一。引用计数算法
比较古老的回收算法。原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。
垃圾回收时,只用收集计数为0的对象。此算法最致命的是无法处理循环引用的问题。
两种实现方式
侵入式与非侵入性,引用计数算法的垃圾收集一般有侵入式与非侵入式两种,侵入式的实现就是将引用计数器直接根植在对象内部,用C++的思想进行解释就是,在对象的构造或者拷贝构造中进行加一操作,在对象的析构中进行减一操作,非侵入式恩想就是有一块单独的内存区域,用作引用计数器
图解说明如下:
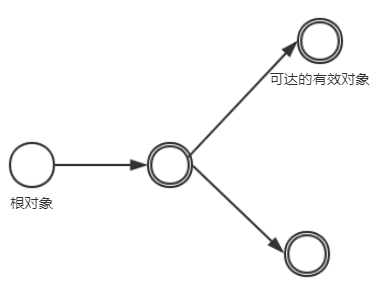

二。根搜索算法
定义:根搜索方法是通过一些“GC Roots”对象作为起点,从这些节点开始往下搜索,搜索通过的路径成为引用链(Reference Chain),当一个对象没有被GC Roots的引用链连接的时候,说明这个对象是不可用的,这样的对象被判定为是可回收的。
java中可以作为GC Roots对象包括以下几种:
1.虚拟机栈(栈帧中的本地变量表)中的引用对象。
2.方法区中的类静态属性引用的对象。
3.方法区中的常量引用的对象。
4.本地方法栈中JNI(也即一般说的Native方法)的引用的对象。
根搜索算法判断对象是否存活与引用有关。java将引用分为四类:强引用、软引用、弱引用、虚引用,这四种引用强度依次逐步减弱。
强引用:就是我们一般声明对象是时虚拟机生成的引用,强引用环境下,垃圾回收时需要严格判断当前对象是否被强引用,如果被强引用,则不会被垃圾回收。
软引用:软引用一般被做为缓存来使用。与强引用的区别是,软引用在垃圾回收时,虚拟机会根据当前系统的剩余内存来决定是否对软引用进行回收。如果剩余内存比较紧张,则虚拟机会回收软引用所引用的空间;如果剩余内存相对富裕,则不会进行回收。换句话说,虚拟机在发生OutOfMemory时,肯定是没有软引用存在的。
弱引用:弱引用与软引用类似,都是作为缓存来使用。但与软引用不同,弱引用在进行垃圾回收时,是一定会被回收掉的,因此其生命周期只存在于一个垃圾回收周期内。
虚引用:与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。它不能单独使用,必须和引用队列联合使用。虚引用的主要作用是跟踪对象被垃圾回收的状态。
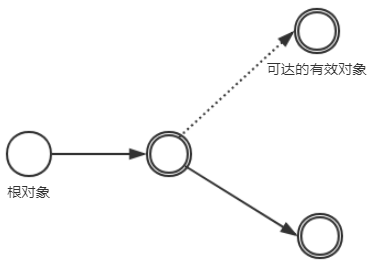
图解说明如下所示:

具体解析:
根搜索算法中不可达的对象并非“非死不可”,这时候它们暂时处于“缓刑”阶段,真正宣告一个对象死亡,至少要经历两次标记过程。如果通过根搜索后发现没有与GC Roots相连的引用链相连。它将会被第一次标记并且会进行筛选,当对象没有覆盖finalize()方法,或者finalize()方法已经被虚拟机调用过,虚拟机将这两种情况都视为没有必要执行finalize()方法。
如果这个对象被判定为有必要执行finalize()方法,那么这个对象将会被放置在一个名为F-Queue的队列之中,并在稍后有一条虚拟机自动建立、低优先级的 finalize的线程去执行。虚拟机会触发finalize()方法,但并不承诺等待它执行结束。finalize()方法是对象逃脱死亡的最后一次F-Queue中的对象机会。GC将会对F-QUEUEF-Queue中的对象进行第二次小规模的标记,如果某个对象重新与GC Roots引用链上的对象建立关联关系,那么第二次标记时它将被移除F-Queue。
任何一个对象的finalize()方法都只会被系统自动调用一次,如果对象面临下一次回收,它的finalize()方法不会被再次执行。
三。标记-清除算法
定义:标记清除算法是最基础的收集算法,其他收集算法都是基于这种思想。标记清除算法分为“标记”和“清除”两个阶段:首先标记出需要回收的对象,标记完成之后统一清除对象。
算法过程:
标记-清除算法是现代垃圾回收算法的思想基础。标记-清除算法将垃圾回收分为两个阶段:
标记阶段和清除阶段。一种可行的实现是,在标记阶段,首先通过根节点,标记所有从根节点开始的可达对象。
因此,未被标记的对象就是未被引用的垃圾对象;然后,在清除阶段,清除所有未被标记的对象。
图解说明一下:




标记-清除算法详解:
它的做法是当堆中的有效内存空间(available memory)被耗尽的时候,就会停止整个程序(也被成为stop the world),然后进行两项工作,第一项则是标记,第二项则是清除。
-
- 标记:标记的过程其实就是,遍历所有的GC Roots,然后将所有GC Roots可达的对象标记为存活的对象。
- 清除:清除的过程将遍历堆中所有的对象,将没有标记的对象全部清除掉。
也就是说,就是当程序运行期间,若可以使用的内存被耗尽的时候,GC线程就会被触发并将程序暂停,随后将依旧存活的对象标记一遍,最终再将堆中所有没被标记的对象全部清除掉,接下来便让程序恢复运行。
标记-清除算法的缺点:
(1)效率低:效率比较低(递归与全堆对象遍历),导致stop the world的时间比较长,尤其对于交互式的应用程序来说简直是无法接受。
(2)空间问题:这种方式清理出来的空闲内存是不连续的,这点不难理解,我们的死亡对象都是随即的出现在内存的各个角落的,现在把它们清除之后,内存的布局自然会乱七八糟。而为了应付这一点,JVM就不得不维持一个内存的空闲列表,这又是一种开销。而且在分配数组对象的时候,寻找连续的内存空间会不太好找。
四。复制算法
将内存平均分成A、B两块,算法过程:

- 标记:它的第一个阶段与标记/清除算法是一模一样的,均是遍历GC Roots,然后将存活的对象标记。
- 整理:移动所有存活的对象,且按照内存地址次序依次排列,然后将末端内存地址以后的内存全部回收。因此,第二阶段才称为整理阶段。
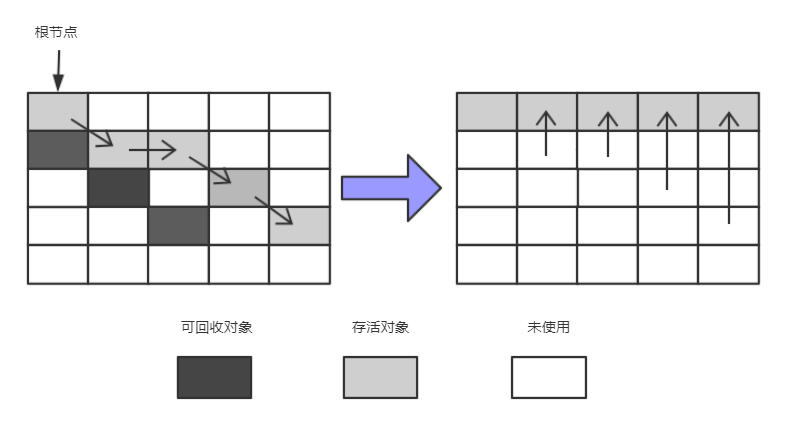
上图中可以看到,标记的存活对象将会被整理,按照内存地址依次排列,而未被标记的内存会被清理掉。如此一来,当我们需要给新对象分配内存时,JVM只需要持有一个内存的起始地址即可,这比维护一个空闲列表显然少了许多开销。
标记/整理算法不仅可以弥补标记/清除算法当中,内存区域分散的缺点,也消除了复制算法当中,内存减半的高额代价。
- 但是,标记/整理算法唯一的缺点就是效率也不高。
不仅要标记所有存活对象,还要整理所有存活对象的引用地址。从效率上来说,标记/整理算法要低于复制算法。(具体效果,需要根据实际情况而定)
六。分代收集算法
当前商业虚拟机的GC都是采用的“分代收集算法”,这并不是什么新的思想,只是根据对象的存活周期的不同将内存划分为几块儿。一般是把Java堆分为新生代和老年代:短命对象归为新生代,长命对象归为老年代。
- 新生代: 所有新生成的对象首先都是放在年轻代的。年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象。年轻代分三个区。一个Eden区,两个Survivor区(一般而言)。大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当这个Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当这个Survivor去也满了的时候,从第一个Survivor区复制过来的并且此时还存活的对象,将被复制“年老区(Tenured)”。需要注意,Survivor的两个区是对称的,没先后关系,所以同一个区中可能同时存在从Eden复制过来 对象,和从前一个Survivor复制过来的对象,而复制到年老区的只有从第一个Survivor去过来的对象。而且,Survivor区总有一个是空的。同时,根据程序需要,Survivor区是可以配置为多个的(多于两个),这样可以增加对象在年轻代中的存在时间,减少被放到年老代的可能。
- 老年代:大量对象存活,适合用标记-清理/标记-整理;因为对象存活率高、没有额外空间对他进行分配担保,就必须使用“标记-清理”/“标记-整理”算法进行GC。
- 持久代:基本固定不变,用于存放静态文件,例如Java类和方法。持久代对GC没有显著的影响。持久代可以通过-XX:MaxPermSize=<N>进行设置。

注:老年代的对象中,有一小部分是因为在新生代回收时,老年代做担保,进来的对象;绝大部分对象是因为很多次GC都没有被回收掉而进入老年代。
七。串行收集(拓展)
串行收集使用单线程处理所有垃圾回收工作,因为无需多线程交互,实现容易,而且效率比较高。但是,其局限性也比较明显,即无法使用多处理器的优势,所以此收集适合单处理器机器。当然,此收集器也可以用在小数据量(100M左右)情况下的多处理器机器上。
八。并行收集(拓展)
并行收集使用多线程处理垃圾回收工作,因而速度快,效率高。而且理论上CPU数目越多,越能体现出并行收集器的优势。
九。并发收集(拓展)
相对于串行收集和并行收集而言,前面两个在进行垃圾回收工作时,需要暂停整个运行环境,而只有垃圾回收程序在运行,因此,系统在垃圾回收时会有明显的暂停,而且暂停时间会因为堆越大而越长。