区域映射成 m*m大小的 mask 区域特征,最后计算该 m*m 区域的平均二值交叉损失熵。
训练和预测细节:

参考:
https://blog.csdn.net/wangdongwei0/article/details/83110305
https://blog.csdn.net/jiongnima/article/details/79094159
https://blog.csdn.net/xiamentingtao/article/details/78598511
http://blog.leanote.com/post/afanti.deng@gmail.com/b5f4f526490b
https://www.cnblogs.com/wangyong/p/9305347.html
https://cloud.tencent.com/developer/news/189753