转自:https://murphypei.github.io/blog/2019/08/socket-ready
https://blog.csdn.net/kyang_823/article/details/79496303
0.socket缓冲区
https://blog.csdn.net/tantion/article/details/86502529
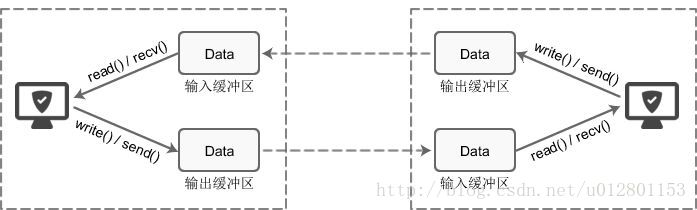
数据的发送和接收是独立的,并不是发送方执行一次send,接收方就执行以此recv。recv函数不管发送几次,都会从输入缓冲区尽可能多的获取数据。如果发送方发送了多次信息,接收方没来得及进行recv,则数据堆积在输入缓冲区中,取数据的时候会都取出来。换句话说,recv并不能判断数据包的结束位置。
send函数:
在数据进行发送的时候,需要先检查输出缓冲区的可用空间大小,如果可用空间大小小于要发送的数据长度,则send会被阻塞,直到缓冲区中的数据被发送到目标主机(内核缓冲区对应数据删掉,有了空间后),有了足够的空间之后,send函数才会将数据写入输出缓冲区。
TCP协议正在将数据发送到网络上的时候,输出缓冲区会被锁定(生产者消费者问题),不允许写入,send函数会被阻塞,直到数据发送完,输出缓冲区解锁,此时send才能将数据写入到输出缓冲区。
要写入的数据大于输出缓冲区的最大长度的时候,要分多次写入,直到所有数据都被写到缓冲区之后,send函数才会返回。
recv函数:
函数先检查输入缓冲区,如果输入缓冲区中有数据,读取出缓冲区中的数据,否则的话,recv函数会被阻塞,等待网络上传来数据。如果读取的数据长度小于输出缓冲区中的数据长度,没法一次性将所有数据读出来,需要多次执行recv函数,才能将数据读取完毕。
1.准备好读
引用《Unix网络编程》中的解释:
当满足下列条件之一时,一个套接字准备好读:
- 该套接字接收缓冲区中的数据字节数大于等于套接字接收缓冲区低水位标记的当前大小。对这样的套接字执行读操作不会阻塞并将返回一个大于 0 的值(也就是返回准备好读入的数据)。我们可以使用
SO_RCVLOWAT套接字选项设置该套接字的低水位标记。对于 TCP 和 UDP 套接字而言,其默认值为 1,这意味着,默认情况下,只要缓冲区中有数据,那就是可读的。 - 该连接的读半部关闭(也就是接收了 FIN 的 TCP 连接)。对这样的套接字的读操作将不阻塞并返回 0 (也就是返回 EOF)。
- 该套接字是一个监听套接字且已完成的连接数不为 0。对这样的套接字的 accept 通常不会阻塞。
- 其上有一个套接字错误待处理。对这样的套接字的读操作将不阻塞并返回 -1(也就是返回一个错误),同时把
errno设置成确切的错误条件。这些待处理错误也可以通过指定SO_ERROR套接字选项调用getsockopt获取并清除。
2.准备好写
当满足下列条件之一时,一个套接字准备好写:
- 该套接字发送缓冲区中的可用空间字节数大于等于套接字发送缓冲区低水位标记的当前大小,并且要求该套接字已连接(TCP)或者不需要连接(UDP)。这意味着如果我们把这样的套接字设置为非阻塞,写操作将不阻塞并返回一个正值(例如由传输层接收的字节数)。我们可以使用
SO_SNDLOWAT套接字选项来设置该套接字的低水位标记。对于 TCP 和 UDP 套接字而言,其默认值通常为 2048,送缓冲区默认大小为8K,这意味着,默认情况下,一个套接字连接成功后,总是可写的。(至少需要2k的空闲空间才能写,send才不会阻塞)【为什么不会阻塞?写操作调用send从用户缓冲区发送到内核缓冲区,这个复制的过程不会阻塞吗?难道不是小于等于的时候直接写入用户缓冲区,这个过程不会阻塞吗?关于这个问题,本人目前认为,send调用后只要有>2k的空间就可以返回写入的字节数,然后后续由用户复制到内核这个过程不需要阻塞,自动完成就好了。】 - 该连接的写半部关闭,对这样的套接字的写操作将产生
SIGPIPE信号。 - 使用非阻塞式
connect的套接字已建立连接,或者已经以失败告终。 - 其上有一个套接字错误待处理。对这样的套接字的写操作将不阻塞并返回 -1(也就是返回一个错误),同时把
errno设置成确切的错误条件。这些待处理的错误也可以通过指定SO_ERROR套接字选项调用getsockopt获取并清除。
//针对第一条有疑问,发送缓冲区是将数据send到内核缓冲区,那么这个过程为什么不会阻塞呢?有系统调用的吧?需要具体理解send socket的过程,
【目前的理解是,写操作不会阻塞,只是说明发送区有数据发送,而无需等待数据。】
【居然看错了,第一条说的是发送缓冲区中可用空间字节数,而不是已存字节数。这是为了保证应用程序输出的数据能写到发送缓冲区,然后send返回,之后再系统调用写到内核缓冲区吧,只要发送有空间,内核那边应该没问题,或者是有回调告诉内核还剩多少空间。】
3.理解
https://blog.csdn.net/majianfei1023/article/details/45788591
通俗的解释一下,缓存区我们当成一个大小为 n bytes的空间,那么:
- 接收区缓存的作用就是,接收对面的数据放在缓存区,供应用程序读。当然了,只有当缓存区可读的数据量(接收低水位标记)到达一定程度(eg:1)的时候,我们才能读到数据,不然不就读不到数据了吗。
- 发送区缓存的作用就是,发送应用程序的数据到缓存区,然后一起发给对面。当然了,只有当缓存区剩余一定空间(发送低水位标记)(eg:2048),你才能写数据进去,不然可能导致空间不够。
4.接收缓存区低水位标记(用于读)和发送缓存区低水位标记(用于写):
https://blog.csdn.net/kyang_823/article/details/79496303
接收低水位标记和发送低水位标记:允许应用进程控制在select返回可读、可写时有多少数据可读、有多大空间可用于写。
接收低水位标记:让select返回”可读”时套接字接收缓冲区中所需的最少数据量。对于TCP,其默认值为1。【只要有一个就可以处于读就绪】
发送低水位标记:让select返回”可写”时套接字发送缓冲区中所需的最少可用空间。对于TCP,其默认值常为2048。【只要有2048空闲就可以处于写就绪】
接收低水位标记例子:若应用进程需要至少64个字节,否则无法有效工作,那就可以将接收低水位标记设为64,以防select在低于64字节时仍然唤醒该进程。