1.run_roberta 与run_bert?
我存在疑问的地方是, 跑roberta的话,就不能改一下run_bert.py然后跑起来吗???这样更加简便啊,不用更换什么代码。
但是却出现了:pytorch_transformers/modeling_bert.py:
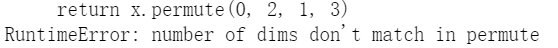
说明维度存在问题啊。
因为modeling_roberta也使用了modeling_bert里面的Bert基础类,所以出错是在modeling_bert里。
然后我看了一下最新的transform的更新,文件结构代码结构什么的有了变化,那我选择就是使用更新之后的来跑一下!应该可以的吧!
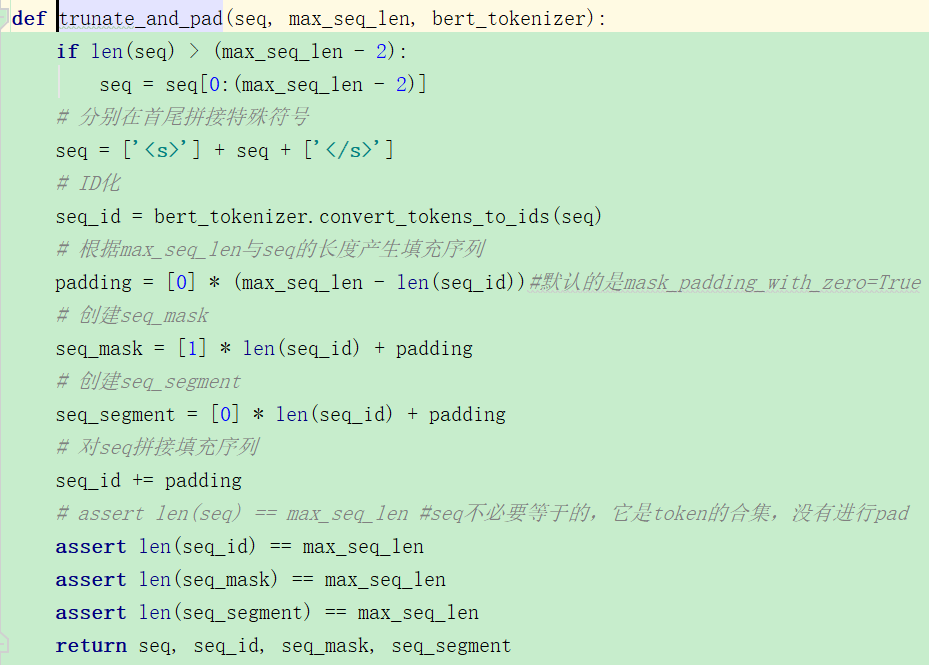
这个是处理bert的时候的输入特征,向量包括这些,那我需要弄明白roberta是否也是这样的? 但是我看了RobertaForSequenceClassification的参数,和BertForSequenceClassification都是一样的啊。
https://huggingface.co/transformers/pretrained_models.html,从这里下载的roberta-large内容如下:

看来是tf的吧,但是我需要的是torch版本的。
但是直觉上不应该出问题的啊。都是bert系的。还搜索了这个modeling_bert return x.permute(0, 2, 1, 3) number of dims don't match in permute。
完全没有找到什么有用的内容,我放弃这条路子了。
2. .git文件夹
.git文件夹下每个的作用,专业书籍教程!,这个就讲的很全面,但我还没有仔细看,先mark。
3.fatal: the remote end hung up unexpectedly fatal: index-pack failed error: RPC failed; curl 56 Send failure: Connection was reset
用GitHub 桌面版下载的时候遇到了这个bug,所以就是,https://stackoverflow.com/questions/6842687/the-remote-end-hung-up-unexpectedly-while-git-cloning
git config --global http.postBuffer 500M git config --global http.maxRequestBuffer 100M git config --global core.compression 0
用git bash跑一下上面的三句就ok的。
5-9日————————————
1.cannot use a string pattern on a bytes-like object
例子:
>>> a='abc名' >>> a.encode('ascii','ignore') b'abc' >>> a.encode('ascii','ignore').decode('ascii') 'abc' >>> a='abc名' >>> a.encode('ascii','ignore').decode('ascii') 'abc'
直接再编码回来就好了,就可以把中文去掉了!
5-10——————————————————
1.simpletransformers交叉验证
https://www.kaggle.com/szelee/simpletransformers-hyperparam-tuning-k-fold-cv,
这里有一个交叉验证的,但是和我的不太一样。
我需要解决的问题是,如何清除内存?
2.释放GPU显存
del和torch.cuda.empty_cache()
https://discuss.pytorch.org/t/how-can-we-release-gpu-memory-cache/14530/18,这里面提到,empty_cache会释放一些显存,但是如果有指向的话就不会释放,我也不太清楚。
https://stackoverflow.com/questions/53350905/pytorch-delete-model-from-gpu ,这个和我遇到了一样的问题,说是del model就可以,但是前提是没有指向这个模型的reference了,但是!我怎么去判断有没有reference了???这难道不是很迷惑吗?
https://discuss.pytorch.org/t/releasing-gpu-memory-after-deleting-model/48167,这里也遇到了问题,但是评论里说,是因为results = model(data)这句,

需要梯度的计算,而梯度又需要很多参数,所以还不能释放内存,但是我看了一下

已经detach了啊。

再尝试一下吧,感觉大概率是不行的。

还是失败,应该就是一个epoch结束了,但是之前的模型什么的都没有清除,所以出现了这个问题,现在我选择使用shell脚本来运行一下。
2.跑roberta教程
它也是建议使用simple的那个包,好吧。
3.TypeError: 'Namespace' object is not subscriptable
https://stackoverflow.com/questions/17934149/python-command-args,这里给出的办法是不用['']访问,而用.访问。
可以解决。
4.《RoBERTa:A Robustly Optimized BERT Pretraining Approach》
https://blog.csdn.net/ljp1919/article/details/100666563,强力优化的bert方法。
它拥有更大的参数量、训练数据量更大、batch_size更大。

mask翻译为掩码。
//这个文本编码BPE不太了解。
这个模型并没有在模型上有什么创新,而基本上都是训练时的技巧。有钱啊!