分组查询的group by 是将你所有的类别分类好后再按照这个去查找,类似于先过了一遍distinct


# 添加分组查询 SELECT COUNT(first_name), `gender` FROM `employees` WHERE first_name LIKE '%a%' GROUP BY gender; # 添加分组后的筛选 having # 1. 查询每个工种有奖金的员工的最高工资>12000的工种编号和最高工资 # 1.1 分组查询每个工种有奖金的员工的最高工资和工种编号 这里的筛选条件用where # 1.2 将得出的结果经过条件-》大于12000 这里的筛选用having
2.筛选条件在原始表中有的(分组前)在group by前用where,在原始表没有的(分组后)在 group by后用having,例如
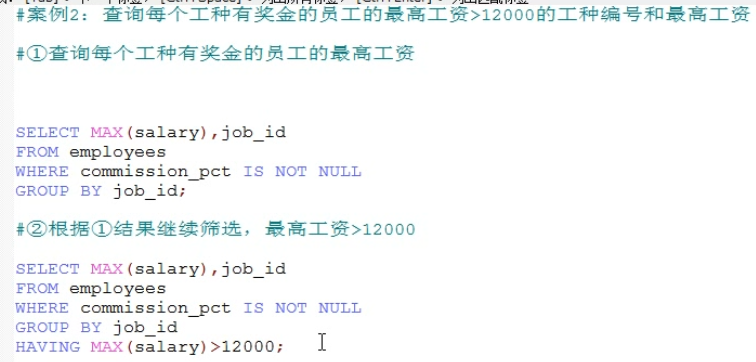
SELECT COUNT(*),LENGTH(last_name) AS len_name FROM employees GROUP BY len_name HAVING COUNT(*)>2000;
二: 连接查询 -> 多表查询
如果连续查询两张表,因为里面的id不同,所以可能会出现笛卡尔积的错误(所有表完全连接)因为没有加任何连接条件
笛卡尔乘积现象:表1有m行,表2有n行,查出来的数据有n*m行,里面数据全连接(相当于全连接层)。
解决:加上条件比如 表1有一列数据是表2的id,就可以用 where 表1.表2ID = 表2.id
起别名: 为表起别名,可以在from里面起,用as或者空格,注意MySQL执行顺序为先执行from里面的,为表起了别名后,查询字段就不能用原来的表去限定
分类:
按年代分类,
sql92标准(仅仅支持内连接)
sql99标准(推荐)
按照功能分类
内连接:
等值连接: 表1有一列数据是表2的id,就可以用 where 表1.表2ID = 表2.id ;还可以用and加筛选条件,不同的筛选条件
SELECT departments.dept_name, dept_manager.`from_date` FROM departments, dept_manager WHERE departments.`dept_no`=dept_manager.`dept_no`;
SELECT departments.dept_name, dept_manager.`from_date` FROM departments, dept_manager WHERE departments.`dept_no`=dept_manager.`dept_no` AND LENGTH(dept_name)>3;
非等值连接:例如用表A的salary 去通过判断表B的min和max就可以得到表A中每个工资对应表B里面的级别。
select A.salary, B.jibie from A,B where A.salary between B.max and B.min
自连接:例如查询员工名和上级的名称,由于上级也是员工,都在同一张表内,所以我们就可以使用自引用
SELECT 员工.名字,上级.名字 FROM 表1 as 员工,表2 as 上级 WHERE 表1.上级ID=表2.ID
外连接:
左外连接·
右外连接
全外连接
交叉连接