转自:https://baike.baidu.com/item/RPKM/1197657
均反应基因的表达水平
1.RPKM的计算公式

分母是总共比对到这个基因的reads的数目(条 为单位),分母是:比对上的reads的总数(百万条为单位);外显子的长度也就是基因的长度(KB为单位)。
2.举个计算的例子

3.为什么需要这样计算呢?
Reads Per Kilobase of exon model per Million mapped reads
具体含义是:每百万reads中来自于某基因每千碱基长度的reads数。
若是单纯以map到的read数来计算基因的表达量,在统计上是不合理的。
因为在随机抽样的情况下,序列较长的基因被抽到的机率本来就会比序列短的基因较高,如此一来,序列长的基因永远会被认为表达量较高,而错估基因真正的表现量。
4.FPKM计算公式
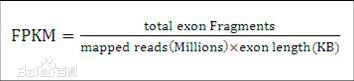
含义: FPKM代表每千个碱基的转录每百万映射读取的碎片。
两者就是分子不同,RPKM分子是reads,FPKM分子是fragment。
5. reads与fragment的区别
转自:https://www.cnblogs.com/jinhh/p/8964790.html
Reads即是指下机后fastq数据中的每一条Reads,Fragments则是指每一段用于测序的核酸片段,在SE中,一个Fragments只测一条Reads,所以,Reads数与Fragments数目相等;在PE中,一个Fragments测两端,会得到2条Reads,但由于后期质量或比对的过滤,有可能一个Fragments的2条Reads最后只有一条进入最后的表达量分析。总之,对某一对Reads而言,这2条Reads只能算一个Fragments.
转自:http://www.oebiotech.com/Article/jdcxzdcymc.html
Fragments:就是打成的片段,而测序测的就是这些fragments, 测出来的结果就是reads,又可以分为单端测序和双端测序,单端测序的话,只是从fragments的一端测序,测多长read就多长,双端测序就是从一个fragments的两端测,就会得出两个reads。
8.FPKM:将RPKM中的read换成freagment来理解。如果是single-end测序,二者FPKM和RPKM是一致的。如果是pair-end测序,每个fragments会有两个reads,FPKM只计算两个reads能比对到同一个转录本的fragments数量,而RPKM计算的是可以比对到转录本的reads数量。