1.kaggle竞赛技巧
https://blog.csdn.net/wtq1993/article/details/51418958 讲的蛮不错!
EDA:(Exploratory Data Analysis)对数据进行探索性的分析,从而为之后的处理和建模提供必要的结论。
常见地画的图包括:label的图查看是否均衡、散点图查看坐标值是否有离群点,对于数值型地变量可以画箱线图。
预处理包括处理缺失值、离群值outliers。
一般需要五折交叉验证就可以了。
包括模型融合和模型Stacking ,后者我还不太理解是什么意思。。。
2.Glove和word2vec的区别
https://zhuanlan.zhihu.com/p/31023929 这个说的还比较间接
glove是基于基于上下文词计数矩阵的,对共现矩阵进行降维。
但知乎上有人说,glove的效果不好,而且复杂度更高?这点有待验证。
3.bert到底作用是啥?
我已经被各种博客给整晕了。难道我要去看bert的原论文了吗
bert的预训练模型都是什么?如果要从bert中获取词向量应该怎么做?
在对原论文的阅读中,逐渐解答了一些我之前心中的疑问:
①更加粗粒度的表示,包括句子和段落嵌入向量。细粒度的就是词和char吧。对于中文来说char就是单个字。这也就是为什么bert会有nsp任务了,以前一直不理解,也就是CLS表示的是整个句子的特征,更加粗粒度。
②BERT不仅在句子水平上,也在token水平上都获得了好的结果。句子级任务比如NSP、情感分类,token就比如NER吧。
③这个Masked LM就很像完形填空啊,整个的bert的预训练任务目标其中一部分就是这个,对mask掉的单词进行softmax,维度当然是vocab的维度,然后计算损失。终于理解了。
④这个pre-train就是为了学习到widely applicable representations of words。单词的广泛应用的表示。https://www.zhihu.com/question/324943987 大语料出奇迹。能够包含更多的信息吧!
⑤一旦预训练的模型学习到了,那么下游的任务所使用的模型初始化参数全都是一样的,之后再根据任务训练微调。
Each downstream task has sep-arate fine-tuned models, even though they are ini-tialized with the same pre-trained parameters.
⑥The final hidden state corresponding to this token [CLS] is used as the aggregate sequence representation for classification tasks.
最后一层的隐层的输出[CLS]作为一个能够整合整个句子的信息,表示整个句子,可以用来分类任务。
⑦它说到elmo模型之所以不用双向的,是因为它能够在上下文中看到自己?https://blog.csdn.net/ACM_hades/article/details/89375058 这里解释说是:因为双向条件语言模型将允许每个单词在多层self-attention中间接看到自己。我还不理解什么是多层自注意力,下面一个问题解决。总之就因为这个它提出了MLM。
4.多层自注意力机制是啥?
层叠注意力机制。
5.为什么bert的三个输入embedding可以相加?
https://www.zhihu.com/question/374835153
邱老师的解释真是高级,将文本视为不同波信息的叠加,在bert中就会给解耦出来。
另一个博主解释为:信息的交叉,交叉能够带来更为丰富的信息,能让上下文敏感。
下面这个解释也很有意思:
2020-3-28学习笔记————————————————
1.交叉验证kfold是如何进行的
我还是有一点不明白,如果将训练集不划分为训练和测试集,而是全部用来一次性实验,那么就不必要进行交叉验证了吧?
交叉验证就是为了防止 划分不均匀 产生的损失,但是现在我就没有划分为训练和测试集,哪里会来不均匀呢?
https://zhuanlan.zhihu.com/p/24825503 这个讲的还不错,我似乎终于理解了LOOCV和K-CV的区别了。。。这个博客里的评论也挺好的。
前者是每次只留一个样本做训练,计算速度太慢了,而后者是留一个set。
我还是不太明白,如果直接将train_set全都作为训练集,然后训练几个epoch,或者使用交叉验证来训练会有什么区别?并不一定第一个效果就是好的啊。
https://stackoverflow.com/questions/60567302/does-it-make-sense-to-do-cross-validation-when-fine-tuning-a-language-model-like 这个就有一个问题bert的微调用交叉验证是否有用?
回答里说,交叉验证主要是用来验证模型在unseen数据上的表现,所以可以用?
我现在关于交叉验证的疑问,如果每次都选择表现最好的那组交叉验证的模型保存起来,那很多博客说的取平均是怎么一回事?我一直认为的交叉验证都是在同一个模型上,而很明显这个每次交叉验证迭代都是一个全新的模型,就和上一次kfold学习到的参数完全无关?
我再找找其他的训练代码。。。
https://mc.ai/how-to-develop-a-convolutional-neural-network-from-scratch-for-mnist-handwritten-digit-classification/ 又看了好多,包括这个,我感觉emm每个人写的似乎都有所不同,那我还是根据最初的那个来写?假设是5折。
①每次model都用类新生成,不保留上一折训练的参数结果,本次训练后就对测试集预测输出,并对5次预测输出求和,之后再softmax做分类。
②每次model都用类新生成,不保留上一折训练的参数结果,本次训练后在验证集上计算损失,保留并更新损失最小的作为对预测集预测的模型,之后单独加载模型预测。
③每次model都一次定义,使用上次经过训练后的参数模型,只获取到在所有验证集上的损失,并且用唯一的这个model作为对预测集预测的模型,之后单独加载模型预测。
基本上是这三种吧,但是我不知道哪一种是有效的啊。好难!太难了吧!我该怎么办呢?去群里提问吗?
https://www.jianshu.com/p/f14826061612 我又看了这里面提及到的一些点,交叉验证只是为了验证比如说两个模型(神经网络和逻辑回归)哪个总体来说更好,而不是去得到某一个模型(如神经网络)的参数,用它只是在确定模型训练好后,去查看一下它的效果!原来是这样啊,我好像确实一直理解错了,它是只用来比较模型的!!!
https://stats.stackexchange.com/questions/52274/how-to-choose-a-predictive-model-after-k-fold-cross-validation 就是这些里面讲到的点,英文确实比中文更能get到point啊!!!
我好像彻底明白了!我就应该用全部的train_data去正常地训练模型,然后得到这个模型后,我就kfold ,k=5交叉验证,查看结果,这个结果我是可以记录下来的。
2020-5-1更新————————
https://blog.csdn.net/m0_38061927/article/details/76180541 这里面评论区提到:

我觉得说的很有道理哎,但是跟我之前的理解就产生了冲突啊,交叉验证不是只为了去比较模型吗?这里居然说是为了选出最优参数?这。。
但是如果我面试被问到交叉验证有什么用,我还是不能总结出个1234点,这种还是要看面经吗?虽然我有了一点理解,但让我去给出一个比较系统的答案我还是做不到,要直接叙述的话就感觉非常乱。愁!
2.BertTokenizer.from_pretrained('bert-base-chinese')如何实现的分词?
是以字粒度划分的!~

然后再split,简单粗暴~
3.通过config创建bert和from_pretrained一样吗?
用config怎么保证创建的bert是我想要的那个呢?这个config就是个json文件啊,那100多M的bert模型数据都存到什么地方了?我也没看到有下载的地方啊,我总觉得通过fromm_pretrained才是有效的啊?
对啊,我没看到下面还有这一句,只不过是提前下载好了,config当然也是已经预训练好的bert模型的对应的参数咯。

我还是不够仔细吧,不过其实峰回路转发现还是很简单的。
5.bert的vocab文件
下面是bert-base-chinese.tar.gz解压后的文件的内容,用于构建预训练模型。
而Tokenizer的构建需要词表,https://zhuanlan.zhihu.com/p/50773178
6.BertModel类中forward返回encoded_layers, pooled_output,意义分别是什么?
其实非常好理解,你就看

类里的描述就ok了,非常清楚,如果参数为True,那就返回所有隐层块的,而为False,就只会返回最后一层注意力块的,其实我觉得返回所有的没有必要吧,什么任务要求返回所有的呢?
对于token级别的任务来说,就False,然后用encoded_layers就可;对于句子级别分类任务,就可以只用pooled_output就ok了。
2020-3-29———————————————————————
8.CNN+LSTM和LSTM+CNN有什么区别呢?
针对情感分类,都有什么方法呢?
9.conv1d 对batch的sequence举例!
https://discuss.pytorch.org/t/understanding-convolution-1d-output-and-input/30764/3 这个里面举的例子还不错,我有了自己的理解。
import torch from torch import nn a = torch.randn(32, 100, 10) #假设a为[batch_size, sequence_length, emb_size] m = nn.Conv1d(100, 50, 2) #[input_channel,output_channel, kernel_size] out = m(a) print(out.size())#[batch_size,output_channel,计算公式(emb_size+2p-kernel_size)/s+1=10-2+1=9] print(m) #输出: torch.Size([32, 50, 9]) Conv1d(100, 50, kernel_size=(2,), stride=(1,))
所以在这个一维卷积的过程中,batch_size不会受影响,而seq_length就是输出通道数,卷积后的seq_length就是输出通道数,然后嵌入层的大小变化,适合kernel_size有关系的。
同时Number of filters = Number of out_channels. 也就是说,输出通道数,输出后的seq_length=output_channel。
从官方给的样例中,也能够看出来:https://pytorch.org/docs/stable/nn.html#torch.nn.Conv1d
import torch import torch.nn as nn # 神经网络模块 m = nn.Conv1d(16, 33, 3, stride=2) input = torch.randn(20, 16, 50) output = m(input) print(output.shape) #输出: torch.Size([20, 33, 24]) #输出通道是33哦。
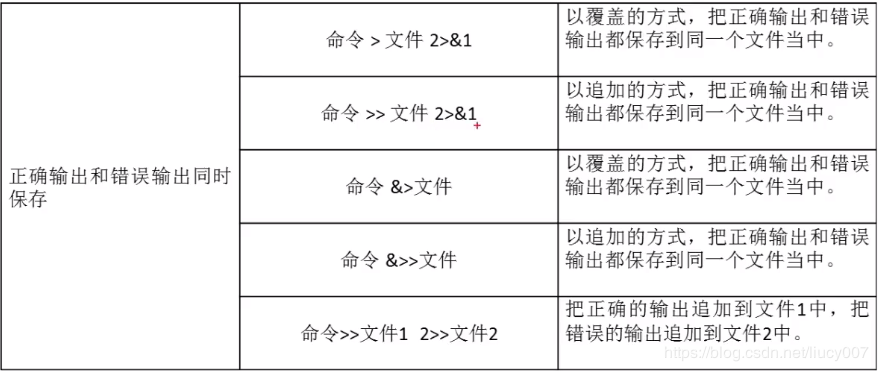
10.Linux重定向输出 2>&1
https://blog.csdn.net/liucy007/article/details/90207830 这样就重定向,这个讲的挺不错的。
11. Expected input batch_size (4) to match target batch_size (32).
The first thing running into a size mismatch error is to check your tensor shapes.
遇到size不对的,就检查tensor的shape!!!
还是不对,我觉得我应该没问题的啊,这是怎么回事?
由此我也发现了一个惊天大秘密啊!
import torch import torch.nn as nn # 神经网络模块 rnn = nn.LSTM(10, 20, 2,batch_first=True) input = torch.randn(3, 5, 10) h0 = torch.randn(2,3,20) c0 = torch.randn(2,3,20) output, (hn, cn) = rnn(input, (h0, c0)) print(output.size(),hn.size(),cn.size()) #输出: torch.Size([3, 5, 20]) torch.Size([2, 3, 20]) torch.Size([2, 3, 20]) #如果企图将h0的batch_size和num_layers*num_direction改为h0 = torch.randn(3,2,20)会报错: #RuntimeError: Expected hidden[0] size (2, 3, 20), got (3, 2, 20)
OMG!上面的就说明,batch_first=True只对output有影响,对hidden和cell完全没有影响啊,姜还是老的辣,我还是太嫩了点。
hidden的shape仍旧是[num_layers*num_direction, batch_size, emb_size]。
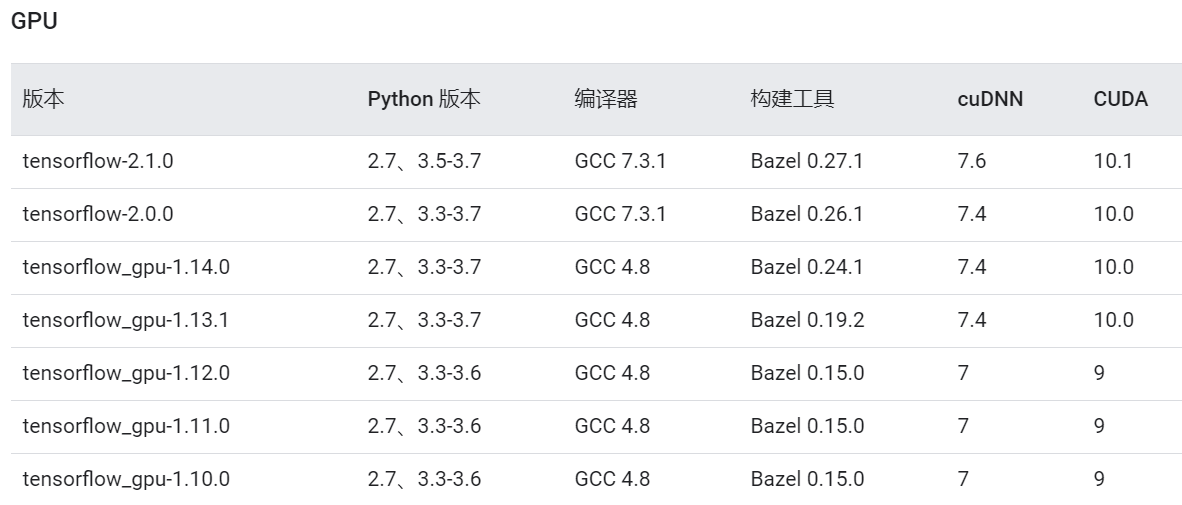
12.tf对应的cuda版本!tf原来有这些版本
https://www.tensorflow.org/install/source#common_installation_problems
13.安装tf1.14后出现:
FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
https://github.com/tensorflow/tensorflow/issues/30427 给的解释非常好,查看了我的numpy版本之后发现是1.18,就卸载,然后
pip install "numpy<1.17"
之后再导入tf就不会有这个warning了。
14.不能用GPU了???
>>> torch.cuda.is_available()
False
为啥不能用GPU了?????
难道是cuda10.0谁给我动了?真烦!!!之前不还好好的吗?操,又被环境搞死在这!
https://stackoverflow.com/questions/58595291/runtime-error-999-when-trying-to-use-cuda-with-pytorch
这里和我的问题一模一样,里面答案是说重启,我怎么可能重启我实验室的电脑呢,我又不在实验室,这风险太大了点。万一不行的话,我就再也打不开用不上了。。。风险太大,不行。
1.可能是我换环境的问题吗?
还是false,可咋整啊。。。
我又重新安装了pytorch1.4.0还是不行,还是false,我慌了,这可咋整。、
15。使用清华源安装朋友torch,非常快
conda config --remove-key channels 删除所有channel,
https://blog.csdn.net/zzq060143/article/details/88042075 就是这个讲的非常好。
windows端:https://blog.csdn.net/asdfg6541/article/details/104488926/ ,是有效的!变得快了不少。
16.cuda版本切换
https://blog.csdn.net/Maple2014/article/details/78574275
原来那个形成的是软连接啊!
#在切换cuda版本时 rm -rf /usr/local/cuda#删除之前创建的软链接 sudo ln -s /usr/local/cuda-8.0/ /usr/local/cuda/ nvcc --version #查看当前 cuda 版本 nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2016 NVIDIA Corporation Built on Mon_Jan_23_12:24:11_CST_2017 Cuda compilation tools, release 8.0, V8.0.62 #cuda8.0 切换到 cuda9.0 rm -rf /usr/local/cuda sudo ln -s /usr/local/cuda-9.0/ /usr/local/cuda/ nvcc --version
17.nvidia-smi和cuda版本不匹配
https://stackoverflow.com/questions/53422407/different-cuda-versions-shown-by-nvcc-and-nvidia-smi
这里的大体意思是说,前者是在安装驱动的时候安的,然后cuda一般是由conda安的,但是真正运行时的cuda是由nvcc -V来确定的,两者不match,并没有什么影响。
排除了是这个方面的问题。
18.尝试了deviceQuery检查
果然不仅是torch的问题啊,是cuda整个的问题,早知道我就不用卸载torch然后安装,那么麻烦了。哭。
https://blog.csdn.net/qq_33200967/article/details/80689543
cd /usr/local/cuda-10.0/samples/1_Utilities/deviceQuery
make
./deviceQuery
用来测试是否安装成功,果然没有安装成功,总算是有一点点眉目了。
./deviceQuery Starting... CUDA Device Query (Runtime API) version (CUDART static linking) cudaGetDeviceCount returned 30 -> unknown error Result = FAIL
我还没有遇到过这个问题吧,真可怕啊。