1.介绍
https://blog.csdn.net/qq_25737169/article/details/79048516
Batchnorm是深度网络中经常用到的加速神经网络训练,加速收敛速度及稳定性的算法。
在训练模型时,学习的是数据集的分布,但是如果每一个批次batch分布不同,那么就会给训练带来困难;
另一方面,数据经过一层层网络计算后,其数据分布也在发生着变化,此现象称为Internal covariant shift,会给下一层的网络学习带来困难。
1.1 Internal covariant shift 内部协变量偏移
即:每一次参数迭代更新后,上一层网络的输出数据经过这一层网络计算后,数据的分布会发生变化,为下一层网络的学习带来困难。
covariant shift描述的是训练数据和测试数据存在分布的差异性,给网络的泛化性和训练速度带来了影响。
//链接中有个图讲的很好,经过数据归一化,就能加快训练速度,因为b一般初始化为0?
2.原理

对每一层的输出后的数据做归一化,加入可训练的参数做归一化,其实过程非常简单。
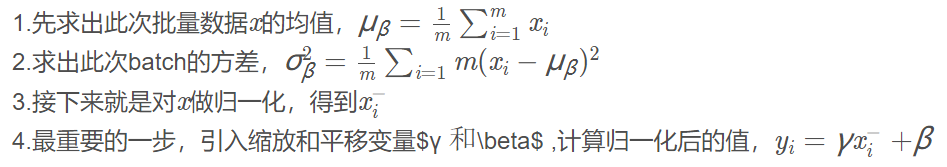
β是平移参数,γ是缩放参数。如果γ=σ,β=μ参数,那么y就取消了归一化。所以,综上保证了每一次数据经过归一化后还保留的有学习来的特征,同时又能完成归一化这个操作,加速训练。
3.代码
def Batchnorm_simple_for_train(x, gamma, beta, bn_param): """ param:x : 输入数据,设shape(B,L) param:gama : 缩放因子 γ param:beta : 平移因子 β param:bn_param : batchnorm所需要的一些参数 eps : 接近0的数,防止分母出现0 momentum : 动量参数,一般为0.9, 0.99, 0.999 running_mean :滑动平均的方式计算新的均值,训练时计算,为测试数据做准备 running_var : 滑动平均的方式计算新的方差,训练时计算,为测试数据做准备 """ running_mean = bn_param['running_mean'] #shape = [B] running_var = bn_param['running_var'] #shape = [B] results = 0. # 建立一个新的变量 x_mean=x.mean(axis=0) # 计算x的均值 x_var=x.var(axis=0) # 计算方差 x_normalized=(x-x_mean)/np.sqrt(x_var+eps) # 归一化 results = gamma * x_normalized + beta # 缩放平移 running_mean = momentum * running_mean + (1 - momentum) * x_mean running_var = momentum * running_var + (1 - momentum) * x_var #记录新的值 bn_param['running_mean'] = running_mean bn_param['running_var'] = running_var return results , bn_param
其实上述running_mean和var在训练过程中没有用到,主要作用是在测试集的时候用到,因为测试集它是针对一个样本,不存在均值。
在训练过程中,是直接取running_mean和running_var的,
4.BatchNorm1d用法
https://pytorch.org/docs/stable/nn.html
https://blog.csdn.net/qsmx666/article/details/109527726

- num_features – 特征维度
- eps – 为数值稳定性而加到分母上的值。
- momentum – 移动平均的动量值。
- affine – 一个布尔值,当设置为真时,此模块具有可学习的仿射参数。
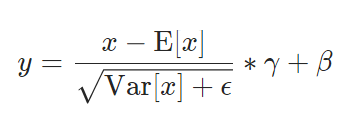
其中γ默认为1,β默认为0,并且x是特征,不是样本。。从下面的例子中可以看出:

import torch.nn as nn
import torch
m = nn.BatchNorm1d(3)
input = torch.randn(2, 3)
output = m(input)
#输出
>>> output
tensor([[-0.9762, 0.3067, -0.5193],#做一个归一化
[ 0.9762, -0.3067, 0.5193]], grad_fn=<NativeBatchNormBackward>)