本章内容:
1、设置字符串的格式
2、格式字符串
3、读写文件
4、检查文件和文件夹
5、处理文本文件
6、处理二进制文件
7、读取网页
------------------------------
程序由数据和指令来完成,我除了要编写具有逻辑关系的指令外,还需要输入对应的数据;这里,我们通常称为输入和输出;
在前面的内容里面我们介绍了input读取用户输入的字符串。我们需要指定字符串格式,然后了解I/O的读写;还有pickle模块;
1、设置字符串的格式
字符串插入式一种设置字符串格式的简单方法;
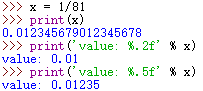
format % values 其中 %.2 和 %.5 都事一个格式配置命令;
一些转换说明符号:
d 整数
o 八进制值
x 小写十六进制数
X 大写十六进制数
e 小写科学计数表示的浮点数
E 大写的科学计数表示的浮点数
f 浮点数
s 字符串
% %字符
字符转换表示Python的字符格式:
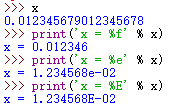
你也可以根据需要再格式字符串中包含任意数量的说明符;

如果要再字符串中包含字符%,必须使用“%%”
2、格式字符串
另一种创建美观输出的方式是结合使用格式字符串和字符串函数format(value,format_spec)例如:

在格式字符串中,用大括号括起的内容都将被替换,这称为命名替换;
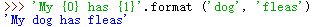
还可以像字符串插入那样使用转换说明符:
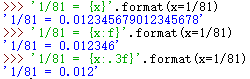
也可以使用大括号来指定格式设置参数,如下图:

3、读写文件
文件分为两种:文本文件和二进制文件
1、文本文件
a基本上是磁盘中的字符串;
b可以编辑,对于人来说,容易读取
c对于程序来说难以阅读,需要使用对应的分析程序来进行阅读
d比等价的二进制文件要打,再以太网上传输时一个非常麻烦的事,所以一般需要进行压缩
2、二进制文件
a人类无法阅读
b程序阅读非常方便
c占用空间比等价的文件要小
d于特定的程序相关联,需要使用该特定的程序来运行这些二进制文件
文件夹
Windows的文件夹表达方式:
‘C:\home\tjd\Desktop\python’
为了避免使用两个反斜线,我们可以使用 r 来指定:
r'C:home jdDesktoppython' 和上相同
mac和Linux则相同,使用 / 来表示目录,例如:
/home/tjd/Desktop/python
Python中表示当前目录的函数-- cwd()
4、检查文件和文件夹
Python提供一些函数--用来返回有关计算机文件系统中文件和文件夹的信息;
如下:一种常见的任务是获悉当前工作目录中的文件和文件夹。
# list.py def list_cwd()
return os.listdir(os.getcwd())
也可以使用列表解析分别返回当前工作目录中的文件和文件夹:
# list.py def files_cwd(): return [p for p in list_cwd() if os.path.isfile(p)] def folders_cwd(): return [p for p in list_cwd() if os.path.isdir(p)]
实用的文件和文件夹函数:
os.getcwd() 返回当前工作目录的名称
os.listdir(p) 返回一个字符串列表,其中包含路径p指定的文件夹中所有文件和文件夹名称
os.chdir(p) 将当前工作目录设置为路径p
os.path.isfile(p) 当路径p指定的是一个文件的名称时,返回True,否则返回False
os.path.isdir(p) 当路径p指定的是一个文件夹的名称时,返回True,否则返回False
os.stat(fname) 返回有关fname的信息,如大小(单位为字节)和最后一次修改时间
如果只想获取当前工作目录中的.py文件,可编写如下函数:
# list.py def list_py(path = None): if path == None path = os.getcwd() return [fname fo fname in os.listdir(path) if os .path.isifle(fname) if fname.endswith('.py')]
下面的代码函数返回当前工作目录中所有文件大小总合:
# list.py def size_in_bytes(fname): return os.stat(fname).st_size def cwd_size_in_bytes(): total = 0 for name in files_cwd(): total = total + size_in_bytes(name) return total
5、处理文本文件
处理文件分为三个步骤
逐行读取文本文件:
每次读取一行,进行处理后,例如:
# printfile.py def print_file1(fname): f = open(fname, 'r') //打开指定的文件,调用open时,必须指定你要处理的文件名称,还必须指定打开的模式。以“r”读取的模式打开 for line in f: print(line,, end= '') f.close() #这行代码是可选的
注意:open去打开文件的时候,文件没有被读取到内存中;
Python文件打开模式:
r 为读取而打开文件(默认模式)
w 为写入而打开文件
a 为在文件末尾附加而打开文件
b 二进制模式
t 文本模式(默认模式)
r+ 为读写打开文件
将整个文本文件作为一个字符串进行读取:
除了open(fname)的方式外,还可以使用下面的方式,将其作为一个大型字符串进行读取,如下所示:(比较常用)
# printfile.py def print_file2(fname) f = open(fname, 'r') print(f.read()) f.close()
这行代码同下:
print(open(fname, 'r').read())
写入文本文件:
写入文本文件只比读取文本文件复杂一点点,例如:下面这个函数新建一个名为story.txt的文本文件:
# write.py def make_story1(): f = open('story.txt', 'w') //指定为写入模式 f.write('Mary had a little lamb, ') //使用write()函数写入文本内容; f.wirte('and then she had some more. ')
需要注意的是:如果story.txt已经存在,则调用open('story.txt','w')将会将原有文件覆盖掉;
# write.py import os def make _story2(): if os.path.isfile('story.txt'): print('story.txt already exists') else: f = open('story.txt', 'w') f.wirte('Mary had a little lamb, ') f.wirte('and then she had some more. ')
附加文本文件到末尾
将字符串加入到文本文件是,一种常见的方式将它们附加到文件末尾。与模式‘w’不同的是,这种模式不会删除文件即有的内容。例如:
def add_to_story(line, fname = 'story.txt') f = open(fname, 'a') //文件一附加模式 ‘a’ 打开的 f.write(line)
将字符串插入到文件头部
我们需要将文件读取到一个字符串中,将新文本插入到该字符串,再将这个字符串写入原来的文件,如下:
def insert_title(title, fname = 'story.txt'): f = open(fname, 'r+') temp = f.read() temp = title + ' ' + temp f.seek(o) #让文件指针指向文件开头 f.write(temp)
f.read() 使得文件指针指向文件末尾,而f.seek()则将指针指向文件开头;
6、处理二进制文件
在Python中,如果不是文本文件,则统一被认为是二进制文件,以“b”开头;
def is_gif(fname) f = open(, 'br') first4 = tuple(f.read(4)) return first4 == (0x47, 0x49, 0x46, 0x38)
检查开启的文件是不是图像文件,就检查二进制开始的文件开头是不是(0x47,0x49,0x46,0x38)这四个字节;
在而Python中,两个十六进制数可以描述一个字节,这一点非常方便;
pickle
二进制的数据对于数据处理效率非常高,但是在高级语言中处理起来则非常困难,而pickle模块则是用来让你能够轻松的读写几乎任何数据结构,如下所示:
# picklefile.py import pickle def make_pickled_file(): grades = {'alan' : [4,8,10,10], 'tom':[7,7,7,8],'dan':[5,None,7,7],'may':[10,8,10,10]} outfile = open('grades.dat','wb') pickle.dump(grades, outfile) def get_pickled_data() infile = open('grades.dat', 'rb') grades = pickle.load(infile) return grades
基本上,你可以使用pickle.dump将数据结构存储到磁盘,以后再使用pickle.load从磁盘获取数据结构。如果需要存储二进制的数据,可以考虑这种方式。
7、读取网页
Python为范文网络提供了强大的支持。一种常见任务是让程序自动读取网页,而是用模块 urllib 可轻松的完成这种任务;

这里的就和我们去http://python.org网站的源代码相同:

另外一个绝妙的模块是webbrowser,他让你能够以编程的方式流量器中显示网页。
例如:

这样就能指定打开流量器:
